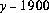 偺昞尰偲偡傞丅
偺昞尰偲偡傞丅
僷僢働乕僕 java.util
偼丆庬乆偺儐乕僥傿儕僥傿僋儔僗媦傃僀儞僞僼僃乕僗傪娷傓丅
儐乕僥傿儕僥傿偺拞偱摿挜揑側傕偺偵偼丆僀儞僞僼僃乕僗
Enumeration
偑偁傞丅偙偺僀儞僞僼僃乕僗傪幚憰偟偨僆僽僕僃僋僩偼丆崁栚偺楍傪惗惉偟丆昁梫偵墳偠偰堦偮偢偮崁栚傪搉偡丅Dictionary
媦傃 Vector 側偳偺僐儞僥僫僋儔僗偼 Enumeration
傪曉偡堦偮埲忋偺儊僜僢僪傪採嫙偡傞丅
BitSet
偼丆旕晧惍悢傪昞尰偡傞偺偵巊梡壜擻側價僢僩偺僀儞僨僋僗晅偒偺廤傑傝傪娷傓丅
僋儔僗 Date
偼丆擔帪忣曬傪昞尰偟憖嶌偡傞偺偵曋棙側曽朄傪採嫙偡傞丅擔帪忣曬偼丆擭丆寧丆擔丆帪丆暘媦傃昩偵傛偭偰峔惉偱偒丆偙傟傜榋偮偺梫慺偼丆梛擔偲偲傕偵擔帪忣曬偐傜庢傝弌偡偙偲偑偱偒傞丅帪娫懷媦傃壞帪娫傕揔愗偵峫椂偡傞丅
拪徾僋儔僗偺 Dictionary
偼丆嶕堷僉乕偲抣偲偺懳偺廤傑傝偱偁傝丆嶕堷僉乕傪梌偊偰抣傪庢傝弌偣傞丅僋儔僗
Hashtable 偼丆Dictionary
偺堦偮偺嬶懱揑側幚憰偲偡傞丅僋儔僗 Properties
偼丆Hashtable
偺奼挘偲偟丆偁傞僥乕僽儖偑懠偺僥乕僽儖偵僨僼僅儖僩抣傪梌偊傞偙偲傪壜擻偵偟丆僼傽僀儖偐傜偺僄儞僩儕偺撉弌偟媦傃僼傽僀儖傊偺僄儞僩儕偺彂弌偟偺昗弨揑庤抜傪採嫙偡傞丅
僋儔僗 Observable 偼丆僆僽僕僃僋僩 Observable
偑曄壔偡傞偲偒偵丆乬娤應幰乭偲屇傇懠偺僆僽僕僃僋僩偵捠抦偡傞婡峔傪採嫙偡傞丅娤應幰僆僽僕僃僋僩偼丆僀儞僞僼僃乕僗
Observer
傪幚憰偡傞擟堄偺僆僽僕僃僋僩偁偭偰傛偄丅乮偙偺捠抦婡峔偼丆僋儔僗
Object (20.1)偺儊僜僢僪
wait 媦傃儊僜僢僪 notify
偑採嫙偡傞傕偺偲偼堘偄丆僗儗僢僪僗働僕儏乕儕儞僌婡峔偲偼寢傃晅偄偰偄側偄丅乯
僋儔僗 Random
偼丆庬乆偺僾儕儈僥傿僽宆偺悢抣傪庬乆偺暘嶶偱媈帡棎悢揑偵敪惗偡傞庤朄偺奼挘廤崌傪採嫙偡傞丅僋儔僗
Random 偺僀儞僗僞儞僗偼丆撈棫偟偨媈帡棎悢敪惗婍偲偡傞丅
StringTokenizer
偼丆楍傪暘偗偰僩乕僋儞偲偡傞娙扨側曽朄傪採嫙偡傞丅僩乕僋儞傪嬫愗傞暥帤偺廤崌偼丆愝掕壜擻偲偡傞丅僩乕僋儞愗傝弌偟儊僜僢僪偼丆僋儔僗
java.io.StreamTokenizer
偱巊梡偝傟偰偄傞儊僜僢僪傛傝傕偼傞偐偵娙扨側傕偺傪梡偄偰偄傞丅椺偊偽
StringTokenizer
偼丆幆暿巕丆悢媦傃堷梡暥帤楍傪嬫暿偣偢丆拲庍偺擣幆媦傃僗僉僢僾傪峴傢側偄丅
僋儔僗 Vector 媦傃 Stack
偼丆Java攝楍傪奼挘偡傞扨弮側僐儞僥僫僋儔僗偲偡傞丅Vector
偼丆Java攝楍偲偼堘偭偰丆偦偺僒僀僘傪曄偊傞偙偲偑偱偒丆捛壛丆嶍彍媦傃崁栚偺専嶕側偳傪偡傞偨傔偵懡偔偺曋棙側儊僜僢僪傪採嫙偡傞丅Stack
偼丆push 媦傃 pop 側偳偺晅壛揑側憖嶌傪傕偮
Vector 偲偡傞丅
僷僢働乕僕 java.util
偱掕媊偡傞僋儔僗奒憌傪師偵帵偡丅乮偙偙偱柤慜偑懢帤偱帵偝傟傞僋儔僗偑僷僢働乕僕
java.util 撪偵懚嵼偡傞丅偦傟埲奜偼僷僢働乕僕
java.lang 偵懚嵼偟丆僒僽僋儔僗娭學傪柧妋偵偡傞偨傔偵帵偡丅乯
Object20.1interfaceEnumeration 21.1BitSet 21.2Date 21.3Dictionary 21.4Hashtable 21.5Properties 21.6Observable 21.7interfaceObserver 21.8Random 21.9StringTokenizer 21.10Vector 21.11Stack 21.12Throwable20.22 Exception RuntimeExceptionEmptyStackException 21.13NoSuchElementException 21.14
java.util.EnumerationEnumeration
傪幚憰偡傞僆僽僕僃僋僩偼丆1搙偵堦偮偺梫慺楍傪惗惉偡傞丅儊僜僢僪
nextElement
傪孞傝曉偟屇傃弌偡偙偲偵傛偭偰丆楍拞偺奺梫慺傪弴師曉偡丅
public interfaceEnumeration{ public booleanhasMoreElements(); public ObjectnextElement() throws NoSuchElementException; }
21.1.1 public boolean
hasMoreElements()
楍嫇乮enumeration乯僆僽僕僃僋僩偑丆彮側偔偲傕傕偆堦偮偺採嫙偡傞梫慺傪傕偮偲偒偵尷偭偰丆寢壥傪
true 偲偡傞丅
21.1.2 public Object
nextElement()
throws NoSuchElementException
楍嫇僆僽僕僃僋僩偑丆彮側偔偲傕傕偆堦偮偺採嫙偡傞梫慺傪傕偮側傜偽丆偦偺梫慺傪曉偡丅偦傟埲奜偺応崌偵偼丆NoSuchElementException
偑搳偘傜傟傞丅
僴僢僔儏僥乕僽儖 ht
撪偺偡傋偰偺僉乕媦傃僉乕偺挿偝傪昞帵偡傞僐乕僪椺傪師偵帵偡丅儊僜僢僪
keys
偼丆偡傋偰偺僉乕傪攝晍偡傞楍嫇傪曉偡丅偙偺椺偱偼丆僉乕傪暥帤楍偲偟偨応崌傪帵偡丅
Enumeration e = ht.keys();
while (e.hasMoreElements()) {
String key = (String)e.nextElement();
System.out.println(key + " " + key.length());
}
java.util.BitSetBitSet
偼丆昁梫偵墳偠偰奼挘偝傟傞價僢僩偺廤崌偲偡傞丅BitSet
偺價僢僩偼旕晧惍悢偵傛偭偰僀儞僨僋僗晅偗偡傞丅奺價僢僩偼奺乆丆僠僃僢僋丆愝掕枖偼夝彍傪壜擻偲偡傞丅堦偮偺
BitSet 偺AND丆OR媦傃XOR偺奺墘嶼偵傛偭偰丆傕偆堦偮
BitSet 偺撪梕傪廋惓偡傞丅
public final classBitSetimplements Cloneable { publicBitSet(); publicBitSet(int nbits); public StringtoString(); public booleanequals(Object obj) public inthashCode(); public Objectclone(); public booleanget(int bitIndex); public voidset(int bitIndex); public voidclear(int bitIndex); public voidand(BitSet set); public voidor(BitSet set); public voidxor(BitSet set); public intsize(); }
21.2.1 public
BitSet()
偙偺僐儞僗僩儔僋僞偼丆怴偨偵惗惉偟偨 BitSet
傪弶婜壔偟丆偡傋偰偺價僢僩傪僋儕傾偡傞丅
21.2.2 public
BitSet(int nbits)
偙偺僐儞僗僩儔僋僞偼丆怴偨偵惗惉偟偨 BitSet
傪弶婜壔偟丆偡傋偰偺價僢僩傪僋儕傾偡傞丅0 偐傜
nbits-1
傑偱偺斖埻偺僀儞僨僋僗偱丆柧帵揑偵價僢僩傪昞尰偡傞偨傔偵廫暘側椞堟傪妋曐偡傞丅
21.2.3 public String
toString()
BitSet
偺愝掕忬懺偵偁傞價僢僩傪傕偮僀儞僨僋僗偡傋偰偵懳偟偰丆偦偺僀儞僨僋僗偺10恑昞尰傪寢壥偵娷傓丅僀儞僨僋僗偼彫偝側抣偐傜暲傇傕偺偲偟丆",
"乮僐儞儅媦傃僗儁乕僗乯偱嬫愗傝丆攇妵屖偱埻傓丅偦偺寢壥丆惍悢廤崌偺捠忢偺悢妛婰朄傪曉偡丅
偙偺儊僜僢僪偼丆Object (20.1.2)偺
儊僜僢僪 toString 傪抲偒姺偊傞丅
BitSet drPepper = new BitSet();
偙偙偱丆drPepper.toString() 偼 "{}" 傪曉偡丅
drPepper.set(2);
偙偙偱丆drPepper.toString() 偼 "{2}" 傪曉偡丅
drPepper.set(4); drPepper.set(10);偙偙偱丆
drPepper.toString() 偼 "{2, 4, 10}"
傪曉偡丅
21.2.4 public boolean
equals(Object obj)
堷悢偑 null 偱側偔丆偡傋偰偺旕晧 int 僀儞僨僋僗
k 偵懳偟師偺忦審傪枮偨偡丆僆僽僕僃僋僩 BitSet
偱偁傞偲偒偵尷偭偰丆寢壥傪 true 偲偡傞丅
((BitSet)obj).get(k) == this.get(k)偙偺儊僜僢僪偼丆
Object(20.1.3)偺儊僜僢僪 equals
傪抲偒姺偊傞丅21.2.5 public int
hashCode()
僴僢僔儏僐乕僪偼丆偳偺價僢僩偑 BitSet
撪偱愝掕偝傟偰偄偨偐偩偗偵埶懚偡傞丅偙偺寁嶼偵巊梡偡傞傾儖僑儕儉傪師偵帵偡丅
BitSet 撪偺價僢僩傪丆椺偊偽 bits 偲屇傇
long
惍悢偺攝楍撪偵婰榐偡傞丅偨偩偟丆師偺昞尰偑惓偟偄偲偒偵尷傝丆
BitSet 撪偺價僢僩 k乮k
偺抣偼旕晧乯傪愝掕偡傞丅
((k>>6) < bits.length) &&
((bits[k>>6] & (1L << (bit &
0x3F))) != 0)
偙偺偲偒丆師偺儊僜僢僪 hashCode
偺掕媊傪幚嵺偺傾儖僑儕僘儉偺惓偟偄幚憰偲偡傞丅
public synchronized int hashCode() {
long h = 1234;
for (int i = bits.length; --i >= 0; ) {
h ^= bits[i] * (i + 1);
}
return (int)((h >> 32) ^ h);
}
價僢僩偺廤崌偑曄壔偡傟偽僴僢僔儏僐乕僪抣偑曄壔偡傞偙偲偵拲堄丅
偙偺儊僜僢僪偼丆Object(20.1.4)偺儊僜僢僪 hashCode
傪抲偒姺偊傞丅
21.2.6 public Object
clone()
BitSet 偺僋儘乕僯儞僌偼丆偦偺 BitSet
偵摍偟偄怴偟偄 BitSet 傪惗惉偡傞丅
偙偺儊僜僢僪偼丆Object(20.1.5)偺儊僜僢僪 clone
傪抲偒姺偊傞丅
21.2.7 public boolean
get(int bitIndex)
僀儞僨僋僗 bitIndex 傪傕偮價僢僩偑丆尰嵼偙偺
BitSet 偵愝掕偝傟偰偄傞側傜偽丆寢壥傪 true
偲偡傞丅偦傟埲奜偺応崌偵偼丆false 偲偡傞丅
bitIndex 偑晧側傜偽丆IndexOutOfBoundsException
偑搳偘傜傟傞丅
21.2.8 public void
set(int bitIndex)
BitSet 撪偺僀儞僨僋僗 bitIndex
偺價僢僩傪乬僙僢僩乭乮true乯忬懺偵曄偊傞丅
bitIndex 偑晧側傜偽丆IndexOutOfBoundsException
偑搳偘傜傟傞丅
bitIndex 偑儊僜僢僪 size (21.2.13)偑曉偡抣傛傝傕彫偝偔側偄側傜偽丆偙偺
BitSet 偺僒僀僘傪 bitIndex 傛傝傕戝偒偔偡傞丅
21.2.9 public void
clear(int bitIndex)
BitSet 撪偺僀儞僨僋僗 bitIndex
偺價僢僩傪乬僋儕傾乭乮false乯忬懺偵曄偊傞丅
bitIndex 偑晧側傜偽丆IndexOutOfBoundsException
偑搳偘傜傟傞丅
bitIndex 偑丆儊僜僢僪 size
(21.2.13)偑曉偡抣傛傝傕彫偝偔側偄側傜偽丆偙偺
BitSet 偺僒僀僘傪 bitIndex 傛傝傕戝偒偔偡傞丅
21.2.10 public void
and(BitSet set)
偄偔偮偐偺價僢僩傪僋儕傾偡傞偙偲偵傛偭偰 BitSet
傪廋惓偱偒傞丅偡傋偰偺旕晧 int 僀儞僨僋僗 k
偵懳偟丆set 偺價僢僩 k
傪僋儕傾偟偰偄傞側傜偽丆BitSet 偺價僢僩 k
傪僋儕傾偡傞丅
21.2.11 public void
or(BitSet set)
偄偔偮偐偺價僢僩傪愝掕偡傞偙偲偵傛偭偰 BitSet
傪廋惓偱偒傞丅偡傋偰偺旕晧 int 僀儞僨僋僗 k
偵懳偟丆set 偺價僢僩 k
偑愝掕偝傟偰偄傞側傜偽丆BitSet 偺價僢僩 k
傪愝掕偡傞丅
21.2.12 public void
xor(BitSet set)
偄偔偮偐偺價僢僩傪斀揮偡傞偙偲偵傛偭偰 BitSet
傪廋惓偱偒傞丅偡傋偰偺旕晧 int 僀儞僨僋僗 k
偵懳偟丆set 偺價僢僩 k
偑愝掕偝傟偰偄傞側傜偽丆BitSet 偺價僢僩 k
傪斀揮偡傞丅
21.2.13 public int
size()
偙偺儊僜僢僪偼丆價僢僩抣偺昞尰偺偨傔偵偙偺 BitSet
偑幚嵺偵巊梡偡傞椞堟偺價僢僩悢傪曉偡丅
java.util.DateDate
偼丆僔僗僥儉撈棫側拪徾昞尰偺擔帪忣曬傪儈儕昩偺惛搙偱採嫙偡傞丅擔帪忣曬偼丆擭丆寧丆擔乮壗寧壗擔偺擔乯丆帪丆暘媦傃昩偱峔惉偡傞丅偙偺俇屄偺梫慺偲梛擔傪庢傝弌偣傞丅擔帪忣曬偼斾妑壜擻偲偟丆壜撉暥帤楍偵曄姺壜擻偲偡傞丅
public class椺丗Date{ publicDate(); publicDate(long time); publicDate(int year, int month, int date); publicDate(int year, int month, int date, int hours, int minutes); publicDate(int year, int month, int date, int hours, int minutes, int seconds); publicDate(String s) throws IllegalArgumentException; public StringtoString(); public booleanequals(Object obj); public inthashCode(); public intgetYear(); public voidsetYear(int year); public intgetMonth(); public voidsetMonth(int month); public intgetDate(); public voidsetDate(int date); public intgetDay(); public intgetHours(); public voidsetHours(int hours); public intgetMinutes(); public voidsetMinutes(int minutes); public intgetSeconds(); public voidsetSeconds(int seconds); public longgetTime(); public voidsetTime(long time); public booleanbefore(Date when); public booleanafter(Date when); public StringtoLocaleString(); public StringtoGMTString(); public intgetTimezoneOffset(); public static longUTC(int year, int month, int date, int hours, int minutes, int seconds); public static longparse(String s) throws IllegalArgumentException; }
Date 偼嫤掕悽奅帪UTC乮Coordinated Universal
Time乯傪斀塮偡傞偑丆Java僔僗僥儉偺儂僗僩娐嫬偵埶懚偟丆昁偢偟傕惓妋偱側偔偲傕傛偄丅嵟嬤偺傎偲傫偳偡傋偰偺僆儁儗乕僥傿儞僌僔僗僥儉偼丆偄偐側傞応崌偱傕丆1擔
亖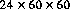 = 86400 s
偲偟偰偄傞丅偟偐偟UTC偱偼丆栺1擭枖偼2擭偵1搙丆乬偆傞偆昩乭偲尵偆梋暘側1昩偑懚嵼偡傞丅偆傞偆昩偼丆忢偵1擔偺丆偦傟傕杦傫偳忢偵12寧31擔枖偼6寧30擔偺丆嵟屻偺1昩偵晅偗壛偊傞丅椺偊偽丆1995擭偺嵟屻偺1暘偼丆偆傞偆昩傪晅偗壛偊偰61昩偲偟偨丅
傎偲傫偳偺尰嵼偺僐儞僺儏乕僞僋儘僢僋偼丆偆傞偆昩偺堘偄傪斀塮偱偒傞傎偳廫暘偵偼惓妋偱偼側偄丅悽奅帪
UT乮Universal Time乯偲摍壙側僌儕僯僢僠暯嬒帪 GMT乮Greenwich Mean
Time乯偵傛偭偰掕媊偝傟傞僐儞僺儏乕僞婯奿傕懚嵼偡傞丅偦偺婯奿偱偼丆乬捠懎側乭柤慜傪
GMT丆乬壢妛揑側乭柤慜傪 UT 偲偟偰偄傞丅UTC 媦傃 UT
偺堘偄偼丆尨巕帪寁偵婎偯偔傕偺傪 UTC 偲偟丆揤暥娤應偵婎偯偔傕偺傪 UT
偲偡傞丅幚梡栚揑偱偼偦偺嵎偼傎偲傫偳側偄丅抧媴偺夞揮偼堦條偱偼側偔丆暋嶨側曽朄偱抶偔枖偼懍偔側傞偺偱丆UT
偼忢偵堦條偵偼棳傟偰偄側偄丅偆傞偆昩偼丆偁傞廋惓傪巤偟偨 UT 偺斉偱偁傞UT1偺
0.9 昩撪偵 UTC 傪廂傔傞偨傔偵昁梫偱摫擖偟偨丅
= 86400 s
偲偟偰偄傞丅偟偐偟UTC偱偼丆栺1擭枖偼2擭偵1搙丆乬偆傞偆昩乭偲尵偆梋暘側1昩偑懚嵼偡傞丅偆傞偆昩偼丆忢偵1擔偺丆偦傟傕杦傫偳忢偵12寧31擔枖偼6寧30擔偺丆嵟屻偺1昩偵晅偗壛偊傞丅椺偊偽丆1995擭偺嵟屻偺1暘偼丆偆傞偆昩傪晅偗壛偊偰61昩偲偟偨丅
傎偲傫偳偺尰嵼偺僐儞僺儏乕僞僋儘僢僋偼丆偆傞偆昩偺堘偄傪斀塮偱偒傞傎偳廫暘偵偼惓妋偱偼側偄丅悽奅帪
UT乮Universal Time乯偲摍壙側僌儕僯僢僠暯嬒帪 GMT乮Greenwich Mean
Time乯偵傛偭偰掕媊偝傟傞僐儞僺儏乕僞婯奿傕懚嵼偡傞丅偦偺婯奿偱偼丆乬捠懎側乭柤慜傪
GMT丆乬壢妛揑側乭柤慜傪 UT 偲偟偰偄傞丅UTC 媦傃 UT
偺堘偄偼丆尨巕帪寁偵婎偯偔傕偺傪 UTC 偲偟丆揤暥娤應偵婎偯偔傕偺傪 UT
偲偡傞丅幚梡栚揑偱偼偦偺嵎偼傎偲傫偳側偄丅抧媴偺夞揮偼堦條偱偼側偔丆暋嶨側曽朄偱抶偔枖偼懍偔側傞偺偱丆UT
偼忢偵堦條偵偼棳傟偰偄側偄丅偆傞偆昩偼丆偁傞廋惓傪巤偟偨 UT 偺斉偱偁傞UT1偺
0.9 昩撪偵 UTC 傪廂傔傞偨傔偵昁梫偱摫擖偟偨丅
嶲峫丂偙傟埲奜偺擔帪僔僗僥儉傕懚嵼偡傞丅椺偊偽丆GPS乮the satellite-based Global Positioning System乯偱巊梡偡傞帪娫僗働乕儖偼丆UTC 偲摨婜偡傞偑丆偆傞偆昩偺挷惍偼側偄丅偙傟埲奜偺嫽枴怺偄忣曬偵偼丆乬the U. S. Naval Observatory乭丆摿偵師偺倂倂倂僒僀僩偐傜傾僋僙僗壜擻側乬the Directorate of Time乭偑偁傞丅
http://tycho.usno.navy.mil師偺倂倂倂僒僀僩偐傜傾僋僙僗壜擻側乬Systems of Time乭偺掕媊傕嫽枴怺偄丅
http://tycho.usno.navy.mil/systime.html
擭丆寧丆擔乮壗寧壗擔偺擔乯帪丆暘媦傃昩偺抣傪庴偗庢傞僋儔僗枖偼曉偡僋儔僗
Date 偺偡傋偰偺儊僜僢僪偼丆師偺昞尰傪巊梡偡傞丅
偺昞尰偲偡傞丅
21.3.1 public
Date()
偙偺僐儞僗僩儔僋僞偼丆怴偟偔惗惉偟偨僆僽僕僃僋僩 Date
傪弶婜壔偟丆儈儕昩扨埵偱應偭偰惗惉帪崗偵嵟傕嬤偄弖娫傪昞尰偡傞丅
21.3.2 public
Date(long time)
偙偺僐儞僗僩儔僋僞偼丆怴偟偔惗惉偟偨僆僽僕僃僋僩 Date
傪弶婜壔偟丆乬僄億僢僋乭偲偟偰抦傜傟傞婎弨帪崗丆偮傑傝丆僌儕僯僢僠暯嬒帪1970擭1寧1擔00:00:00丆偐傜
time ms 屻偺帪崗偺弖娫傪昞尰偡傞丅僋儔僗 System
偺儊僜僢僪 currentTimeMillis
(20.18.6)傕嶲徠偺偙偲丅
21.3.3 public
Date(int year, int month, int date)
偙偺僐儞僗僩儔僋僞偼丆怴偟偔惗惉偟偨僆僽僕僃僋僩 Date
傪弶婜壔偟丆抧堟帪娫懷偵偍偗傞 year 堷悢丆month
堷悢媦傃 date
堷悢偵傛偭偰巜掕偡傞擔偺屵慜楇帪傪昞尰偡傞丅偙傟偼丆師偺僐儞僗僩儔僋僞屇傃弌偟偲摨偠岠壥傪傕偮丅
(21.3.5)
Date(year, month, date, 0, 0, 0)
21.3.4 public
Date(int year, int month, int date,
int hours, int minutes)
偙偺僐儞僗僩儔僋僞偼丆怴偟偔惗惉偟偨僆僽僕僃僋僩 Date
傪弶婜壔偟丆抧堟帪娫懷偵偍偗傞
year丆month丆date丆hours
媦傃 minutes
偺堷悢偵傛偭偰巜掕偡傞暘偺嵟弶偺弖娫傪昞尰偡傞丅偙傟偼丆師偺僐儞僗僩儔僋僞屇傃弌偟偲摨偠岠壥傪傕偮丅
(21.3.5)
Date(year, month, date, hours, minutes, 0)
21.3.5 public
Date(int year, int month, int date, int hours, int minutes, int seconds)
偙偺僐儞僗僩儔僋僞偼丆怴偟偔惗惉偟偨僆僽僕僃僋僩 Date
傪弶婜壔偟丆year丆month丆date丆hours丆minutes
媦傃 seconds
偺堷悢偵傛偭偰巜掕偡傞抧堟帪娫懷偵偍偗傞昩偺嵟弶偺弖娫傪昞尰偡傞丅
21.3.6 public
Date(String s)
throws
IllegalArgumentException
偙偺僐儞僗僩儔僋僞偼丆怴偟偔惗惉偟偨僆僽僕僃僋僩 Date
傪弶婜壔偟丆暥帤楍 s偵傛偭偰巜掕偡傞擔帪傪儊僜僢僪 parse(21.3.31)傪巊偭偨偐偺傛偆偵夝庍偟偰丆偦偺擔帪傪昞尰偡傞丅
21.3.7 public String
toString()
僆僽僕僃僋僩 Date 傪丆師偺宍幃偺 String
偵曄姺偡傞丅
"dow mon dd hh:mm:ss zzz yyyy"偙偙偱丆奺昞尰偼師偺偲偍傝偲偡傞丅
dow 偼丆梛擔乮Sun,
Mon,Tue, Wed, Thu,
Fri,Sat乯偲偡傞丅
mon 偼丆寧乮Jan,
Feb,Mar, Apr,
May,Jun,Jul,Aug,Sep,
Oct,Nov, Dec乯偲偡傞丅
dd 偼丆2寘偺10恑悢偺擔晅乮01 偐傜
31 傑偱乯偲偡傞丅
hh 偼丆2寘偺10恑悢偺帪乮00 偐傜
23 傑偱乯偲偡傞丅
mm 偼丆2寘偺10恑悢偺暘乮00 偐傜
59 傑偱乯偲偡傞丅
ss 偼丆2寘偺10恑悢偺昩乮00 偐傜
61 傑偱乯偲偡傞丅
zzz
偼丆乮壞帪娫傕峫椂偟偨乯帪娫懷偲偡傞丅昗弨帪娫懷偺抁弅宍偼丆儊僜僢僪
parse(21.3.31)
偵傛偭偰擣幆偡傞傕偺傪娷傓丅帪娫懷忣曬偑巊梡壜擻偱側偄側傜偽丆zzz
偼嬻棑丆偮傑傝丆偄偐側傞暥帤傕懚嵼偟側偄傕偺偲偡傞丅
yyyy 偼丆4寘偺10恑悢偺擭偲偡傞丅
toLocaleString(21.3.27)媦傃 toGMTString(21.3.28)傕嶲徠偺偙偲丅
偙偺儊僜僢僪偼丆Object(20.1.2)偺
儊僜僢僪 toString 傪抲偒姺偊傞丅
21.3.8 public boolean
equals(Object obj)
堷悢偑 null 偱側偔丆偙偺儊僜僢僪傪傕偮僆僽僕僃僋僩
Date 偲儈儕昩傑偱摨偠帪崗偺僆僽僕僃僋僩 Date
偱偁傞偲偒偵尷傝丆寢壥傪 true
偲偡傞丅偙偺傛偆偵丆擇偮偺僆僽僕僃僋僩 Date 偼丆儊僜僢僪
getTime(21.3.23)偱椉曽偑摨偠 long
抣傪曉偡偲偒偵尷傝丆摍偟偄偲偡傞丅
偙偺儊僜僢僪偼丆Object (20.1.3)
偺儊僜僢僪 equals 傪抲偒姺偊傞丅
21.3.9 public int
hashCode()
寢壥偼丆儊僜僢僪 getTime(21.3.23)
偑曉偡 long
抣傪32價僢僩偯偮敿暘偵偟偨擇偮偺抣偺XOR偲偡傞丅偮傑傝丆僴僢僔儏僐乕僪偼師偺幃偺抣偲偡傞丅
(int)(this.getTime()^(this.getTime()>>>32))偙偺儊僜僢僪偼丆
Object(20.1.4)偺儊僜僢僪 hashCode
傪抲偒姺偊傞丅21.3.10 public int
getYear()
曉媝抣偼丆抧堟帪娫懷偵偍偗傞僆僽僕僃僋僩 Date
偑昞尰偡傞帪崗偺弖娫傪娷傓擭丆枖偼偦偺帪崗偺弖娫偱巒傑傞擭偐傜1900傪堷偄偨抣偲偡傞丅
21.3.11 public void
setYear(int year)
僆僽僕僃僋僩 Date
傪廋惓偟偰丆抧堟帪娫懷偵偍偗傞丆巜掕偟偨擭偺丆曄峏慜偲摨偠寧丆擔丆帪丆暘媦傃昩偺帪崗傪昞尰偡傞丅乮傕偪傠傫丆椺偊偽擔晅偑2寧29擔偱擭偑偆傞偆擭偱側偄側傜偽丆怴偟偄擔晅偼3寧1擔偲偟偰張棟偡傞丅乯
21.3.12 public int
getMonth()
曉媝抣偼丆抧堟帪娫懷偵偍偗傞僆僽僕僃僋僩 Date
偑昞尰偡傞帪崗偺弖娫傪娷傓寧丆枖偼偦偺帪崗偺弖娫偱巒傑傞寧傪昞尰偡傞悢帤乮0
偐傜 11 傑偱乯偲偡傞丅
21.3.13
public void
setMonth(int month)
僆僽僕僃僋僩 Date
傪廋惓偟偰丆抧堟帪娫懷偵偍偗傞丆巜掕偟偨寧偺丆曄峏慜偲摨偠擭丆擔丆帪丆暘媦傃昩偺帪崗傪昞尰偡傞丅椺偊偽擔晅傪10寧31擔偲偟寧傪6寧偲愝掕偟偨側傜偽丆6寧偼30擔偩偗側偺偱丆怴偟偄擔晅偼7寧1擔偲偟偰張棟偡傞丅
21.3.14 public int
getDate()
曉媝抣偼丆抧堟帪娫懷偵偍偗傞僆僽僕僃僋僩 Date
偑昞尰偡傞帪崗偺弖娫傪娷傓寧偺擔晅丆枖偼偦偺帪崗偺弖娫偱巒傑傞寧偺擔晅傪昞尰偡傞悢帤乮1
偐傜 31 傑偱乯偲偡傞丅
21.3.15 public void
setDate(int date)
僆僽僕僃僋僩 Date
傪廋惓偟偰丆抧堟帪娫懷偵偍偗傞丆巜掕偟偨擔偺丆曄峏慜偲摨偠擭丆寧丆帪丆暘媦傃昩偺帪崗傪昞尰偡傞丅椺偊偽擔晅偑4寧30擔偱丆偟偐傕擔傪31偵愝掕偟偨側傜偽丆4寧偼30擔偩偗側偺偱丆怴偟偄擔晅偼5寧1擔偲偟偰張棟偡傞丅
21.3.16 public int
getDay()
曉媝抣乮0 = 擔梛擔丆1 = 寧梛擔丆2 =
壩梛擔丆3 = 悈梛擔丆4 = 栘梛擔丆5 =
嬥梛擔丆6 = 搚梛擔乯偼丆抧堟帪娫懷偵偍偗傞僆僽僕僃僋僩
Date
偑昞尰偡傞帪崗偺弖娫傪娷傓梛擔偺昞尰丆枖偼偦偺帪崗偺弖娫偱巒傑傞梛擔偺昞尰偲偡傞丅
21.3.17 public int
getHours()
曉媝抣偼丆抧堟帪娫懷偵偍偗傞僆僽僕僃僋僩 Date
偑昞尰偡傞帪崗偺弖娫傪娷傓擔偺帪丆枖偼偦偺帪崗偺弖娫偱巒傑傞擔偺帪傪昞尰偡傞悢帤乮0
偐傜 23 傑偱乯偲偡傞丅
21.3.18 public void
setHours(int hours)
僆僽僕僃僋僩 Date
傪廋惓偟偰丆抧堟帪娫懷偵偍偗傞丆巜掕偟偨帪偺丆曄峏慜偲摨偠擭丆寧丆擔丆暘媦傃昩偺帪崗傪昞尰偡傞丅
21.3.19 public int
getMinutes()
曉媝抣偼丆抧堟帪娫懷偵偍偗傞僆僽僕僃僋僩 Date
偑昞尰偡傞帪崗偺弖娫傪娷傓帪偺暘丆枖偼偦偺帪崗偺弖娫偱巒傑傞帪偺暘傪昞尰偡傞悢帤乮0
偐傜 59 傑偱乯偲偡傞丅
21.3.20 public void
setMinutes(int minutes)
僆僽僕僃僋僩 Date
傪廋惓偟偰丆抧堟帪娫懷偵偍偗傞丆巜掕偟偨暘偺丆曄峏慜偲摨偠擭丆寧丆擔丆帪媦傃昩偺帪崗傪昞尰偡傞丅
21.3.21 public int
getSeconds()
曉媝抣偼丆抧堟帪娫懷偵偍偗傞僆僽僕僃僋僩 Date
偑昞尰偡傞帪崗偺弖娫傪娷傓暘偺昩丆枖偼偦偺帪崗偺弖娫偱巒傑傞暘偺昩傪昞尰偡傞悢帤乮0
偐傜 61 傑偱乯偲偡傞丅
21.3.22 public void
setSeconds(int seconds)
僆僽僕僃僋僩 Date
傪廋惓偟偰丆抧堟帪娫懷偵偍偗傞丆巜掕偟偨昩偺丆曄峏慜偲摨偠擭丆寧丆擔丆帪媦傃暘偺帪崗傪昞尰偡傞丅
21.3.23 public long
getTime()
偙偺儊僜僢僪偼丆摿掕偺帪揰乮僌儕僯僢僠暯嬒帪1970擭1寧1擔00:00:00乯偐傜
Date 偺傕偭偰偄傞帪崗傑偱偺丆儈儕昩偱應偭偨嵎偺帪娫傪曉偡丅
21.3.24 public void
setTime(long time)
僆僽僕僃僋僩 Date
傪廋惓偟偰丆摿掕偺帪揰乮僌儕僯僢僠暯嬒帪1970擭1寧1擔 00:00:00乯偐傜
time 儈儕昩宱偨帪崗傪昞尰偡傞丅
21.3.25 public boolean
before(Date when)
僆僽僕僃僋僩 Date 偑昞尰偡傞帪崗偺弖娫偑丆when
偑昞尰偡傞帪崗偺弖娫傛傝傕尩枾偵帪娫揑偵慜偺偲偒偵尷傝丆寢壥傪
true 偲偡傞丅
21.3.26 public boolean
after(Date when)
僆僽僕僃僋僩 Date 偑昞尰偡傞帪崗偺弖娫偑 when
偑昞尰偡傞帪崗偺弖娫傛傝傕尩枾偵帪娫揑偵屻偺偲偒偵尷傝丆寢壥傪
true 偲偡傞丅
21.3.27 public String
toLocaleString()
僆僽僕僃僋僩 Date 傪幚憰偵埶懚偟偨宍幃偺 String
偵曄姺偡傞丅Java
傾僾儕働乕僔儑儞偺摦嶌拞偵偼丆棙梡幰偵撻愼傒偺偁傞宍幃偵曄姺偝傟傞傕偺偲偡傞丅ISO
C尵岅偺 strftime 娭悢偑僒億乕僩偡傞 %c
宍幃偲斾妑壜擻偲偡傞丅
儊僜僢僪 toString (21.3.7)媦傃 toGMTString (21.3.28)傕嶲徠偺偙偲丅
21.3.28 public String
toGMTString()
僆僽僕僃僋僩 Date 傪丆師偺挿偝23枖偼24偺 String
偵曄姺偡傞丅
"d mon yyyy hh:mm:ss GMT"偙偙偱丆奺昞尰偼師偺偲偍傝偲偡傞丅
1 偐傜 31
傑偱乯偲偡傞丅
Jan丆Feb丆Mar丆Apr丆May丆Jun丆Jul丆Aug丆Sep丆Oct丆Nov丆Dec乯偲偡傞丅
00 偐傜 23
傑偱乯偲偡傞丅
00 偐傜 59
傑偱乯偲偡傞丅
00 偐傜 61
傑偱乯偲偡傞丅
GMT乭偲偡傞丅
儊僜僢僪 toString (21.3.7)媦傃 toLocaleString
(21.3.27)傕嶲徠偺偙偲丅
21.3.29 public int
getTimezoneOffset()
偙偺儊僜僢僪偼丆僆僽僕僃僋僩 Date 偑昞尰偡傞帪崗偵懳墳偡傞丆UTC
偲抧堟帪娫懷偲偺暘扨埵偱應偭偨嵎傪曉偡丅
椺偊偽丆儅僒僠儏乕僙僢僣偼僌儕僯僢僠偐傜5帪娫偩偗惣偺偨傔丆師偺偲偍傝偲偡傞丅
new Date(96, 2, 14).getTimezoneOffset() 偼 300傪曉偡1996擭2寧14擔偵偼昗弨帪娫乮搶晹昗弨帪娫乯傪巊梡偟偰偄傞偨傔丆偙偺偲偍傝偲偡傞丅偙偺昗弨帪娫偼 UTC 偐傜5帪娫偢傟偰偄傞丅偟偐偟丆
new Date(96, 5, 1).getTimezoneOffset() 傪 240 傪曉偡1996擭5寧1擔偵偼壞帪娫乮搶晹壞帪娫乯傪巊梡偟偰偄傞偨傔丆偙偺偲偍傝偲偡傞丅偙偺壞帪娫偼 UTC 偲4帪娫偟偐偢傟偰偄側偄丅 偙偺儊僜僢僪偼師偺寁嶼傪偟偨傕偺偲摨偠寢壥傪梌偊傞丅
(this.getTime() - UTC(this.getYear(),
this.getMonth(),
this.getDate(),
this.getHours(),
this.getMinutes(),
this.getSeconds())) / (60 * 1000)
21.3.30 public static long
UTC(int year, int month, int date,
int hours, int minutes, int seconds)
俇屄偺堷悢(21.3.5)傪傕偭偨
Date
僐儞僗僩儔僋僞偲摨條偵丆擭丆寧丆擔丆帪丆暘媦傃昩偲偟偰堷悢傪夝庍偡傞偑丆抧堟帪娫懷偱偼側偔
UTC 偲偟偰夝庍偡傞丅巜掕偟偨帪崗傪丆摿掕偺帪揰乮僌儕僯僢僠暯嬒帪
1970擭1寧1擔 00:00:00乯偐傜儈儕昩扨埵偱應偭偨嵎傪昞尰偟曉偡丅
21.3.31 public static long
parse(String s)
throws
IllegalArgumentException
暥帤楍 s
傪擔帪忣曬偲偟偰夝庍偡傞丅夝庍偑惉岟偟偨応崌偵偼丆摿掕偺帪揰乮僌儕僯僢僠暯嬒帪
1970擭1寧1擔
00:00:00乯偐傜儈儕昩扨埵偱應偭偨嵎傪曉偡丅夝庍偑幐攕偟偨応崌偵偼丆IllegalArgumentException
偑搳偘傜傟傞丅
暥帤楍 s
偼丆娭怱偺偁傞僨乕僞傪扵偟側偑傜丆嵍偐傜塃傊偲張棟偝傟傞丅
s 撪偵偁傞 ASCII暥帤偺娵妵屖 ( 媦傃 )
撪偼柍帇偡傞丅偦傟埲奜偺 s 撪偱嫋偝傟傞暥帤偼丆師偺 ASCII
暥帤媦傃嬻敀椶(20.5.19)偩偗偲偡傞丅
abcdefghijklmnopqrstuvwxyz ABCDEFGHIJKLMNOPQRSTUVWXYZ 0123456789,+-:/
+ 枖偼 -
偑懚嵼偟丆偟偐傕擭偑婛偵暘偐偭偰偄傟偽丆偦偺悢帤偼帪娫懷偺僆僼僙僢僩傪昞偡丅偦偺悢帤偑24傛傝傕彫偝偗傟偽丆帪娫扨埵偱應偭偨僆僼僙僢僩偲偡傞丅24埲忋偺応崌偵偼丆暘扨埵偱應偭偨僆僼僙僢僩偲尒側偟丆嬫愗傝側偟偺24帪娫宍幃偱昞尰偡傞丅+
偑愭峴偡傞応崌偵偼搶岦偒偺僆僼僙僢僩傪丆-
偑愭峴偡傞応崌偵偼惣岦偒偺僆僼僙僢僩傪堄枴偡傞丅帪娫懷僆僼僙僢僩偼忢偵
UTC乮僌儕僯僢僠乯傪婎弨偲偡傞丅偦偙偱椺偊偽丆暥帤楍偵 -5
偑尰傟傟偽丆乬僌儕僯僢僠偺5帪娫偩偗惣乭傪堄枴偟丆+0430
側傜偽乬僌儕僯僢僠偺4帪娫30暘偩偗搶乭傪堄枴偡傞丅幚幙忋堄枴偼側偄偑丆GMT丆UT
枖偼 UTC 傪暥帤楍偵婰弎偟偰傕傛偄丅椺偊偽丆GMT-5
枖偼 utc+0430 側偳偲側傞丅
0
偐傜 11 傑偱偺斖埻偵偡傞偨傔偵丆1
偩偗堷偒嶼偡傞乯丅偨偩偟丆婛偵寧偑暘偐偭偰偄傞応崌偵偼丆擔偲尒側偡丅
AM
偲堦抳偡傞扨岅偼丆柍帇偡傞乮偨偩偟丆帪偑暘偐傜側偐偭偨応崌丆枖偼帪偵偁偨傞悢帤偑
1 傛傝彫偝偄偐 12
傛傝戝偒偄応崌偵偼丆峔暥夝愅偼幐攕偡傞乯丅
PM
偲堦抳偡傞扨岅偑懚嵼偟偨応崌偵偼丆婛偵暘偐偭偰偄傞帪偵12傪壛偊傞乮偨偩偟丆帪偑暘偐傜側偐偭偨応崌丆枖偼帪偵偁偨傞悢帤偑
1 傛傝彫偝偄偐 12
傛傝戝偒偄応崌偵偼丆峔暥夝愅偼幐攕偡傞乯丅
SUNDAY丆MONDAY丆TUESDAY丆WEDNESDAY丆THURSDAY丆FRIDAY
枖偼 SATURDAY
偺擟堄偺愙摢帿偲堦抳偡傞扨岅偼丆柍帇偡傞丅椺偊偽丆sat丆Friday丆TUE
媦傃 Thurs 偼柍帇偡傞丅
JANUARY丆FEBRUARY丆
MARCH丆APRIL丆MAY丆JUNE丆JULY丆AUGUST丆SEPTEMBER丆OCTOBER丆NOVEMBER
枖偼 DECEMBER
偺擟堄偺愙摢帿偲堦抳偡傞扨岅偼丆偙偙偱梌偊傜傟偨弴斣偱丆寧傪婰弎偟偰偄傞偲尒側偟丆悢帤乮0
偐傜 11
傑偱乯偵曄姺偡傞丅椺偊偽丆aug丆Sept丆april
媦傃 NOV 偼丆寧偲偟偰擣幆偡傞丅Ma
傕寧偲擣幆偡傞偑丆弴斣偐傜 MARCH 偲偟偰擣幆偟 MAY
偲偼尒側偝側偄丅
GMT丆UT 枖偼
UTC 偲堦抳偡傞扨岅偼 UTC 偲偟偰嶲徠偟張棟偡傞丅
EST丆CST丆MST
枖偼 PST
偲堦抳偡傞扨岅偼丆偦傟偧傟僌儕僯僢僠偐傜5帪娫丆6帪娫丆7帪娫枖偼8帪娫偩偗惣偺杒傾儊儕僇帪娫懷傪嶲徠偡傞偲擣幆偡傞丅戝暥帤丒彫暥帤傪嬫暿偣偢偵丆EDT丆CDT丆MDT
枖偼 PDT
偲堦抳偡傞扨岅偼丆偦傟偧傟慜弎偺帪娫懷偺壞帪娫偺応崌傪嶲徠偡傞偲擣幆偡傞丅乮彨棃揑偵偼丆偙偺曽朄偼懠偺帪娫懷傪擣幆偡傞傛偆夵掶偝傟傞偐傕抦傟側偄丅乯
s
傪専嵏偟偨傜丆師偺擇偮偺偄偢傟偐偺曽朄偱帪崗偵曄姺偡傞丅帪娫懷枖偼帪娫懷僆僼僙僢僩傪擣幆偟偨傜丆擭丆寧丆擔丆帪丆暘媦傃昩偼
UTC (21.3.30)偱夝庍偟丆帪娫懷僆僼僙僢僩傪揔梡偡傞丅偦傟埲奜偺応崌偵偼丆擭丆寧丆擔丆帪丆暘媦傃昩偼抧堟帪娫懷偱夝庍偡傞丅
java.util.DictionaryDictionary 偼丆僉乕(keys) 傪梫慺
(elements)
偵娭楢偯偗傞僆僽僕僃僋僩偲偡傞丅偡傋偰偺僉乕媦傃梫慺偼僆僽僕僃僋僩偲偡傞丅偳偺堦偮偺
Dictionary
偵偍偄偰傕丆偡傋偰偺僉乕偼懡偔偲傕堦偮偺梫慺偲娭楢晅偗傜傟傞丅Dictionary
媦傃僉乕傪梌偊傟偽丆懳墳偡傞梫慺傪扵偡偙偲偑偱偒傞丅
public abstract classDictionary{ abstract public intsize(); abstract public booleanisEmpty(); abstract public Objectget(Object key) throws NullPointerException; abstract public Objectput(Object key, Object element) throws NullPointerException; abstract public Objectremove(Object key) throws NullPointerException; abstract public Enumerationkeys(); abstract public Enumerationelements(); }
equals
(20.1.3)
Dictionary
21.4.1 abstract public int
size()
儊僜僢僪 size
偼丆偙偺帿彂撪偺僄儞僩儕乮憡堎側傞僉乕乯偺悢傪曉偡丅
21.4.2 abstract public boolean
isEmpty()
儊僜僢僪 isEmpty
偼丆偙偺帿彂偑堦偮傕僄儞僩儕傪傕偭偰偄側偄偲偒偵尷傝丆true
傪曉偡丅
21.4.3 abstract public Object
get(Object key)
throws
NullPointerException
儊僜僢僪 get 偼丆偙偺帿彂偑巜掕偟偨 key
偵懳偡傞僄儞僩儕傪娷傔偽丆娭楢偡傞梫慺傪曉偡丅偦傟埲奜偺応崌偵偼丆null
傪曉偡丅
key 偑 null
側傜偽丆NullPointerException 偑搳偘傜傟傞丅
21.4.4 abstract public Object
put(Object key, Object element)
throws
NullPointerException
帿彂偑巜掕偟偨 key
偺僄儞僩儕傪婛偵娷傫偱偄傟偽丆偦偺僄儞僩儕傪怴偟偄 element
傪娷傓傛偆偵廋惓偟丆帿彂拞偺 key
偵懳墳偡傞埲慜偺梫慺傪曉偡丅
帿彂偑巜掕偟偨 key 偺僄儞僩儕傪娷傑側偗傟偽丆偦偺
key 媦傃 element
偺偨傔偺僄儞僩儕傪嶌惉偟丆null 傪曉偡丅
key 枖偼 element 偑 null
側傜偽丆NullPointerException 偑搳偘傜傟傞丅
21.4.5 abstract public Object
remove(Object key)
throws
NullPointerException
儊僜僢僪 remove 偼丆帿彂偐傜堦偮偺僄儞僩儕傪庢傝彍偔丅
帿彂偑巜掕偟偨 key
偺僄儞僩儕傪娷傔偽丆僄儞僩儕傪帿彂偐傜庢傝彍偒丆偦偺屻偵 key
偵懳墳偟偨梫慺傪曉偡丅
帿彂偑巜掕偟偨 key
偵懳墳偡傞僄儞僩儕傪娷傑側偗傟偽丆null 傪曉偡丅
key 偑 null
側傜偽丆NullPointerException 偑搳偘傜傟傞丅
21.4.6 abstract public
Enumeration
keys()
儊僜僢僪 keys 偼丆帿彂偑娷傓僄儞僩儕偵懳偡傞偡傋偰偺
key 傪惗惉偡傞 Enumeration(21.1)傪曉偡丅
21.4.7 abstract public
Enumeration
elements()
儊僜僢僪 elements
偼丆帿彂撪偺僄儞僩儕偵娷傑傟傞偡傋偰偺梫慺傪惗惉偡傞
Enumeration(21.1)傪曉偡丅
java.util.HashtableHashtable 偼丆拪徾僋儔僗 Dictionary(21.4)偺幚憰偲偟丆偄偔偮偐偺婡擻傪捛壛偡傞丅
public classHashtableextends Dictionary implements Cloneable { publicHashtable(int initialCapacity, float loadFactor); publicHashtable(int initialCapacity); publicHashtable(); public StringtoString(); public Objectclone(); public intsize(); public booleanisEmpty(); public Objectget(Object key) throws NullPointerException; public Objectput(Object key, Object value) throws NullPointerException; public Objectremove(Object key) throws NullPointerException; public Enumerationkeys(); public Enumerationelements(); public booleancontains(Object value); public booleancontainsKey(Object key); protected voidrehash(); public voidclear(); }
Hashtable
偼岠棪偵塭嬁傪梌偊傞擇偮偺僷儔儊乕僞丆梕検(capacity) 媦傃
晧壸學悢(load factor) 傪傕偮丅晧壸學悢偼丆0.0 偐傜
1.0
傑偱偺娫偵偁傞偙偲偑朷傑偟偄丅僴僢僔儏昞偺僄儞僩儕悢偑晧壸學悢媦傃尰嵼偺梕検偺愊傪挻偊偨偲偒丆僴僢僔儏昞偺梕検傪儊僜僢僪
rehash
傪巊偭偰憹壛偡傞丅晧壸學悢偑戝偒偄傎偳丆1搙偺嶲徠偵偐偐傞梊憐帪娫偼戝偒偔側傞偑丆儊儌儕偺岠棪揑巊梡傪壜擻偲偡傞丅懡偔偺僄儞僩儕傪
Hashtable
偵嶌惉偡傞昁梫偑偁傟偽丆廫暘側梕検傪庢偭偰昞傪嶌惉偟偰偍偔偙偲偵傛偭偰丆昞傪戝偒偔偡傞偺偵昁梫偲側傞帺摦嵞僴僢僔儏偺幚峴傪昞偵擟偣傞傛傝傕岠棪揑偵僄儞僩儕傪憓擖偡傞偙偲偑壜擻偲側傞丅
21.5.1 public
Hashtable(int initialCapacity, float
loadFactor)
偙偺僐儞僗僩儔僋僞偼丆怴偨偵惗惉偟偨僆僽僕僃僋僩 Hashtable
傪弶婜壔偟丆梕検傪 initialCapacity 偲偟丆晧壸學悢傪
loadFactor 偲偡傞丅嵟弶偼丆僴僢僔儏昞偵僄儞僩儕偼懚嵼偟側偄丅
21.5.2 public
Hashtable(int initialCapacity)
偙偺僐儞僗僩儔僋僞偼丆怴偨偵惗惉偟偨僆僽僕僃僋僩 Hashtable
傪弶婜壔偟丆梕検傪 initialCapacity 偲偟丆晧壸學悢傪
0.75 偲偡傞丅嵟弶偼丆僴僢僔儏昞偵僄儞僩儕偼懚嵼偟側偄丅
21.5.3 public
Hashtable()
偙偺僐儞僗僩儔僋僞偼丆怴偨偵惗惉偟偨僆僽僕僃僋僩 Hashtable
傪弶婜壔偟丆晧壸學悢傪 0.75
偲偡傞丅嵟弶偼丆僴僢僔儏昞偵僄儞僩儕偼懚嵼偟側偄丅
21.5.4 public String
toString()
僋儔僗 Hashtable 偼丆攇妵屖偱埻傑傟丆ASCII 暥帤乬,
乭乮僐儞儅偲嬻敀乯偱嬫愗傜傟偨僄儞僩儕廤崌偲偟偰偺暥帤楍宍幃偱昞尰偡傞丅奺乆偺僄儞僩儕偼丆僉乕丆摍崋媦傃娭楢偡傞梫慺偲偟偰昞尰偡傞丅儊僜僢僪
toString 偼丆僉乕媦傃梫慺傪暥帤楍偵曄姺偡傞偨傔偵巊梡偡傞丅
偙偺儊僜僢僪偼丆Object 偺儊僜僢僪 toString(21.2.3)傪抲偒姺偊傞丅
21.5.5 public Object
clone()
Hashtable
偺僐僺乕傪嶌惉偟丆曉偡丅僴僢僔儏昞偺偡傋偰偺峔憿偦偺傕偺傪僐僺乕偟丆僉乕媦傃梫慺偼僐僺乕偝傟側偄丅
偙偺儊僜僢僪偼丆Object 偺儊僜僢僪 clone(21.2.6)傪抲偒姺偊傞丅
21.5.6 public int
size()
僋儔僗 Dictionary 偺儊僜僢僪 size(21.4.1)傪幚憰偡傞丅
21.5.7 public boolean
isEmpty()
僋儔僗 Dictionary 偺儊僜僢僪 isEmpty (21.4.2)傪幚憰偡傞丅
21.5.8 public Object
get(Object key)
僋儔僗 Dictionary 偺儊僜僢僪 get(21.4.3)傪幚憰偡傞丅
21.5.9 public Object
put(Object key, Object value)
僋儔僗 Dictionary 偺儊僜僢僪 put(21.4.4)傪幚憰偡傞丅
21.5.10 public Object
remove(Object key)
僋儔僗 Dictionary 偺儊僜僢僪 remove (21.4.5)傪幚憰偡傞丅
21.5.11 public Enumeration
keys()
僋儔僗 Dictionary 偺儊僜僢僪 keys(21.4.6)傪幚憰偡傞丅
21.5.12 public Enumeration
elements()
僋儔僗 Dictionary 偺儊僜僢僪 elements(21.4.7)傪幚憰偡傞丅
21.5.13 public boolean
contains(Object value)
偙偺 Hashtable 偑丆儊僜僢僪 equals(20.1.3)偵傛偭偰丆偦偺梫慺偑
value
偲摍偟偄偲敾掕偝傟傞彮側偔偲傕堦偮偺僄儞僩儕傪娷傓偲偒偵尷傝丆寢壥傪
true 偲偡傞丅
21.5.14 public boolean
containsKey(Object key)
Hashtable 偑丆儊僜僢僪 equals(20.1.3)偵傛偭偰丆僉乕傪 key
偲摍偟偄偲敾掕偡傞僄儞僩儕傪娷傓偲偒偵尷傝丆寢壥傪 true
偲偡傞丅偮傑傝丆偙偺儊僜僢僪偼丆師偺幃偲摨偠寢壥傪曉偡傕偺偲偡傞丅
get(key) != null
21.5.15 protected void
rehash()
Hashtable
偑僄儞僩儕偵揔墳偟丆傛傝岠壥揑偵傾僋僙僗傪峴側偆偨傔偵丆梕検偺憹壛媦傃撪晹峔憿偺嵞峔惉傪峴偆傕偺偲偡傞丅
21.5.16 public void
clear()
儊僜僢僪 clear 偼丆偡傋偰偺僄儞僩儕傪偙偺
Hashtable 偐傜庢傝彍偔丅
java.util.PropertiesProperties
昞偼丆擇偮偺婡擻奼挘傪傕偪丆僉乕媦傃梫慺傪暥帤楍偲偡傞偲偄偆惂栺傪傕偮丆Hashtable
偺堦庬偲偡傞丅傑偢丆擖椡僗僩儕乕儉偐傜僄儞僩儕傪昞偵撉傒崬傓儊僜僢僪偑懚嵼偟丆昞撪偺偡傋偰偺僄儞僩儕傪弌椡僗僩儕乕儉傊彂偒弌偡偨傔偺儊僜僢僪偑懚嵼偡傞丅師偵丆Properties
昞偼丆僨僼僅儖僩抣傪採嫙偡傞懠偺 Properties
昞傪嶲徠偟偰傕傛偄丅儊僜僢僪 getProperty 偼丆儊僜僢僪
get(21.4.3)偲傛偔帡偰偄傞偑丆偁傞僄儞僩儕偑昞拞偵尒偮偐傜側偄応崌丆僨僼僅儖僩昞傪扵偡乮偦偺僨僼僅儖僩昞偦偺傕偺偼丆懠偺僨僼僅儖僩昞傪嶲徠偟偰傛偔丆弴師嵞婣揑偵嶲徠偟偰傕傛偄乯丅
public classPropertiesextends Hashtable { protected Propertiesdefaults; publicProperties(); publicProperties(Properties defaults); public StringgetProperty(String key); public StringgetProperty(String key, String defaultValue); public EnumerationpropertyNames(); public voidload(InputStream in) throws IOException; public voidsave(OutputStream out, String header); public voidlist(PrintStream out); }
21.6.1 protected Properties
defaults;
defaults 僼傿乕儖僪偑 null 偱側偗傟偽丆偙偺
Properties 昞偵懳偟偰僨僼僅儖僩抣傪採嫙偡傞偺偼懠偺
Properties 昞偲偡傞丅
21.6.2 public
Properties()
偙偺僐儞僗僩儔僋僞偼丆怴偟偔惗惉偡傞 Properties
昞傪弶婜壔偟丆僨僼僅儖僩昞傪傕偨側偄丅嵟弶偼怴偟偔惗惉偟偨昞偵偼丆僄儞僩儕偑懚嵼偟側偄傕偺偲偡傞丅
21.6.3 public
Properties(Properties defaults)
偙偺僐儞僗僩儔僋僞偼丆怴偟偔惗惉偡傞 Properties
傪弶婜壔偟丆僨僼僅儖僩昞傪 defaults 偲偡傞丅堷悢
defaults 偼 null
偱偁偭偰傕傛偄丅偙偺応崌偵偼丆怴偟偔惗惉偟偨 Properties
昞偼僨僼僅儖僩昞傪傕偨側偄丅嵟弶偼怴偟偔惗惉偟偨昞偵偼丆僄儞僩儕偑懚嵼偟側偄丅
21.6.4 public String
getProperty(String key)
Properties 昞撪偵僉乕偲偟偰 key
傪傕偮僄儞僩儕偑懚嵼偡傟偽丆偦傟偵娭楢偡傞梫慺傪曉偡丅偦傟埲奜偺応崌偵偼丆偙偺
Properties
昞偑僨僼僅儖僩昞傪傕偰偽丆偦偺僨僼僅儖僩昞偺儊僜僢僪
getProperty 偑曉偡抣傪曉偡丅偦傟埲奜偺応崌偵偼
null 傪曉偡丅
21.6.5 public String
getProperty(String key,
String
defaultValue)
Properties 昞偺拞偵 key
偵懳墳偡傞僄儞僩儕偑懚嵼偡傟偽丆懳墳偡傞梫慺傪曉偡丅偦傟埲奜偺応崌偵偼丆偙偺
Properties 昞偑僨僼僅儖僩昞傪傕偰偽丆儊僜僢僪
getProperty
偺曉媝抣傪曉偡丅偦傟埲奜偺応崌偵偼丆defaultValue 傪曉偡丅
21.6.6 public Enumeration
propertyNames()
偙偺 Properties
昞偑娭楢偡傞梫慺傪採嫙偱偒傞偡傋偰偺僉乕傪惗惉偡傞
Enumeration(21.1)傪曉偡丅偙偺
Properties 偑丆僨僼僅儖僩昞(21.6.1)傪傕偰偽丆僨僼僅儖僩昞偑傕偮僄儞僩儕偺僉乕傕
Enumeration
偑採嫙偟丆偝傜偵僨僼僅儖僩昞偑懠偺僨僼僅儖僩昞傪傕偮応崌偵傕嵞婣揑偵側偭偰偄傞傕偺偲偡傞丅偨偩偟丆偄偐側傞僉乕傕1搙埲忋
Enumeration 偑採嫙偡傞偙偲偼側偄丅
21.6.7 public void
load(InputStream in) throws IOException
懏惈乮僉乕偲梫慺偲偺懳乯傪擖椡僗僩儕乕儉偐傜師偺傛偆偵撉傒崬傒丆偙偺
Properties 昞偵捛壛偡傞丅
Runtime.getRuntime().getLocalizedInputStream(in)
Runtime 偺儊僜僢僪 getLocalizedInputStream(20.16.15)傪嶲徠偺偙偲丅
偡傋偰偺懏惈偼丆擖椡僗僩儕乕儉偺堦峴傪愯傔傞丅奺峴偼丆峴廔抂婰崋偱嬫愗傜傟傞乮\n丆\r
枖偼
\r\n乯丅擖椡僗僩儕乕儉偐傜偺峴偼丆偦偺擖椡僗僩儕乕儉忋偱僼傽僀儖偺嵟屻偵摓払偡傞傑偱張棟偝傟傞丅
嬻敀椶(20.5.19)
偩偗傪娷傓峴丆枖偼嵟弶偺旕嬻敀椶偑ASCII偺 # 庒偟偔偼
! 偲偡傞峴偼丆柍帇偡傞乮偮傑傝丆# 枖偼
! 偼拲庍峴傪帵偡乯丅
嬻峴枖偼拲庍峴傪彍偔偡傋偰偺峴偼丆昞偵壛偊傞堦偮偺懏惈傪婰弎偡傞乮偨偩偟丆峴偑
\
偱廔偭偰偄傞応崌偼丆師偵帵偡偲偍傝偦偺峴偺師偺峴傪楢懕峴偲偟偰埖偆乯丅僉乕偼丆嵟弶偺旕嬻敀椶偐傜嵟弶偺ASCII暥帤偺
21.6.8
偙偺
僿僢僟堷悢偑
師偵丆ASCII
偝傜偵偙偺 21.6.9
偙偺
偙偺捠抦婡峔偼僗儗僢僪(20.20)偺張棟偲偼壗偺娭學傕側偔丆僋儔僗
擇偮偺娤應幰偼儊僜僢僪 21.7.1
娤應幰 21.7.2
娤應幰 21.7.3
偡傋偰偺娤應幰傪偙偺僆僽僕僃僋僩 21.7.4
偙偺僆僽僕僃僋僩 21.7.5
僆僽僕僃僋僩 21.7.6
僆僽僕僃僋僩 21.7.7
偙偺僆僽僕僃僋僩 21.7.8
偙偺僆僽僕僃僋僩 21.7.9
偙偺僆僽僕僃僋僩 21.8.1
僆僽僕僃僋僩
僋儔僗 21.9.1
媅帡棎悢敪惗婍偺忬懺傪曐帩偡傞偨傔偵丆儊僜僢僪 21.9.2
師偵儊僜僢僪 21.9.3
儊僜僢僪 21.9.4
偙偺僐儞僗僩儔僋僞偼丆怴偟偔惗惉偡傞 21.9.5
偙偺僐儞僗僩儔僋僞偼丆怴偟偔惗惉偟偨嶌傜傟偨 21.9.6
儊僜僢僪
21.9.7
僋儔僗
21.9.8
儊僜僢僪
21.9.9
儊僜僢僪
21.9.10
儊僜僢僪
21.9.11
public double nextDouble() {
return (((long)next(26) << 27) + next(27))
/ (double)(1L << 53);
}
21.9.12
儊僜僢僪
21.10.1
偙偺僐儞僗僩儔僋僞偼丆怴偟偔惗惉偟偨 21.10.2
偙偺僐儞僗僩儔僋僞偼丆怴偟偔惗惉偟偨 21.10.3
偙偺僐儞僗僩儔僋僞偼丆怴偟偔惗惉偟偨 21.10.4
尰嵼埵抲傛傝愭偺楍撪偵彮側偔偲傕堦偮偺僩乕僋儞偑懚嵼偡傞偲偒偵尷傝丆寢壥傪
21.10.5
尰嵼埵抲傛傝愭偺楍撪偺師偺僩乕僋儞傪曉偡丅尰嵼埵抲偼丆擣幆偝傟偨僩乕僋儞傪墇偊偰師偵恑傓丅
21.10.6
嵟弶偵丆 21.10.7
偙偺儊僜僢僪偼丆 21.10.8
偙傟偼丆 21.10.9
尰嵼偺嬫愗傝暥帤偺廤崌傪巊偄丆尰嵼埵抲傛傝愭偺楍撪偺僩乕僋儞悢傪曉偡丅尰嵼埵抲偼恑傔側偄丅
21.11.1
撪晹揑偵丆 21.11.2
偙偺僼傿乕儖僪偼丆僆僽僕僃僋僩 21.11.3
儊僜僢僪 21.11.4
偙偺僐儞僗僩儔僋僞偼丆怴偟偔惗惉偟偨 21.11.5
偙偺僐儞僗僩儔僋僞偼丆怴偟偔惗惉偟偨 21.11.6
偙偺僐儞僗僩儔僋僞偼丆怴偟偔惗惉偟偨 21.11.7
偙偺
21.11.8
偙偺儊僜僢僪偼丆 21.11.9
21.11.10
摿掕偺
21.11.11
21.11.12
21.11.13
21.11.14
21.11.15
21.11.16
21.11.17
21.11.18
21.11.19 21.11.20
21.11.21
21.11.22
21.11.23
21.11.24
21.11.25
21.11.26
21.11.27
21.11.28
21.11.29
21.11.30
21.12.1
21.12.2
僗僞僢僋偑嬻側傜偽丆 21.12.3
僗僞僢僋偑嬻側傜偽丆 21.12.4
僗僞僢僋偑偄偐側傞崁栚傕娷傑側偄偲偒偵尷傝丆寢壥傪 21.12.5
僆僽僕僃僋僩
21.13.1
偙偺僐儞僗僩儔僋僞偼丆怴偟偔惗惉偟偨 21.14.1
偙偺僐儞僗僩儔僋僞偼丆怴偟偔惗惉偟偨 21.14.2
偙偺僐儞僗僩儔僋僞偼丆怴偟偔惗惉偟偨
=丆:
枖偼嬻敀椶偺捈慜傑偱偺峴拞偺偡傋偰偺暥帤偵傛偭偰峔惉偡傞丅僉乕偺屻偺嬻敀椶偼丆僗僉僢僾偡傞丅僉乕偺屻偺嵟弶偺旕嬻敀椶偑
= 枖偼 :
側傜偽丆偙偺暥帤偼柍帇偟丆偦偺屻偺擟堄偺嬻敀椶傕僗僉僢僾偡傞丅偦偺峴偺巆傝偡傋偰偺暥帤偑丆娭楢偡傞梫慺楍偺堦晹偲側傞丅梫慺楍拞乮偨偩偟丆僉乕偱偼側偄乯偺ASCII僄僗働乕僾楍
\t丆\n丆\r丆\\丆\"丆\'丆\
乮僶僢僋僗儔僢僔儏媦傃僗儁乕僗乯媦傃
\uxxxx
偼擣幆偟丆堦偮偺暥帤偵曄姺偡傞丅偝傜偵丆峴偺嵟屻偺暥帤偑 \
偱偁傞応崌丆師偺峴偼尰嵼偺峴偺懕偒偲偡傞丅\ 媦傃峴廔抂婰岪w)
f$!
OC1$K"Truth"
傪丆娭楢偡傞梫慺偲偟偰 "Beauty" 傪昞偡丅
Truth Beauty
Truth = Beauty
Truth:Beauty
Truth :Beauty
師偺俁峴偼堦偮偺懏惈傪昞偡丅
fruits apple, banana, pear, \
cantaloupe, watermelon, \
kiwi, mango
僉乕傪 "fruit" 偲偟丆娭楢偡傞梫慺傪師偺偲偍傝偲偡傞丅
"apple, banana, pear, cantaloupe, watermelon, kiwi, mango"
奺乆偺 \
偺慜偵堦偮偺僗儁乕僗偑弌尰偟丆嵟廔揑側寢壥偵偼奺僐儞儅偺屻偵堦偮偺嬻敀偑弌尰偡傞揰偵拲堄偡傞偙偲丅\
婰崋丆峴廔抂婰崋媦傃峴摢偺嬻敀椶偼扨偵幪偰丆堦偮枖偼偦傟埲忋偺懠偺暥帤偵抲偒姺傢傞偙偲偼
側偄(not)丅
cheeses
僉乕傪 "cheeses" 偲偟丆娭楢偡傞梫慺偼嬻暥帤楍偲偡傞丅
public void
save(OutputStream out, String header)Properties
昞偺偡傋偰偺懏惈乮僉乕媦傃梫慺偺懳乯傪師偺弌椡僗僩儕乕儉傊彂偒弌偡丅
Runtime.getRuntime().getLocalizedOutputStream(out)
偦偺嵺偺弌椡宍幃偼 Properties 昞偵儊僜僢僪 load(21.6.7)傪巊偭偰丆撉傒崬傓偺偵揔偟偨宍幃偲偡傞丅Runtime
偺儊僜僢僪 getLocalizedOutputStream(20.16.16)傪嶲徠偺偙偲丅
Properties
昞偺丆僨僼僅儖僩昞偐傜偺懏惈偼偙偺儊僜僢僪偱偼彂偒弌偝 側偄(not)
傕偺偲偡傞丅null 偱側偗傟偽丆嵟弶偵ASCII#
暥帤丆僿僢僟偺暥帤楍媦傃夵峴傪弌椡僗僩儕乕儉偵彂偒弌偡丅偙偺傛偆偵
header 偼摿掕偺拲庍偲偟偰棙梡偱偒傞丅# 暥帤丆乮尰嵼帪崗傪 Date 偺儊僜僢僪
toString(21.3.7)偵傛傝惗惉偟偨偐偺傛偆側乯尰嵼偺擔晅偲帪崗媦傃夵峴偐傜側傞拲庍峴傪忢偵彂偒弌偡丅Properties
昞偺偡傋偰偺僄儞僩儕傪侾峴偢偮彂偒弌偡丅奺乆偺僄儞僩儕偵懳偟偰僉乕暥帤楍傪彂偒丆ASCII=
暥帤傪彂偒丆偝傜偵娭楢偡傞梫慺暥帤楍傪彂偔丅梫慺暥帤楍偺奺乆偺暥帤傪僄僗働乕僾僔乕働儞僗偲偟偰婰弎偡傋偒偐偳偆偐挷傋傞丅ASCII\
暥帤丆僞僽丆夵峴丆暅婣偼丆奺乆\\丆\t丆\n丆\r
偲彂偔丅\u0020 傛傝彫偝偄暥帤媦傃 \u007E
傛傝戝偒偄暥帤偼丆乮嬊強壔偝傟偨弌椡僗僩儕乕儉偺昁梫惈偵埶懚偟偰乯\uxxxx
偲偟偰彂偔丅偨偩偟丆xxxx
偼揔愗側16恑抣偲偡傞丅搑拞媦傃峴枛偺嬻敀偱偼側偔丆峴摢偺嬻敀暥帤偼丆慜偵
\ 傪晅偗偰彂偒弌偡丅
public void
list(PrintStream out)Properties 昞偺懏惈乮僉乕媦傃梫慺偺懳乯傪丆儊僜僢僪
save
偺弌椡傛傝傕僨僶僌偱曋棙偲側傞傛偆偵丆婔暘徣棯偟偨宍偱弌椡僗僩儕乕儉
out
傊彂偒弌偡丅僿僢僟偼彂偒弌偝偢丆40暥帤傛傝挿偄梫慺抣偼嵟弶偺37暥帤偵愗傝幪偰丆"..."傪晅偗壛偊傞丅偙傟偵傛傝丆僉乕偺柤慜偑偦傟傎偳挿偔側偗傟偽丆奺乆偺懏惈傪暔棟揑側弌椡憰抲偺侾峴偺椞堟偵崌傢偣傞壜擻惈偑惗偢傞丅
21.7 僋儔僗
僋儔僗 java.util.ObservableObservable 偺奺僀儞僗僞儞僗偼偡傋偰丆僆僽僕僃僋僩
Observable
偵廳梫側曄壔偑偁偭偨応崌偵偼偄偮傕捠抦傪庴偗傞乬娤應幰乭偲屇傇廤崌傪曐帩偟偰偄傞丅娤應幰偼丆僀儞僞僼僃乕僗
Observer(21.8)傪幚憰偡傞擟堄偺僆僽僕僃僋僩偱偁偭偰傛偄丅
Object(20.1)偺
wait 媦傃 notify
偺婡峔偲偼姰慡偵堎側傞偙偲偵拲堄偡傞偙偲丅
public class
娤應壜擻側僆僽僕僃僋僩傪怴偟偔惗惉偡傞偲偒丆偦偺娤應幰偺廤崌偼嬻偲偡傞丅
Observable {
public void addObserver(Observer o);
public void deletteObserver(Observe o);
public void deleteObservers();
public int countObservers();
public void notifyObservers();
public void notifyObservers(Object arg);
protected void setChanged();
protected void clearChanged();
public boolean hasChanged();
}
equals(20.1.3)偑 true
傪曉偡偲偒偵尷傝丆摨偠偲傒側偡丅
public void
addObserver(Observer o)o 偑丆偙偺僆僽僕僃僋僩 Observable
偺娤應幰偺廤崌撪偵婛偵懚嵼偟偰偄傞娤應幰偲摨偠偱側偄側傜偽丆偦偺廤崌偵捛壛偡傞丅
public void
deleteObserver(Observer o)o 傪偙偺僆僽僕僃僋僩 Observable
偺娤應幰廤崌偐傜庢傝彍偔丅
public void
deleteObservers()Observable
偺娤應幰廤崌偐傜庢傝彍偔丅
public int
countObservers()Observable 偺娤應幰廤崌撪偺娤應幰悢傪曉偡丅
public void
notifyObservers()Observable
偑曄壔偟偨偲儅乕僋偝傟偨傜丆偙偺儊僜僢僪偼戞2偺乮丠乯偺堷悢傪
null
偲偟偰偡傋偰偺娤應幰偵捠抦偡傞丅偮傑傝丆偙偺儊僜僢僪偼師偲摨偠偲偡傞丅
notifyObservers(null)
public void
notifyObservers(Object arg)Observable 偑曄壔偟偨偲儅乕僋偝傟偨 (21.7.9)傜丆偙偺儊僜僢僪偼戞2偺堷悢傪
arg
偲偟偰偡傋偰偺娤應幰偵捠抦偡傞丅擇偮偺堷悢丆偙偺僆僽僕僃僋僩
Observable 媦傃 arg丆傪傕偭偨娤應幰偺儊僜僢僪
update(21.8.1)傪屇傃弌偡偙偲偵傛偭偰娤應幰偼捠抦傪庴偗傞丅偙偺偲偒丆偙偺僆僽僕僃僋僩偺儅乕僋偼徚嫀偝傟傞(21.7.8)丅
protected void
setChanged()Observable
偑曄壔偟偨偲偟偰儅乕僋傪晅偗傞丅儊僜僢僪 hasChanged 偼
true 傪曉偡丅
protected void
clearChanged()Observable
偼曄壔偟偰偄側偄偲偟偰儅乕僋傪偮偗傞丅儊僜僢僪 hasChanged 偼
false 傪曉偡丅
public boolean
hasChanged()Observable 偵懳偟偰丆儊僜僢僪
clearChanged 枖偼儊僜僢僪 notifyObservers
傛傝屻偵儊僜僢僪 setChanged 偑屇偽傟偨偲偒偵尷傝
true 傪曉偡丅
21.8 僀儞僞僼僃乕僗
偁傞僋儔僗偑僆僽僕僃僋僩 java.util.ObserverObservable
偑曄壔偟偨偲偒偵捠抦偝傟傞偨傔偵偼丆僀儞僞僼僃乕僗 Observer
傪幚憰偡傞偙偲偑朷傑偟偄丅僆僽僕僃僋僩 Observer
偑偳偺傛偆偵捠抦偝傟傞偐偵偮偄偰偼丆僋儔僗 Observable(21.7)傪嶲徠偺偙偲丅
public interface
Observer {
public void update(Observable o, Object arg);
}
public void
update(Observable o, Object arg)Observable 偑曄壔偟偨偲偒媦傃偦偺儊僜僢僪
notifyObservers(21.7.6)偑屇傃弌偝傟傞偲偒丆observers
偺廤崌撪偺偡傋偰偺僆僽僕僃僋僩 Observer
偼丆擇偮偺堷悢僆僽僕僃僋僩 Observable 媦傃儊僜僢僪
notifyObservers
傊偺屇傃弌偟偵傛傝巜掕偝傟偨堷悢傪搉偟丆儊僜僢僪 update
傪婲摦偡傞偙偲偱捠抦偝傟傞丅
21.9 僋儔僗
僋儔僗 java.util.RandomRandom
偺奺僀儞僗僞儞僗偼丆暿乆偺撈棫側丆屳偄偵柍娭學偺僾儕儈僥傿僽宆偺抣偺媈帡棎悢敪惗婍偲偡傞丅
public class
擇偮偺僆僽僕僃僋僩 Random {
protected long seed;
protected double nextNextGaussian;
protected boolean haveNextNextGaussian = false;
public Random();
public Random(long seed);
public void setSeed(long seed);
protected int next(int bits);
public int nextInt();
public long nextLong();
public float nextFloat();
public double nextDouble();
public double nextGaussian();
}
Random
偑摨偠惗惉尮乮seed乯偱惗惉偝傟丆偟偐傕奺乆偵懳偟偰堦楢偺摨偠儊僜僢僪屇弌偟偑側偝傟偨側傜偽丆偡傋偰偺Java幚憰偵偍偄偰摨偠悢帤偺楍傪惗惉偟偦傟傪曉偡丅偙偺惈幙傪曐徹偡傞偨傔丆
僋儔僗 Random
偵懳偟偰摿暿偺傾儖僑儕僘儉傪婯掕偡傞丅Java僐乕僪偺姰慡側堏怉惈傪幚尰偡傞偨傔偵丆Java幚憰偼僋儔僗
Random
偵懳偟偰丆埲壓偵帵偡偡傋偰偺傾儖僑儕僘儉傪巊梡偟側偗傟偽側傜側偄丅偟偐偟丆僋儔僗
Random
偺僒僽僋儔僗偼丆偡傋偰偺儊僜僢僪偵懳偡傞堦斒揑側婯懃傪庣傞斖埻撪偱懠偺傾儖僑儕僘儉傪巊偆偙偲偑嫋偝傟傞丅
Random 偑幚憰偡傞傾儖僑儕僘儉偼丄protected
側嶰偮偺忬懺曄悢傪巊梡偡傞丅傾儖僑儕僘儉偼傑偨丆奺婲摦偵娭偟偰丆32屄傑偱偺媅帡棎悢揑偵敪惗偟偨價僢僩偵採嫙偡傞
protected 側儐乕僥傿儕僥傿儊僜僢僪傪巊梡偡傞丅
protected long
seed;next(21.9.7)偱巊梡偡傞曄悢丅
protected double
nextNextGaussian;nextGaussian(21.9.12)偑屇傃弌偝傟偨偲偒偵攝晍偡傞丆偁傜偐偠傔寁嶼偝傟偨抣傪曐帩偡傞偨傔偵巊梡偡傞曄悢丅
protected boolean
haveNextNextGaussian = false;nextGaussian(21.9.12)偱攝晍偡傞師偺抣傪偁傜偐偠傔寁嶼偟丆偐偮幪偰嫀偭偨偐傪捛愓偡傞偨傔偵巊梡偡傞曄悢丅
public
Random()Random
敪惗婍傪弶婜壔偟丆尰嵼帪崗(20.18.6)傪惗惉尮偲偡傞丅
public Random() {
this(System.currentTimeMillis()); }
public
Random(long seed)Random
敪惗婍傪弶婜壔偟丆堷悢 seed 傪惗惉尮偲偡傞丅
public Random(long seed) { setSeed(seed); }
public void
setSeed(long seed)setSeed
偑廬傢側偗傟偽側傜側偄堦斒婯懃偼丆師偺偲偍傝偲偡傞丅偮傑傝丆棎悢敪惗婍僆僽僕僃僋僩偺忬懺傪曄峏偟丆堷悢
seed 傪惗惉尮偲偟丆捈慜偵惗惉偟偨傕偺偲慡偔摨偠忬懺偵偡傞丅
setSeed 偼僋儔僗 Random
偱師偺傛偆偵幚憰偡傞丅
synchronized public void setSeed(long seed) {
this.seed = (seed ^ 0x5DEECE66DL) & ((1L << 48) - 1);
haveNextNextGaussian = false;
}
僋儔僗 Random 偵傛傞 setSeed
偺幚憰偼丆嬼慠偵梌偊傜傟偨惗惉尮偺48價僢僩偟偐巊梡偟側偄丅偟偐偟丆捠忢偼丆抲偒姺傢傞儊僜僢僪偼丆惗惉尮抣偲偟偰long堷悢偺64價僢僩偡傋偰傪巊梡偟偰傕傛偄丅
protected int
next(int bits)next
偑廬傢側偗傟偽側傜側偄堦斒婯懃偼丆師偺偲偍傝偲偡傞丅偮傑傝丆int
偺抣傪曉偟丆堷悢價僢僩偑 1 埲忋 32
埲壓側傜偽丆曉媝抣偺壓埵價僢僩偺懡偔偼乮嬤帡揑偵乯撈棫偵慖戰偝傟偨價僢僩抣偲偟丆乮嬤帡揑偵乯摍偟偄妋棪偱
0 枖偼 1 偲偡傞丅
Random 偵傛偭偰丆儊僜僢僪 next
傪師偺偲偍傝偵幚憰偡傞丅
synchronized protected int next(int bits) {
seed = (seed * 0x5DEECE66DL + 0xBL) & ((1L << 48) - 1);
return (int)(seed >>> (48 - bits));
}
偙傟偼慄宍崌摨朄偵傛傞媈帡棎悢敪惗婍偱丆D. H. Lehmer偵傛傝掕媊偝傟丆Donald
E. Knuth 偵傛傝 The Art of Computer Programming 偺戞俀姫
Seminumerical Algorithms 偺 3.2.1.偱婰弎偝傟偰偄傞丅
public int
nextInt()nextInt
偑廬傢側偗傟偽傑傜側偄堦斒婯懃偼丆師偺偲偍傝偲偡傞丅偮傑傝丆堦偮偺
int 抣傪媈帡棎悢揑偵敪惗偟曉偡丅偡傋偰偺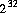 屄偺壜擻側
屄偺壜擻側 int
抣傪乮嬤帡揑偵乯摍妋棪偱惗惉偡傞丅
setSeed 傪僋儔僗 Random
偵傛偭偰丆師偺偲偍傝偵幚憰偡傞丅
public int nextInt() { return next(32); }
public long
nextLong()nextInt
偑廬傢側偗傟偽側傜側偄堦斒婯懃偼丆師偺偲偍傝偲偡傞丅偮傑傝丆堦偮偺
long 抣傪媈帡棎悢揑偵敪惗偟曉偡丅偡傋偰偺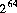 屄偺壜擻側
屄偺壜擻側 long
抣傪乮嬤帡揑偵乯摍妋棪偱惗惉偡傞丅
setSeed 傪僋儔僗 Random
偵傛偭偰丆師偺偲偍傝偵幚憰偡傞丅public long nextLong() {
return ((long)next(32) << 32) + next(32);
}
public float
nextFloat()nextFloat
偑廬傢側偗傟偽側傜側偄堦斒婯懃偼丆師偺偲偍傝偲偡傞丅偮傑傝丆0.0f
埲忋 1.0f 枹枮偺斖埻偐傜乮嬤帡揑偵乯堦條偵慖戰偝傟傞堦偮偺
float 抣傪媈帡棎悢揑偵敪惗偟曉偡丅偡傋偰偺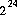 屄偺宍幃
屄偺宍幃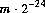 偺壜擻側
偺壜擻側 float
抣傪乮嬤帡揑偵乯摍妋棫偱惗惉偡傞丅偙偙偱丆m 偼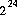 傛傝彫偝偄惓偺惍悢偲偡傞丅
傛傝彫偝偄惓偺惍悢偲偡傞丅
setSeed 傪僋儔僗 Random
偵傛偭偰丆師偺偲偍傝偵幚憰偡傞丅public float nextFloat() {
return next(24) / ((float)(1 << 24));
}
儊僜僢僪 next
偼丆撈棫偵慖戰偝傟偨價僢僩偺嬤帡揑偵曃傝偺側偄敪惗尮偱偁傞偨傔偵丆乬嬤帡揑偵乭偲偄偆梊杊揑昞尰傪慜弎偺婰弎偵巊梡偡傞丅姰慡側敪惗尮枖偼姰慡偵棎悢揑偵慖戰偝傟偨價僢僩偑懚嵼偡傞側傜偽丆帵偝傟偨傾儖僑儕僘儉偼梌偊傜傟偨斖埻偐傜姰慡側嬒堦惈傪傕偭偰
float 傪慖戰偡傞丅
public double
nextDouble()nextDouble
偑廬傢側偗傟偽側傜側偄堦斒婯懃偼丆師偺偲偍傝偲偡傞丅偮傑傝丆0.0d
埲忋 1.0d 枹枮偺斖埻偐傜慖戰偝傟傞堦偮偺 double
抣傪媈帡棎悢揑偵敪惗偟曉偡丅偡傋偰偺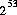 屄偺宍幃
屄偺宍幃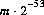 偺壜擻側
偺壜擻側 float 抣傪嬤帡揑偵摍妋棫偱惗惉偡傞丅偨偩偟丆m 偼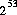 傛傝彫偝偄惓偺惍悢偲偡傞丅
傛傝彫偝偄惓偺惍悢偲偡傞丅
儊僜僢僪
儊僜僢僪 setSeed 傪僋儔僗 Random 偵傛偭偰丆師偺偲偍傝偵幚憰偡傞丅
next
偼丆撈棫偵慖戰偝傟偨嬤帡揑偵價僢僩曃傝偺側偄敪惗尮偱偁傞偨傔偵丆乬嬤帡揑偵乭偲偄偆梊杊揑昞尰傪慜弎偺婰弎偵巊梡偡傞丅姰慡側敪惗尮媦傃姰慡偵棎悢揑側偵慖戰偝傟偨價僢僩偑懚嵼偡傞側傜偽丆帵偝傟偨傾儖僑儕僘儉偼梌偊傜傟偨斖埻偐傜姰慡側嬒堦惈傪傕偭偰
double 抣傪慖戰偡傞丅
public double
nextGaussian()nextGaussian
偑廬傢側偗傟偽側傜側偄堦斒婯懃偼丆師偺偲偍傝偲偡傞丅偮傑傝丆嬤帡揑偵丆暯嬒
0.0丆昗弨曃嵎 1.0
偺捠忢偺惓婯暘晍偐傜慖戰偝傟偨堦偮偺 double
抣傪媈帡棎悢揑偵敪惗偟曉偡丅
setSeed 傪僋儔僗 Random
偵傛偭偰丆師偺偲偍傝偵幚憰偡傞丅
synchronized public double nextGaussian() {
if (haveNextNextGaussian) {
haveNextNextGaussian = false;
return nextNextGaussian;
} else {
double v1, v2, s;
do {
v1 = 2 * nextDouble() - 1; // between -1.0 and 1.0
v2 = 2 * nextDouble() - 1; // between -1.0 and 1.0
s = v1 * v1 + v2 * v2;
} while (s >= 1);
double norm = Math.sqrt(-2 * Math.log(s)/s);
nextNextGaussian = v2 * norm;
haveNextNextGaussian = true;
return v1 * norm;
}
}
偙偙偱偼丆G.E.P.Box丆M.E.Muller媦傃G.Marsaglia偺嬌庤朄(polar
method)傪巊梡偟偰偍傝丆The Art of Computer Programming,
2姫:Seminumerical Algorithms, 3.4.1, 彫愡 C,algorithm P撪偵 Doonald
E.Knuth 偵傛偭偰婰弎偝傟偰偄傞丅偙傟偼 Math.log
傊偺堦夞偺屇傃弌偟媦傃 Math.sqrt
傊偺堦夞偺屇傃弌偟偵傛傝擇偮偺撈棫偟偨抣傪惗惉偡傞偙偲偵拲堄偡傞偙偲丅
21.10 僋儔僗
僋儔僗 java.util.StringTokenizerStringTokenizer 偼丆String
傪僩乕僋儞偵暘妱偡傞庤抜傪採嫙偡傞丅偙偺僋儔僗偵傛傝巊梡偝傟傞僩乕僋儞愗傝弌偟儊僜僢僪偼丆僋儔僗
java.io.StreamTokenizer
偵傛傝巊梡偝傟傞儊僜僢僪傛傝傕偼傞偐偵扨弮偲偡傞丅椺偊偽丆StringTokenizer
偼丆幆暿巕丆悢媦傃堷梡楍傪嬫暿偟側偄丅偝傜偵丆拲庍偺擣幆媦傃撉傒旘偽偟傪偟側偄丅
StringTokenizer 偼丆 Enumeration(21.1)偲偟偰梌偊傜傟傞丅public class
StringTokenizer implements Enumeration {
public StringTokenizer(String str, String delim, boolean returnTokens);
public StringTokenizer(String str, String delim);
public StringTokenizer(String str);
public boolean hasMoreTokens();
public String nextToken();
public String nextToken(String delim);
public boolean hasMoreElements();
public Object nextElement();
public int countTokens();
}
StringTokenizer
偼丆扨偵暥帤傪嬫愗傝暥帤偲偦傟埲奜偺暥帤偺僋儔僗偲偵暘妱偡傞丅僩乕僋儞愗弌偟巕偼丆抣
true 傪傕偮 returnTokens
偱惗惉偝傟偨偐丆false 傪傕偮 returnTokens
偱惗惉偝傟偨偐偵埶懚偟偰丆師偺偄偢傟偐偺摦嶌傪偡傞丅returnTokens 偑 false
側傜偽丆嬫愗傝暥帤偼丆嫽枴偁傞僩乕僋儞傪暘棧偡傞偨傔偩偗偵巊傢傟傞丅偙偺応崌丆僩乕僋儞偼丆嬫愗傝暥帤偱側偄楢懕偡傞暥帤偺嵟戝楍偲側傞丅returnTokens 偑 true
側傜偽丆嬫愗傝暥帤偦偺傕偺傪嫽枴偁傞僩乕僋儞偲峫偊傞丅偙偺応崌丆僩乕僋儞偼丆堦偮偺嬫愗傝暥帤偐丆嬫愗傝暥帤偱側偄楢懕偡傞暥帤偺嵟戝楍偐偺偄偢傟偐偲偡傞丅StringTokenizer 偼丆撪晹揑偵丆僩乕僋儞傪愗傝弌偡
String
撪偺尰嵼埵抲傪曐帩偡傞丅張棟偝傟偨暥帤偺愭偵尰嵼埵抲傪恑傔傞憖嶌偑懚嵼偡傞丅StringTokenizer 傪惗惉偡傞偨傔偵巊梡偟偨暥帤楍偺晹暘楍(20.12.32)傪摼傞偙偲偵傛偭偰僩乕僋儞傪曉偡丅public
StringTokenizer(String str, String delim,
boolean returnTokens)StringTokenizer
傪弶婜壔偟丆梌偊傜傟偨楍 str 撪偺僩乕僋儞傪擣幆偡傞丅楍
delim 撪偺偡傋偰偺暥帤傪嬫愗傝暥帤偲偡傞丅堷悢
returnTokens
偼丆嬫愗傝暥帤偦偺傕偺傪僩乕僋儞偲偡傞偐偳偆偐傪巜掕偡傞丅
public
StringTokenizer(String str, String delim)StringTokenizer
傪弶婜壔偟丆梌偊傜傟偨楍 str 撪偺僩乕僋儞傪擣幆偡傞丅楍
delim
撪偺偡傋偰偺暥帤傪嬫愗傝暥帤偲偡傞丅嬫愗傝暥帤偦偺傕偺偼僩乕僋儞偲偟偰庢傝埖傢傟側偄丅
public
StringTokenizer(String str)StringTokenizer
傪弶婜壔偟丆梌偊傜傟偨楍 str
撪偺僩乕僋儞傪擣幆偡傞丅偡傋偰偺嬻敀椶(20.5.19)傪嬫愗傝暥帤偲偡傞丅嬫愗傝暥帤偦偺傕偺偼僩乕僋儞偲偟偰偼庢傝埖傢傟側偄丅
public boolean
hasMoreTokens()true 偲偡傞丅偙偺儊僜僢僪偑 true
傪曉偡応崌丆堷悢側偟偱 nextToken
傪屇傃弌偡偲張棟偑惉岟偟偰僩乕僋儞傪曉偡丅
public String
nextToken()public String
nextToken(String delim)StringTokenizer
偱嬫愗傝暥帤偲峫偊傜傟偰偄傞暥帤偺廤崌傪丆楍 delim
撪偺暥帤偵姺偊傞丅師偵丆尰嵼埵抲傛傝愭偺楍撪偺師偺僩乕僋儞傪曉偡丅尰嵼埵抲偼丆擣幆偝傟偨僩乕僋儞傪墇偊偰師偵恑傓丅
public boolean
hasMoreElements()hasMoreTokens(21.10.4)偲慡偔摨偠怳晳偄傪偡傞丅StringTokenizer
傪 Enumeration(21.1)偲偟偰巊梡壜擻偲偡傞偨傔偵採嫙偝傟傞丅
public Object
nextElement()nextToken(21.10.5)偲慡偔摨偠怳晳偄傪偡傞丅StringTokenizer
傪 Enumeration(21.1)
偲偟偰巊梡壜擻偲偡傞偨傔偵採嫙偡傞丅
public int
countTokens()21.11 僋儔僗
java.util.VectorVector
偼丆攝楍偲摨條偵丆惍悢僀儞僨僋僗傪巊偄丆傾僋僙僗壜擻側崁栚傪娷傓丅偟偐偟丆Vector
惗惉屻偺崁栚偺捛壛媦傃嶍彍偵揔墳偟丆昁梫偵墳偠偰丆Vector
偺僒僀僘偼憹壛枖偼尭彮偡傞丅
public class
Vector implements Cloneable {
protected Object[] elementData;
protected int elementCount;
protected int capacityIncrement;
public Vector(int initialCapacity, int capacityIncrement);
public Vector(int initialCapacity);
public Vector();
public final String toString();
public Object clone();
public final Object elementAt(int index)
throws IndexOutOfBoundsException;
public final void setElementAt(Object obj, int index)
throws IndexOutOfBoundsException;
public final Object firstElement()
throws NoSuchElementException;
public final Object lastElement()
throws NoSuchElementException;
public final void addElement(Object obj);
public final void insertElementAt(Object obj, int index)
throws IndexOutOfBoundsException;
public final boolean removeElement(Object obj);
public final void removeElementAt(int index)
throws IndexOutOfBoundsException;
public final void removeAllElements();
public final boolean isEmpty();
public final int size();
public final void setSize(int newSize);
public final int capacity();
public final void ensureCapacity(int minCapacity);
public final void trimToSize();
public final void copyInto(Object anArray[])
throws IndexOutOfBoundsException;
public final Enumeration elements();
public final boolean contains(Object elem);
public final int indexOf(Object elem);
public final int indexOf(Object elem, int index)
throws IndexOutOfBoundsException;
public final int lastIndexOf(Object elem);
public final int lastIndexOf(Object elem, int index)
throws IndexOutOfBoundsException;
}
protected Object[]
elementData;Vector
偼丆彮側偔偲傕偡傋偰偺梫慺傪娷傓戝偒偝偺攝楍撪偵梫慺傪曐帩偡傞丅
protected int
elementCount;Vector
偺撪偺尰嵼偺崁栚悢傪曐帩偡傞丅梫慺 elementData[0] 偐傜
elementData[elementCount-1] 傑偱傪幚嵺偺崁栚偲偡傞丅
protected int
capacityIncrement;ensureCapacity(21.11.22)偑乮怴偟偄攝楍傪惗惉偡傞偙偲偱乯僼傿乕儖僪
elementData
撪偺僨乕僞攝楍偺僒僀僘傪憹壛偟側偗傟偽側傜側偄偲偒丆彮側偔偲傕
capacityIncrement
撪偺検偩偗僒僀僘傪憹壛偡傞丅偟偐偟丆capacityIncrement
偑0偱偁傟偽丆彮側偔偲傕僨乕僞攝楍偺僒僀僘傪2攞偵偡傞丅
public
Vector(int initialCapacity, int
capacityIncrement)Vector
傪弶婜壔偟丆偦偺撪晹僨乕僞攝楍偺僒僀僘傪 initialCapacity
偲偟丆昗弨偺梕検憹壛検傪 capacityIncrement
偺抣偲偡傞丅嵟弶丆Vector 偼偳傫側崁栚傕娷傑側偄丅
public
Vector(int initialCapacity)Vector
傪弶婜壔偟丆偦偺撪晹僨乕僞攝楍偺僒僀僘傪 initialCapacity
偲偟丆昗弨偺梕検憹壛検傪0偲偡傞丅嵟弶丆Vector
偼偳傫側崁栚傕娷傑側偄丅
public
Vector()Vector
傪弶婜壔偟丆偦偺撪晹僨乕僞攝楍偺僒僀僘傪 10
偲偟丆昗弨偺梕検憹壛検傪0偲偡傞丅嵟弶丆Vector
偼偳傫側崁栚傕娷傑側偄丅
public final String
toString()Vector
偼丆ASCII宍幃偺妏妵屖偱埻傑傟丆ASCII宍幃偺暥帤",
"乮僐儞儅媦傃僗儁乕僗乯偱嬫愗傜傟偨丆崁栚偺儕僗僩偺楍宍幃偱昞尰偡傞丅儊僜僢僪
toString 偼丆崁栚傪楍偵曄姺偡傞偨傔偵巊梡偡傞丅僰儖嶲徠偼丆楍
"null" 偲偟偰昞尰偡傞丅
Vector v = new Vector();
v.addElement("Canberra");
v.addElement("Cancun");
v.addElement("Canandaigua");
System.out.println(v.toString());
偙傟偼師偺弌椡傪惗惉偡傞丅
[Canberra, Cancun, Canandaigua]
偙偺儊僜僢僪偼丆Object(20.1.2)偺儊僜僢僪 toString
傪抲偒姺偊傞丅public Object
clone()Vector
偺僐僺乕傪峔惉偟丆偦傟傪曉偡丅僐僺乕偼丆Vector
偺撪晹僨乕僞攝楍偺僋儘乕儞傊偺嶲徠傪娷傒丆尦偺撪晹僨乕僞攝楍傊偺嶲徠偼娷傑側偄丅
Object(20.1.5)偺儊僜僢僪 clone
傪抲偒姺偊傞丅public final Object
elementAt(int index)
throws
IndexOutOfBoundsExceptionindex 偑晧偱偁傞偐丆Vector
偺尰嵼偺僒僀僘傛傝傕戝偒偗傟偽丆IndexOutOfBoundsException
偑搳偘傜傟傞丅public final void
setElementAt(Object obj, int index)
throws
IndexOutOfBoundsExceptionindex 傪傕偭偨 Vector 偺崁栚傪
obj 偱抲偒姺偊丆obj 傪 Vector
撪偺摿掕偺 index 偺崁栚偲偡傞丅
index 偑晧偱偁傞偐丆Vector
偺尰嵼偺僒僀僘傛傝傕戝偒偗傟偽丆IndexOutOfBoundsException
偑搳偘傜傟傞丅public final Object
firstElement()
throws
NoSuchElementExceptionVector 偑嬻側傜偽丆NoSuchElementException
偑搳偘傜傟傞丅偦傟埲奜偺応崌偵偼丆嵟弶偺崁栚乮僀儞僨僋僗 0
偺崁栚乯傪曉偡丅
public final Object
lastElement()
throws
NoSuchElementExceptionVector 偑嬻側傜偽丆NoSuchElementException
偑搳偘傜傟傞丅偦傟埲奜偺応崌偵偼丆嵟屻偺崁栚乮僀儞僨僋僗
size()-1 偺崁栚乯傪曉偡丅
public final void
addElement(Object obj)Vector 偺僒僀僘傪 1 偩偗憹壛偟丆obj
傪怴偨側嵟屻偺崁栚偲偡傞丅
public final void
insertElementAt(Object obj, int index)
throws
IndexOutOfBoundsExceptionVector 偺僒僀僘傪 1 偩偗憹壛偟丆obj
傪摿掕偺 index 偵偍偗傞怴偟偄崁栚偲偡傞丅僀儞僨僋僗
k 偑 index 傛傝傕戝偒偄偲偒偵尷傝丆埲慜
k 偵懚嵼偟偨 Vector 偺崁栚偼丆偡傋偰嵟弶偵
k+1 偵堏摦偡傞丅
public final boolean
removeElement(Object obj)Vector 偑 obj 偺弌尰傪娷傔偽丆儊僜僢僪
removeElementAt(21.11.16)傪巊梡偟偨偐偺傛偆偵嵟弶偺乮嵟彫偺僀儞僨僋僗傪傕偭偨乯弌尰傪嶍彍偟丆true
傪曉偡丅Vector 偑 obj
偺弌尰傪娷傑側偗傟偽丆Vector 傪廋惓偣偢 false
傪曉偡丅
public final void
removeElementAt(int index)
throws
IndexOutOfBoundsExceptionVector 偺僒僀僘傪 1 偩偗尭彮偟丆摿掕偺
index 偵偍偗傞崁栚傪 Vector
偐傜庢傝彍偔丅僀儞僨僋僗 k 偑 index
傛傝傕戝偒偄偲偒偵尷傝丆埲慜偵僀儞僨僋僗 k 偵懚嵼偟偰偄偨
Vector 偺崁栚傪嵟弶偵僀儞僨僋僗 k-1 偵堏摦偡傞丅
public final void
removeAllElements()Vector 偐傜偡傋偰偺梫慺傪庢傝彍偒丆Vector
傪嬻偲偡傞丅
public final boolean
isEmpty()Vector
偑嬻偱偁傞偲偒丆偮傑傝偦偺僒僀僘偑0偱偁傞偲偒偵尷傝丆true
傪曉偡丅
public final int
size()public final void
setSize(int newSize)Vector 偺僒僀僘傪 newSize
偵曄偊傞丅怴偟偄僒僀僘偑尦偺僒僀僘傛傝傕彫偝偄側傜偽丆崁栚傪屻傠偐傜弴偵庢傝彍偒幪偰傞丅怴偟偄僒僀僘偑尦偺僒僀僘傛傝傕戝偒偄側傜偽丆怴偟偄崁栚偵
null 傪愝掕偡傞丅
public final int
capacity()Vector 偺尰嵼偺梕検乮僼傿乕儖僪 elementData
偵妋曐偝傟偰偄傞撪晹僨乕僞攝楍偺挿偝乯傪曉偡丅
public final void
ensureCapacity(int minCapacity)Vector 偺尰嵼偺梕検偑 minCapacity
傛傝傕彫偝偗傟偽丆僼傿乕儖僪 elementData(21.11.1)偵妋曐偟偰偄傞撪晹僨乕僞攝楍傪戝偒偄曽偱抲偒姺偊偰丆梕検傪憹壛偡傞丅怴偟偄僨乕僞攝楍偺僒僀僘偼丆capacityIncrement
偺抣偑惓偺抣側傜偽丆尦偺僒僀僘偲 capacityIncrement (21.11.3)偲傪壛偊偨傕偺偲偡傞丅capacityIncrement
偺抣偑惓偱側偄応崌偵偼丆怴偟偄梕検偼尦偺梕検偺俀攞偲偡傞丅偟偐偟偙偺怴偟偄僒僀僘偑憡曄傢傜偢
minCapacity 傛傝彫偝偄応崌偵偼丆偙偺怴偟偄梕検傪
minCapacity 偲偡傞丅
public final void
trimToSize()Vector 偺梕検偑尰嵼偺 size(21.11.19)傛傝傕戝偒偗傟偽丆僼傿乕儖僪
elementData
偱妋曐偟偰偄傞撪晹僨乕僞攝楍傪彫偝偄曽偵抲偒姺偊丆梕検傪曄偊偰尰嵼偺僒僀僘偵摍偟偔偡傞丅
public final void
copyInto(Object anArray[])
throws
IndexOutOfBoundsExceptionVector 偺偡傋偰偺崁栚傪攝楍 anArray
偵僐僺乕偡傞丅Vector 撪偺僀儞僨僋僗 k
偵偍偗傞崁栚傪 anArray 偺梫慺 k
偵僐僺乕偡傞丅anArray 偺挿偝偑 Vector
偺僒僀僘傛傝傕彫偝偗傟偽丆IndexOutOfBoundsException
偑搳偘傜傟傞丅
public final Enumeration
elements()Vector 撪偺偡傋偰偺梫慺傪惗惉偡傞 Enumeration(21.1)傪曉偡丅惗惉偝傟傞嵟弶偺崁栚傪僀儞僨僋僗
0 偺崁栚偲偟丆師傪僀儞僨僋僗 1
偺崁栚偲偟丆埲崀摨條偵僀儞僨僋僗傪晅偗傞丅
public final boolean
contains(Object elem)Vector 撪偺崁栚偑丆儊僜僢僪 equals(20.1.3)偱寛掕偝傟傞elem
偲摨偠偲偒偵尷傝丆true 傪曉偡丅
public final int
indexOf(Object elem)elem 偵摍偟偄崁栚偑 Vector
撪偵懚嵼偡傞応崌丆嵟弶偺弌尰偺僀儞僨僋僗丆偮傑傝丆師偺幃傪
true 偲偡傞嵟彫抣 k 傪曉偡丅
elem.equals(elementData[k])
Vector 撪偵偙傟傜偺崁栚偑弌尰偟側偗傟偽丆-1
傪曉偡丅public final int
indexOf(Object elem, int index)
throws
IndexOutOfBoundsExceptionelem 偵摍偟偄崁栚偑丆Vector 撪偺埵抲
k
枖偼偦傟埲崀偵懚嵼偡傟偽丆嵟弶偺弌尰偺僀儞僨僋僗丆偮傑傝丆師偺幃傪
true 偲偡傞嵟彫抣 k 傪曉偡丅
elem.equals(elementData[k]) && (k >= index)
Vector 撪偵偙傟傜偺崁栚偑弌尰偟側偗傟偽丆-1
傪曉偡丅public final int
lastIndexOf(Object elem)elem 偵摍偟偄崁栚偑 Vector
撪偵懚嵼偡傟偽丆嵟屻偺弌尰偺僀儞僨僋僗丆偮傑傝丆師偺幃傪 true
偲偡傞嵟彫抣 k 傪曉偡丅
elem.equals(elementData[k])
Vector 撪偵偙傟傜偺崁栚偑弌尰偟側偗傟偽丆-1
傪曉偡丅public final int
lastIndexOf(Object elem, int index)
throws
IndexOutOfBoundsExceptionelem 偵摍偟偄崁栚偑 Vector 撪偺埵抲 k
枖偼偦傟埲慜偵懚嵼偡傟偽丆嵟屻偺弌尰偺僀儞僨僋僗丆偮傑傝丆師偺幃傪
true 偲偡傞嵟戝抣 k 傪徚偡丅
elem.equals(elementData[k]) && (k <= index)
Vector 撪偵偙傟傜偺崁栚偑懚嵼偟側偗傟偽丆-1
傪曉偡丅21.12 僋儔僗
僋儔僗 java.util.StackStack
偼丆儀僋僩儖傪僗僞僢僋偲偟偰庢傝埖偆偨傔偵俆屄偺憖嶌傪捛壛偟偰
Vector 傪奼挘偡傞丅捠忢偺 push 媦傃
pop 憖嶌丆僗僞僢僋忋偺嵟忋埵偺崁栚傪庢傝弌偡儊僜僢僪
peek丆僗僞僢僋偑嬻偐偳偆偐傪帋尡偡傞儊僜僢僪
empty
暲傃偵崁栚傪扵偟僗僞僢僋傪挷傋崁栚偺僗僞僢僋嵟忋埵偐傜偺埵抲傪尒偄弌偡儊僜僢僪
search 傪採嫙偡傞丅
public class
僗僞僢僋傪嵟弶偵嶌惉偡傞偲偒丆僗僞僢僋偼偳傫側崁栚傕娷傑側偄丅
Stack extends Vector {
public Object push(Object item);
public Object pop() throws EmptyStackException;
public Object peek() throws EmptyStackException;
public boolean empty();
public int search(Object o);
}
public Object
push(Object item)item
傪僗僞僢僋偺嵟忋埵偵墴偟崬傓丅偙傟偼丆師偲慡偔摨偠岠壥傪傕偮丅
addElement(item)
Vector(21.11.13)偺
儊僜僢僪 addElement 傪嶲徠偡傞偙偲丅public Object
pop() throws EmptyStackExceptionEmptyStackException
偑搳偘傜傟傞丅偦傟埲奜偺応崌偵偼丆嵟忋埵偺崁栚乮Vector
偺嵟屻偺崁栚乯傪庢傝彍偒丆偦傟傪曉偡丅
public Object
peek() throws EmptyStackExceptionEmptyStackException
偑搳偘傜傟傞丅偦傟埲奜偺応崌偵偼丆嵟忋埵偺崁栚乮Vector
偺嵟屻偺崁栚乯傪曉偡偑丆庢傝彍偐側偄丅
public boolean
empty()true
偲偡傞丅
public int
search(Object o)o 偑 Stack
撪偺崁栚偱偁傟偽丆偙偺儊僜僢僪偼丆僗僞僢僋偺嵟忋埵偐傜嵟傕嬤偄弌尰偺僗僞僢僋嵟忋埵偐傜偺嫍棧傪曉偡丅僗僞僢僋偺嵟忋埵傪嫍棧
1 偲偡傞丅o 傪 Stack
撪偺崁栚偲斾妑偡傞偨傔偵丆儊僜僢僪 equals(20.1.3)傪巊梡偡傞丅
21.13 僋儔僗
java.util.EmptyStackExceptionEmptyStackException 偼丆嬻偺僆僽僕僃僋僩 Stack
偵懳偟偰丆pop(21.12.2)枖偼 peek(21.12.3)傪峴側偍偆偲偟偨偙偲傪帵偡偨傔偵丆搳偘傜傟傞
丅
public class
EmptyStackException extends RuntimeException {
public EmptyStackException();
}
public
EmptyStackException()EmptyStackException
傪弶婜壔偟丆僄儔乕儊僢僙乕僕傪 null 偲偡傞丅
21.14 僋儔僗
java.util.NoSuchElementExceptionNoSuchElementException
偼丆偦傟埲忋嫙媼偡傞梫慺偑懚嵼偟側偄僆僽僕僃僋僩 Enumeration
偵偝傜偵梫慺傪梫媮偟偨偙偲傪帵偡偨傔偵丆搳偘傜傟傞 丅僀儞僞僼僃乕僗
Enumeration(21.1.2)偺儊僜僢僪
nextElement 嶲徠丅
public class
NoSuchElementException extends RuntimeException {
public NoSuchElementException();
public NoSuchElementException(String s);
}
public
NoSuchElementException()NoSuchElementException
傪弶婜壔偟丆僄儔乕儊僢僙乕僕傪 null 偲偡傞丅
public
NoSuchElementException(String s)NoSuchElementException
傪弶婜壔偟丆屻偵儊僜僢僪 getMessage(20.22.3)偱専嶕偡傞僄儔乕儊僢僙乕僕楍
s 傊偺嶲徠傪曐懚偡傞丅