小町 祐史
松下電送システム(株)
文書技術の発達は, しばしば"紙から電子へ"というキーワードによって表現される。文書を人の思いやことばを時間的に固定したものととらえるとき, それは, 文字と, 図・表などの関連表現手段との集合(文書情報)として構成され, これまで紙というサブストレートの上に固定されることがほとんどであった。この場合, 紙は文書情報の(1)記憶と(2)表示の機能を兼ねると共に, 文書情報をのせた紙を移動することによって(3)交換の機能をも果している。特に(1),(2)は, エネルギ供給に関して受動的に実行されるという優れた性質をもつため, 今後とも広く利用されることは間違いない。
しかし, 利便性の向上と環境保全という2大ユーザ要求の充足をめざして, 文書の電子化は推進されてきた。まず文書の生成過程に電子的な手段が導入され, 幾つもの過程での電子化情報の形態をとる文書が成立し, その結果, 電子化文書の交換と記憶が容易になり, 電子的な交換・流通形態をとる出版が電子出版と呼ばれるようになった。ここでは, この段階を第1世代の電子化と呼ぶことにする。
文書の電子化によって, 文書情報とそれを記憶したり交換したりする媒体とを分離して扱うことが容易になり, さらに文書の論理構造と, それを読者に理解し易く表すためのフォーマットとを分離して扱うことが明示的になったことは, この段階における文書の電子化に伴う大きな成果であった。文書が電子的な交換の対象となったことにより, 文書情報の標準化の必要性が指摘され, 国際と国内の多くの標準化組織がその検討を開始した。
電子化された文書は, それだけに止まらず, Internetの発達とともにWeb環境に大量に分散蓄積されることとなった。それらの多くは, ディスプレイを含むコンピュータによって表示されることを前提として, 動画像や音声までをもコンテントの一部として取り込んだマルチメディア文書となり, 互いにハイパリンクで結ばれたハイパメディア文書となった。ここではこれを, 第2世代の電子化と呼ぶ。
ネットワークを介して大量の文書に容易にアクセスできる環境が普及すると, 文書は人が閲覧するためだけのものに止まらず, 検索ロボットのようなマシンもが扱えるもの(document-like object)とか, 閲覧者の対話的介入によってその内容を変化させる対話形文書へと変貌を余儀なくされている。これが, ここでいう第3世代の電子化である。
このような文書の電子化に伴う文書の変化を概観し, 主要なトピックを紹介して, 今後の動向を展望する。
生成過程は,電子化された情報処理がそこに介在するか否かにかかわらず,概ね次の段階に区分される。各段階で得られる文書は,次の段階に受渡す必要があり,これまでも当事者間での合意に基づく受け渡しが行われていた。
著者が文書によって表現したい主要情報の作成。原稿用紙への文字の書込み,イラスト書き,図示対象の写真撮影など。
文書内容を理解しやすくするための,情報の論理的構造化(論理的要素の抽出と構造的配置)。本文から脚注,備考などを分離し,段落に区切って見出しをつけることなど。
ここで(1)と(2)は主として著者が担当し,この順序に実行する作業過程である。しかし場合によっては作業順序が逆になり,構造を規定する枠が与えられて,そこに著者が内容を書込むこともある。
文書構造を把握しやすくすると共に,内容情報の可読性を向上させるために,論理的要素に物理的な配置・体裁を指定する。見出しを左上に置いてゴシック書体で印字し,それに続けて本文を2段組みで明朝書体によって印字するなどの指定。
これは通常,編集者が印刷業者に対して指示する作業である。
フォーマット指定に従って文書を構成する論理的要素を配置すること。以前は活字を組む職人の作業であったが,今ではフォーマタ(例えばTEX)と呼ばれる処理系が実行することが多い。
フォーマット指定に従って配置された文書構成要素の集まりをある程度レビューできるように可視化したゲラ刷りなどを,(1),(2),(3)の作業担当者(著者,編集者)にフィードバックして,それぞれのレビューを受ける。
最終的なフォーマティング結果を紙面などに可視化すること。印刷業者によって実行されることが多い。
これらの(1)-(6)の作業は通常,それぞれの作業場所で異なる作業者によって実行される。つまり空間的,時間的に分散した環境で文書は生成される。各作業の効率化のために導入された電子化処理に伴い,それぞれの段階の電子化情報が伝送の対象となり,その受渡しを行う範囲を広げるために標準的な文書情報交換様式(document information interchange format)の検討が行われてきた。
タイプセティング(植字) は,文書処理の中でかなり早くから電子化が検討され,電子化植字装置の製品が作成された。そこでは,文書の文字列中に,タイプセッタ(植字機)用の命令コードが書込まれる(図3.1参照)。この命令コードを植字機が解釈し,フォーマティングを実行して,印刷出力を行う。
命令コードは機器に依存していたため,この命令コードを含む文書の交換はかなり限定される。命令は印刷技術に関する指定が多く,命令コードの書込みには印刷の専門技術を必要とした。
<fm12><pr20><ch123> 政治対話の強調
<fm11><pr16><ch112> ロンドンで開かれていたアジア欧州会議は・・・・
図3.1 タイプセッタ用命令コードを含む文書情報の例
文書中に直接,印刷技術に関連する命令を書くのではなく,文書を構成する論理的要素を示すマーク付け(図3.2参照)が行われるようになり,次の利点がクローズアップされた。
<見出し> 政治対話の強調
<段落> ロンドンで開かれていたアジア欧州会議は・・・・
図3.2 論理構造のマーク付けを施した文書情報の例
このような論理構造のマーク付けの結果,タグを印刷用の命令コードに対応付けして,それを実行するシステム,つまりフォーマタが必要になる。ここに至って,文書の論理構造を扱う系とフォーマタとが明確に分離された(注1参照)。
[注1]: 通常のワードプロセッサは,文書の論理構造を扱う系とフォーマタとの分離を行っていない。文書内容をキー入力しながら,字下げ用スペースなどのフォーマット指定用のキー入力も行う。これがワードプロセッサの操作を複雑にすると共に,異機種で作成された文書データの交換を困難にしている。異機種ワードプロセッサ間のデータ交換に際しては,結局フォーマット情報を除去したプレーンテキストを交換の対象にすることが多い。
マーク付けはさらに,ある文書クラスの論理的要素を共通に識別するようなタグ集合へと一般化され,共通マーク付け(generic markup)呼ばれた。要素に関する属性記述をもタグに含めて,多様なアプリケーションに対応できるようにしたマーク付けも行われ,一般化マーク付け(generalized markup)[文献1)]となった。
このようなタグ集合の定義方法を国際的に取り決め,言語として体系付けたものが ISO(国際標準化機構)によって承認され,標準一般化マーク付け言語(Standard Generaaalized Markup Language, SGML)[文献2)]として制定された。これによって,さまざまなタイプの文書やアプリケーションに対して,一般化マーク付けを定義でき,さらに各種の補助機能によってさらに利便性の向上が図られている。
文書交換は文書を構成する論理的要素とその構造だけで充分というわけではない。表示機能を大きく異にする装置間の文書交換では,フォーマット情報はローカルに設定しなくてはならないため,交換の対象は論理的要素に限定されるが,充分なフォーマティング機能と表示機能をもつ環境では,再編集の可能性を維持したまま交換による版面の一致または最適近似が要求されることが多い。そこで文書の論理的要素の情報とそれに対するフォーマット指定情報とが交換の対象となった。
フォーマティングは, カットシートとか本とかのページ上の制約(注2参照)の中に, 文書を構成する論理的要素等を読み易くマッピングすることである。この制約には, 次に例示するような版面の制約と記述内容の意味的制約とがある。
[注2] 最近の電子化文書では, ディスプレイ画面における制約になる場合がある。
フォーマティングの実行は, 定式化されたこれらの制約のもとで解を求めるという問題に帰着するが, 制約が厳しすぎると解がないこともあり, その場合には制約を緩和するための調停ルールを導入する必要がある。
ページものに関するフォーマティングルールは, 出版・印刷業界で長い年月をかけて蓄積されたものが既に存在し, ハウスルールとして運用されることが多い。電子化環境への適用も次第に進みつつある。
フォーマット情報に従ってフォーマットされた文書は,各種のプリンタやディスプレイによって表示される。それらの表示機能は多様であるため,表示機能に依存しないフォーマット済み文書情報が望まれる。この情報はプリンタやディスプレイの表示機能に応じた処理によって可視化される。
図形文字を含むフォーマティングや可視化処理では,図形文字を行に配置し可視化するためのフォント情報を必要とする。しかしすべてのフォーマタや表示装置が交換対象文書が必要とするフォント情報を含んでいるとは限らず,必要に応じてフォント情報を他のシステムから提供されなければならない。ここにフォント情報の交換が求められる。
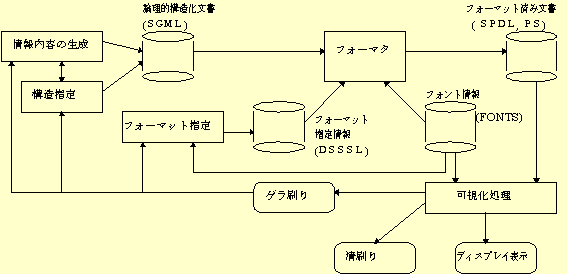
文書の生成過程における各処理と,処理間に受渡される情報とを図示すると,図4.1のようになる。ここで矩形が処理を示し,円筒形が情報を示す。それらの文書情報の交換には,その情報の表現形式,交換様式を送り手と受け手との間であらかじめ取決めておくことが必要である。図中の円筒形に付した文字列は,既に利用可能な情報表現形式または交換様式の名称の短縮形であり,正式な名称は次のとおりである。
| SGML: | Standard Generalized Markup Language[文献2)] |
| HTML: | HyperText Markup Language[文献3)] |
| XML: | Extensible Markup Language[文献4)] |
| DSSSL: | Document Style Semantics and Specification Language[文献5)] |
| SPDL: | Standard Page Description Language[文献6)] |
| PS: | PostScript[文献7)] |
| FONTS: | Font Information Interchange[文献8)] |
この文書生成モデルは,文書処理の発達,特に各作業の電子化と各段階での文書情報交換への要求に伴ってしだいに明確化され,整備された。
図4.1 文書生成モデル
文字と, 図・表などの関連表現手段との集合を文書情報とするとき, 閲覧者に対してより理解しやすい文書情報表現が望まれる。表示媒体を紙に限定すると, 関連表現手段は紙面にレンダリングされるものだけになるが, その限定を取り去った電子化環境では, 文書内容に応じた多様な関連表現手段を導入することが可能である。マルチメディア文書は, この電子化文書の利点を積極的に利用するものとして, 早くから注目されていたが, 動画画像や音声を含むマルチメディア文書が実用化するにはコンピュータの実行速度の向上を待つ必要があった。
なお, "多様な関連表現手段を導入"には, 単に人間の各種知覚(視覚,聴覚,触覚,加速度に対する感覚,その他)に対応する各種表現手段の導入という意味だけでなく, 情報技術を用いた活動によって生成される情報の生成段階に応じたさまざまな情報形態・符号化様式をもつ各種表現手段の導入という意味をも含めるのが適当であろう。例えば本の生成過程には,符号化文字列の段階,フォーマット指定された段階, 印刷され可視化された段階の各情報がある。聴覚に訴えるように音声に変換され朗読される本の情報形態もあり得る。音楽については,楽譜の段階の情報,それを演奏した情報がある。このような異なる段階に対応する情報形態をもち,知覚可能な情報へのレンダリングを行えるようにした各種表現手段を含む文書がマルチメディア文書である。
SGMLは外部実体としてどのようなファイルをも扱うことが可能であり, 枠組みとしてはマルチメディア文書のサポートが可能である。しかし実際の環境でマルチメディア文書を扱うためには, 各種表現手段に対応するファイルの内容を生成し, それをレンダリングして表示するシステムが必要であり, HTML文書とWebブラウザの普及によって多くのユーザがマルチメディア文書を手中におさめることができた。HTMLではマルチメディアデータは外部ファイルとして扱われ,文書中へのその取込みは, 属性またはハイパリンクを指定する要素型によって指定する。データタイプはファイル名の拡張子によって,例えば次のように示す。
| GIF画像 | .gif |
| TIFF画像 | .tiff |
| AIFF音声 | .aiff |
| MPEG動画像 | .mpeg |
HTMLはSGMLの一つのDTDであるが, マルチメディアデータをさらに柔軟に扱うために, SGMLの拡張であるHyTime9)が制定され, 既にその処理系[文献10)]も作られている。HyTimeは,文書内・文書間のリンク,他の情報オブジェクトとのリンクを指定し,時間的および空間的マルチメディア情報の配置を指定するための,標準化した機構を提供する。それによって,リンク情報やマルチメディア配置情報が,その情報を生成した環境とは異なるアプリケーションや実行環境による処理に対して利用可能になる。なお, このHyTimeについては, 最近改訂版[文献11)]が出版された。
HyTimeのマルチメディア対応機能の例を次に示す。
事象(event)はオブジェクトを座標空間に割付けるための要素であって,存在範囲指定と存在範囲調停(オブジェクトが指定された存在範囲に満たないか,はみだす場合の処置を規定)の情報をもつ。隣接した事象は事象グループとして,共通の属性を関連付けられる。
事象配置は,事象の列を規定する。一つの座標空間には,複数の事象配置が可能であり, アプリケーションが各種の事象配置を定義できる。例えば,複数種類のメディアに対応する事象をまとめて一つの事象配置を構成することもでき,メディア毎に事象をまとめて複数の事象配置を構成することもできる。
オブジェクト修飾と事象投影の機能によって,描出(レンダリングの一般化)処理を規定する引数を表現する。
オブジェクト修飾は,オブジェクトに対して, その描出の際に影響を与える要素(たとえばグラフィクスに被せる色変換フィルタ)である。
事象投影は,ある座標空間から別の座標空間への(投影元から投影先への)事象の存在範囲の変換である。これを使って,仮想時間で表現された音楽情報を実時間に写像することなどが可能になる。
マルチメディア情報へのアクセスには多様性が求められ,必ずしも論理時間の推移や事象列のシーケンスどおりにレンダリングを行う必要はない。遷移指示に従ってプレゼンテーションを行うとき,それを可能にする情報構造がハイパメディアであり,この構造をもつ文書がハイパメディア文書である。通常は二つ以上の情報オブジェクトの間の関係を表現するハイパリンクを用いて遷移先指示情報が記述される。
ハイパメディアは必ずしもマルチメディア環境だけで要求される技術ではない。例えば仏典は多様な注をもち, 多くのバージョンに対する参照が多用される。そのため, 以前からSGMLによるハイパメディア仏典記述[文献23)]が各国の研究者達によって行われている。
HyTimeでは,単一文書中に,または一つのハイパ文書を構成する文書と他の情報オブジェクトとの間に,ハイパリンクを定義できる。
ハイパリンクは二つ以上のリンク端を持つ要素で表現する。リンク端は,端点(anchor)と呼ぶオブジェクトをハイパリンクに関連付ける(図5.1参照)。
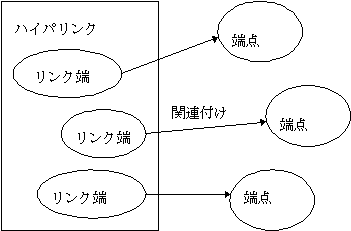
図5.1 HyTimeのハイパリンク構成
ハイパリンクのもう一つの特性にリンク型があり,それは意味的役割をハイパリンクに関連付ける。リンク型はアプリケーションが規定し,ハイパリンク要素の要素型で表現する。
HyTimeは,次の要素型形式を規定している。
XLink(XML Linking Language)21)は, XMLリソースの中でオブジェクト間のリンクを記述しするための構成子を規定する。シンタクスとしてXMLを用い, HTMLのリンク機能に加えて, 次のような機能拡張が用意されている。
これらは, 当初, XLL(Extensible Linking Language)[文献12)]として, XML言語規定と併行して開発されてきたものである。
対話形文書における対話形とは, 利用者または他のソースからの入力(stimulus)に対してアプリケーションが実時間ベースで応答することを意味する。この応答は, コンテントと後の情報表現とを変化させることが多い。
対話形文書を生成する際には, ページベース文書の生成や簡単なハイパメディア文書の生成のための規準とは異なる規準が必要になる。つまり, 文書の中にbehaviorをプログラムしなければならない。behavior要素を含むことは, 対話形文書の開発システムと配布システムとの間で非互換性を引き起こす可能性を与える。
従来の受動的な文書とハイパメディア文書(つまり第2世代の電子化までの文書)については, その構造, 内容, およびフォーマット指定を規定する規格が存在する。しかし, 対話形文書中のbehaviorを曖昧性なく記述する規定は未だない。異なるシステム間での対話形文書交換のためには, この規定を制定する必要がある。
プログラミング文脈の中にGUIオブジェクトを実装するための規格は既に制定されている。しかし対話形文書を作る者は, 装置非依存の方法で, どのようにしてこれらのインタフェースオブジェクトを利用しようとするかを表現可能にする必要があり, これを満たす規定への要求もある。
最近これらのユーザ要求が高まり, ISO/IEC JTC1に対してISMID[文献13)]という規格開発の作業課題が提案された。
最近のXML開発の背景には, 少なくとも次の2項目がある。
この(2)の要求こそが, 最近の電子化文書に求められる機械可読文書としての機能である。(2)で求められているアプリケーションは, 表面的に次の3タイプに分類[文献12)]される。
(1)のアプリケーションのためには, 連携させる文書情報を予め合意した互いに整合し得るDTDによって記述する必要がある。もともと連携させたい文書データは類似の構造をもち, 類似したDTDで表現されることが多いが, 完全には一致していないことがほとんどである。そこで, 共通の上位DTDからの派生による各アプリケーションでのDTD開発[文献14)], 又は共通するDTD部品を用いた各アプリケーションでのDTD開発[文献15)]などが検討されている。
(2)のアプリケーションの例として, 半導体データシートを配布してそのデータを使ってクライアントで設計支援ツールを実行するシステムを挙げることができる。(1)の場合と同様に, クライアントの処理系と半導体メーカが提供する半導体データシートとは, データの構造と記述方法とに関して予め合意しておく必要がある。半導体データシートについては, ECIX(Electronic Component Information Exchange)というプロジェクトが活動を行い, DTDの定義などを行っている[文献19)]。
(3)のアプリケーションのためには, 文書情報選択を可能にするための, その文書に本質的な特徴を記述する文書関連情報(メタデータ)を文書毎に記述する必要がある。以降にメタデータに関するいくつかの活動を紹介する。
Dublin Core[文献16),文献17)]は, ネットワーク環境に分散した文書の本質的特徴を記述してインデックス作成を自動化するための, 簡単かつ有用なメタデータ要素の集合を定式化するための試みであり, オブジェクトの記述に焦点を当て, 著者, タイトル, 主題などの記述データを含む13の要素(図6.1参照)を規定している。その規定に際しては, 要素と, 図書分類(AACR2/MARC)やFGDCメタデータスキームなどの既存の専門化された記述システムとの間のマッピングが考慮され, 対象範囲, 関連性などのについては, 熟練した分類専門家を必要とするような細かな分類を行わないための記述的分類方法の一般化が試みられた。なお, シンタクスの問題は意図的に避けている。
| Subject : | オブジェクトが扱うトピック |
| Title : | オブジェクトの名前 |
| Author : | オブジェクトの知的コンテンツに主として責任のある人 |
| Publisher : | オブジェクトを利用可能にしているエージェント又は機関 |
| Date : | 公表日時 |
| ObjectType : | 小説, 詩, 辞書といったオブジェクトのジャンル |
| Form : | PostScriptファイルなどのオブジェクトの記法 |
| Identifier : | オブジェクトを一意的に定義するために用いられる文字または数字 |
| Relation : | その他のオブジェクトに対する関連事項 |
| Source : | このオブジェクトが派生したオブジェクト |
| Language : | 知的コンテンツの言語 |
| Coverage : | オブジェクトの空間的配置及び継続時間の特徴 |
図6.1 Dublin Coreの要素
これらのデータ要素の列挙に加えて, Dublin CoreをまとめたDublin Workshopは中核をなすメタデータ集合全体に適用される次の基本原理を明確にしている。
Warwick Framework[文献17),文献18)]は, 文書内容の提供者・分類作業者・インデックス作成者と, 自動的にリソースを見つけて記述するシステムとの間の相互運用性を拡大することを目的として, 具体的で利用しやすいDublin Coreの定式化を求めるために, Warwick Workshopが行った成果であり, コンテナアーキテクチャの提案である。これは, 異なるメタデータスキーマによって記述されたメタデータを含むパッケージと, 複数のパッケージを論理的に集めるためのメカニズムであるコンテナを主な構成要素とする。
メタデータ集合から成るパッケージは, Dublin CoreやMARCレコードなどによって記述されたネットワークオブジェクトの属性情報を直接保有する。HTMLの<META>タグによって, 本体の一部として記述されたメタデータなどがこれに該当する。
インダイレクトのパッケージは, 属性情報を直接保有せず, 外部に存在するメタデータ集合を参照するポインタからなるパッケージである。インダイレクトのパッケージの参照先は, メタデータ集合から成るパッケージである場合と, 別のインダイレクトパッケージをさらに参照したインダイレクトパッケージである場合とがある。
コンテナは, それ自体がコンテナであるパッケージである。再帰上の限界は定義されていない。これら三つのパッケージの関係を, 図6.2に示す。
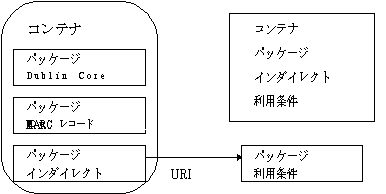
図6.2 三つのパッケージをもつメタデータコンテナ
メタデータは, パッケージとしてスキーマ毎に独立して管理される。そのためスキーマの管理はスキーマを作成した主体に完全に委ねられ, 管理の分散化が図られている。この枠組みでは, メタデータコンテナがオブジェクトによって内部的に参照される場合と, オブジェクトの外部から参照される場合の両方が可能である。内部から参照されるメタデータコンテナは, コンテンツオブジェクトの著作者または管理者がオブジェクトを記述するために選んだメタデータを指す。外部から参照されるメタデータコンテナは, コンテンツオブジェクトの作成者や管理者とは別の管理者によって作成され, 維持されるメタデータを指す。
この仕組みをどう実現するかは, 実装に委ねられているが, [文献17)]では, HTML, MIME, SGML及び分散環境での実装例を示している。
RDF(Resource Definition Framework)[文献20),文献22)]は, Apple Computerで開発されたMCF(Meta Content Framework)をもとに, W3C(World Wide Web Consotium)で検討されたメタデータのためのフレームワークで, Web上の機械可読情報を交換するアプリケーション間の相互運用を目的とする。人が介在せずにWebリソースを自動処理できるように配慮され, そのアプリケーションには, 検索エンジンによるリソース探索, 電子図書館などの内容のカテゴライズ, 知識共有のためのソフトウェアエージェント, 内容のランク付けなどが考えられている。
RDFの情報モデルでは, メタデータをリソース, プロパティ型, 値という三つ組みで表現する。同一リソースの三つ組みの集合であるアサーションとしてメタデータを記述し, 記述にXMLを用いている。
文書情報は紙から解き放たれることにより, 急速にその活性度を高め, これまでの文書流通系からネットワーク環境に進出して, ハイパメディア化, マルチメディア化, 機械可読化などの変貌を遂げてきた。当分の間この傾向は継続するであろう。その結果予想されることは, ネットワーク環境における膨大な情報量の文書の氾濫である。氾濫とは言っても, 高度に発達したツールによって適切に作成され, 適切にアクセスされる文書の氾濫である。既にその兆候は, 日々の作業の中で占めるEmail対処時間の増大に見ることができる。
結局問われるのは, それを最終的に処理する人の能力であり, 今後期待される技術は, 人の興味と能力に応じて電子化文書情報をフィルタリングし, それを適切なフロー制御のもとに人の脳に送りとどけるツールということになりそうである。