0. 文書オブジェクトモデルの概要
0.1 導入
文書オブジェクトモデル(Document Object Model,以下DOM)は,妥当な HTML 文書及び整形式の XML 文書のためのアプリケーションプログラムインタフェース(API)とする。それは,文書の論理構造を規定し,文書をアクセスし操作する方法を規定する。DOMの規定において,用語"文書"は,広い意味で使われる。XMLは,ますます,様々なシステムの中で記憶してよい多くの異なる種類の情報を表現する方法として使われるようになっているが,その多くは,これまでは文書としてでなく,データとして見なされてきた。それにも拘わらず,XMLは,このデータを文書として提示し,DOMは,このデータを管理するために利用してよい。
文書オブジェクトモデルを用いて,プログラマは,文書を構築し,その構造をたどり,要素及び内容を追加,修正又は削除することができる。HTML文書又はXML文書の中にあるいかなるものでも,文書オブジェクトモデルを用いて,アクセス,変更,削除又は追加することができる。ただし,わずかな例外がある。特に,XMLの内部サブセット及び外部サブセットに対するDOM インタフェース は,まだ規定されていない。
W3C規定として,文書オブジェクトモデルの一つの重要な目標に,多様な環境及び アプリケーション で使用可能な標準プログラムインタフェースを提供することがある。DOMは,任意のプログラム言語を用いて使用する設計になっている。DOMインタフェースの厳密で言語非依存な規定を与えるために,CORBAの2.3.1規定[CORBA]に定義されるとおりのオブジェクト管理グループ(Object Management Group,OMG)のIDL[OMGIDL]で規定を定義することにした。OMG IDL規定に加えて,Java [Java]及びECMAScript [ECMAScript] (JavaScript [JavaScript]及びJScript [JScript]に基づく工業規格のスクリプト言語)の 言語束縛 を提供する。
備考 OMG IDLは,インタフェースを規定する言語非依存で実装中立な一つの方法としてだけに使用する。様々な他のIDL([COM],[JavaIDL],[MIDL]など)も利用できる。一般に,IDLは,特定の計算環境に対して設計される。文書オブジェクトモデルは,いかなる計算環境でも実装でき,それらIDLに一般的に関連するオブジェクト結合実行時(環境)を必要としない。
0.2 DOMの位置付け
DOMは,文書のためのプログラムAPIとする。DOMは,それが モデル化 する文書の構造に極めて類似するオブジェクト構造に基づく。例えば,HTML文書から取り出した次の表を考える。
<TABLE>
<TBODY>
<TR>
<TD>Shady Grove</TD>
<TD>Aeolian</TD>
</TR>
<TR>
<TD>Over the River, Charlie</TD>
<TD>Dorian</TD>
</TR>
</TBODY>
</TABLE>
例示した表のDOMの図式表現を図1に示す。
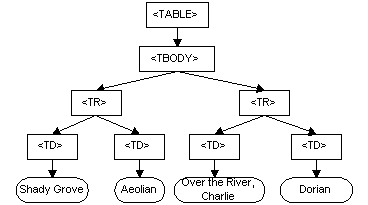
図1 例示した表のDOMの図式表現
DOMにおいては,文書は,木に非常に似た論理構造をもつ。より正確には,複数の木を含むことができる"森"又は"グローブ(木立ち)"に似た論理構造をもつ。各文書は,0個又は1個のdoctypeノード, 1個のルート(根)要素ノード,及び0個以上の注釈又は処理命令を含む。ルート要素は,文書の要素木の根として利用できる。しかし,DOMは,文書が木又はグローブとして 実装 されなければならないと規定しないし,オブジェクト間の関係がどのように実装されるかも規定しない。DOMは,いかなる都合のよい方法で実装してもよい論理的なモデルとする。この規定において,構造モデル という用語を使って,文書の木に似た表現を示す。"木散策"のメソッドを使って到達できるこれらの情報項目の配列に言及する場合にも,"木"という用語を使う。(ただし,この場合には,属性は含まない。)DOM構造モデルの一つの重要な特性に,構造的同形(structural isomorphism) がある。同じ文書の表現を生成するために二つの文書オブジェクトモデルの実装が使用される場合,XML情報集合[Infoset]に従って,それらは同じ構造モデルを生成する。
備考 DOMを構築するために用いる構文解析系に依存して,幾つかの変形があってもよい。例えば,構文解析系が要素内容の中の空白を破棄する場合には,DOMは,要素内容の中に空白を含まなくてもよい。
"文書オブジェクトモデル"という名前は,それが従来のオブジェクト指向設計の意味での"オブジェクトモデル"であることから,採用された。すなわち,文書は,オブジェクトを用いてモデル化され,そのモデルは,文書の構造だけでなく,文書及びそれを構成するオブジェクトの振る舞いも包み込む。換言すると,図1の中のノードは,データ構造を表現するのではなく,機能及び識別性をもつオブジェクトを表現している。オブジェクトモデルとして,DOMは,次を識別する。
- 文書を表現し操作するために用いるインタフェース及びオブジェクト。
- これらのインタフェース及びオブジェクトの,振る舞い及び属性の両方を含むセマンティクス。
- これらのインタフェース及びオブジェクトの間の関係及び協調。
- the interfaces and objects used to represent and manipulate a document
- the semantics of these interfaces and objects - including both behavior and attributes
- the relationships and collaborations among these interfaces and objects
SGML文書の構造は,従来より,オブジェクトモデルによってではなく,抽象 データモデル によって表現されてきた。抽象 データモデル では,モデルは,データ中心となる。オブジェクト指向プログラム言語では,データそれ自体が,そのデータを隠すオブジェクトの中にカプセル化され,直接的な外部操作からデータを保護している。これらのオブジェクトに関連する関数(メソッド)が,オブジェクトを操作してよい方法を決定し,オブジェクトモデルの一部となる。
0.3 類似システム
0.3では,類似していると思われるかもしれない他のシステムとの区別を行うことによって,DOMのより正確な理解を与える。
- 文書オブジェクトモデルは,バイナリ(コードのための)規定ではない。同じ言語束縛で書かれたDOMプログラムは,プラットフォーム間でのソースコードの互換性をもつが,DOMは,バイナリ相互運用性のいかなる形式も定義しない。
- 文書オブジェクトモデルは,オブジェクトをXML又はHTMLに固定する方法ではない。オブジェクトをXMLで表現してもよい方法を規定する代わりに,DOMは,XML文書及びHTML文書をオブジェクトとして表現する方法を規定する。その結果として,それらは,オブジェクト指向プログラムの中で使用してもよい。
- 文書オブジェクトモデルは,データ構造の集合ではない。それは,インタフェースを規定する オブジェクトモデル とする。この標準情報(TR)は,親子関係を示す図を含むが,それらは,プログラムインタフェースが定義する論理的な関係であって,特定の内部データ構造の表現ではない。
- 文書オブジェクトモデルは,文書中のどの情報が意味があるか,又は文書中の情報がどのように構造化されるかは,規定しない。XMLに関しては,これは,W3CのXML情報集合[Infoset]によって,規定される。DOMは,単に,この情報集合に対する API とする。
- 文書オブジェクトモデルは,その名前にも拘わらず,Component Object Model (COM)とは競合しない。COMは,CORBAに似たものであって,インタフェース及びオブジェクトを規定する言語非依存な方法とする。DOMは,HTML文書及びXML文書を管理するために設計されたインタフェース及びオブジェクトの集合とする。DOMは,COM又はCORBAに似た言語非依存なシステムを用いて実装してよい。DOMは,この標準情報(TR)の中で規定されるJava束縛又はECMAScript束縛に似た言語固有な束縛を用いて実装してもよい。
- The Document Object Model is not a binary specification. DOOM programs written in the same language binding will be source code compatible across platforms, but the DOM does not define any form of binary interoperability.
- The Document Object Model is not a way of persisting objects to XML or HTML. Instead of specifying how objects may be represented in XML, the DOM specifies how XML and HTML documents are represented as objects, so that they may be used in object oriented programs.
- The Document Object Model is not a set of data structures; it is an object model that specifies interfaces. Although this document contains diagrams showing parent/child relationships, these are logical relationships defined by the programming interfaces, not representations of any particular internal data structures.
- The Document Object Model does not define what information in a document is relevant or how information in a document is structured. For XML, this is specified by the W3C XML Information Set [Infoset]. The DOM is simply an API to this information set.
- The Document Object Model, despite its name, is not a competitor to the Component Object Model (COM). COM, like CORBA, is a language independent way to specify interfaces and objects; the DOM is a set of interfaces and objects designed for managing HTML and XML documents. The DOM may be implemented using language-independent systems like COM or CORBA; it may also be implemented using language-specific bindings like the Java or ECMAScript bindings specified in this document.
0.4 経緯
DOMは,JavaScriptのスクリプト及びJavaのプログラムをウェブブラウザ間で移植可能にするための規定として始まった。"動的HTML"は,文書オブジェクトモデルの直近の先祖であって,元来はブラウザの観点で大部分が考えられていた。しかし,DOM作業グループがW3Cに設立されると,そのグループには,HTML又はXMLの編集ツール及び文書レポジトリを含む,他の分野のベンダも加わった。これらのベンダの幾つかは,XMLが開発される前には,SGMLで作業していた。結果として,DOMは,SGMLのグロープ及びHyTimeの規格によって影響を受けた。これらのベンダの中には,SGML/XMLの編集ツール又は文書レポジトリに対してAPIを提供するために,彼ら独自の文書用のオブジェクトモデルを開発していたものもあり,これらのオブジェクトモデルもDOMに影響を与えた。
0.5 実体及びDOMコア
基礎DOMインタフェースにおいては,実体を表現するオブジェクトは存在しない。数値文字参照,並びにHTML及びXMLにおいて定義済みの実体への参照は,その実体の置換えを構成する単一文字によって置き換えられる。次に例を示す。
<p>This is a dog & a cat</p>
ここで,"&"は,文字"&"によって置き換えられ,P要素の中のテキストは, 文字の一つの連続した列を形成する。数値文字参照及び定義済み実体は,CDATAセクション又はHTMLのSCRIPT要素及びSTYLE要素においてはそのように認識されないので,それら実体が参照するとように見える単一文字によって置き換えられない。この例がCDATAセクションの中に入っている場合には,"&"は,"&"によって置き換えられず,<p>は,開始タグとして認識されない。一般実体,すなわち,内部実体及び外部実体の両方,の表現は,DOM水準1[DOM Level 1]の拡張(XML)インタフェース内で定義される。
備考 文書のDOM表現が,XML又はHTMLのテキストとして直列化される場合には,アプリケーションは,テキストデータの中の各文字をチェックして,それが数値又は定義済みの実体を使って別扱いされる必要があるかどうかを調べる必要がある。そうすることに失敗した場合には,妥当でないHTML又はXMLを生じることがある。 実装 も,次の事実に注意することが望ましい。すなわち,ISO 10646を完全には網羅しない文字符号化("charset")に存在しない文字が,マーク付け又はCDATAセクションの中に存在する場合には,その文字符号化への直列化は,失敗するかもしれない。
0.6 適合性
0.6では,DOM水準2への適合性の異なる水準を示す。DOM水準2は,14個のモジュールから成る。DOM水準2に適合すること,又はDOM水準2のモジュールに適合することが,可能になる。
実装が,この標準情報(TR)が定義するコアモジュール(基礎インタフェース参照)をサポートする場合には,DOM水準2適合とする。実装が,あるDOM水準2のモジュールに対するインタフェース及びその関連するセマンティクスのすべてをサポートする場合には,そのDOM水準2モジュールに適合する。
DOM水準2モジュール及びそれが使用する機能の完全なリストを次に示す。機能名は,大文字・小文字の区別をしない。
-
コアモジュール
Core module
- 機能 "Core" を定義する。
-
XMLモジュール
XML module
- 機能 "XML" を定義する。
-
HTMLモジュール
HTML module
- 機能"HTML"を定義する。([DOM Level 2 HTML]を参照。)
備考 原規定の公表時には,このDOM水準2モジュールは,まだW3C勧告ではない。
-
ビューモジュール
Views module
- [DOM Level 2 Views]における機能 "Views" を定義する。
-
スタイルシートモジュール
Style Sheets module
- [DOM Level 2 Style Sheets]における機能 "StyleSheets" を定義する。
-
CSSモジュール
CSS module
- [DOM Level 2 CSS]における機能 "CSS" を定義する。
-
CSS2モジュール
CSS2 module
- [DOM Level 2 CSS]における機能 "CSS2" を定義する。
-
イベントモジュール
Events module
- [DOM Level 2 Events]における機能 "Events" を定義する。
-
利用者インタフェースイベントモジュール
User interface Events module
- [DOM Level 2 Events]における機能 "UIEvents" を定義する。
-
マウスイベントモジュール
Mouse Events module
- [DOM Level 2 Events]における機能 "MouseEvents" を定義する。
-
変異イベントモジュール
Mutation Events module
- [DOM Level 2 Events]における機能 "MutationEvents" を定義する。
-
HTMLイベントモジュール
HTML Events module
- [DOM Level 2 Events]における機能 "HTMLEvents" を定義する。
-
範囲モジュール
Range module
- [DOM Level 2 Range]における機能 "Range" を定義する。
-
たどりモジュール
Traversal module
- [DOM Level 2 Traversal]における機能 "Traversal" を定義する。
DOMの実装は,モジュールに適合しない場合には,その機能に関するDOMImplementationインタフェースのhasFeature(feature, version) メソッド に対して,"true"を返してはならない。DOM水準2で使われる全機能のversion(版)の数は,"2.0"とする。
"true" to the
hasFeature(feature, version) method of the DOMImplementation
interface for that feature
unless the implementation conforms to
that module. The version number for all features used
in DOM Level 2.0 is "2.0".
0.7 DOMインタフェース及びDOM実装
DOMは,XML文書又はHTML文書を管理するのに使ってもよいインタフェースを規定する。これらのインタフェースが"抽象化"になっていることを実現することを重要とする。すなわち,C++における"抽象基底クラス"と同様に,そのインタフェースは,ある文書のアプリケーションの内部表現にアクセスして操作する方法を規定する手段とする。インタフェースは,特定の具体的な実装を示唆しない。各DOMアプリケーションは,この規定が示すインタフェースをサポートする限り,文書を,いかなる都合のよい表現で自由に維持管理してもよい。DOM実装の中には,DOM規定が存在したずっと以前に書かれたソフトウェアにアクセスするために,DOMインタフェースを用いる既存のプログラムがあってもよい。したがって,DOMは,特に次に示す実装依存性を避けるために設計されている。
| a) | IDLにおいて定義される属性は,特定のデータメンバをもたなければならない具体的なオブジェクトを意味しない。すなわち,言語束縛において,それらは,get()関数及びset()関数の対に翻訳され,データメンバには翻訳されない。読取り専用の属性は,その言語束縛において,get()関数だけをもつ。 |
| b) | DOMアプリケーションは,この規定にはないがそれでもDOM適合と考えられる付加的なインタフェース及びオブジェクトを提供してもよい。 |
| c) | インタフェースが規定されるが,生成される実際のオブジェクトは規定されないので,DOMは,実装のためにどのコンストラクタを呼び出すのがよいかを知ることはできない。一般に,DOM利用者は,文書構造を生成するためにDocumentクラスのcreateX()メソッドを呼び出し,DOM実装が,createX()関数のその実装において,これらの構造のその実装自体の内部表現を生成する。 |
- Attributes defined in the IDL do not imply concrete objects which must have specific data members - in the language bindings, they are translated to a pair of get()/set() functions, not to a data member. Read-only attributes have only a get() function in the language bindings.
- DOM applications may provide additional interfaces and objects not found in this specification and still be considered DOM conformant.
- Because we specify interfaces and not the actual objects that are to be created, the DOM cannot know what constructors to call for an implementation. In general, DOM users call the createX() methods on the Document class to create document structures, and DOM implementations create their own internal representations of these structures in their implementations of the createX() functions.
水準1のインタフェースは,水準1及び水準2の機能の両方を提供するために, 拡張された。
Java又はECMAScript以外の言語でのDOM実装は,その言語及び実行時環境にとって適切で自然な束縛を選択してよい。例えば,Documentから継承され新しいメソッド及び属性を含む(別の)Document2クラスの生成を必要とするシステムが存在してもよい。
DOM水準2は,マルチスレッド機構を規定しない。