3. 字句構造
3.では,Javaプログラム言語の字句構造を規定する。
プログラムはUnicode(3.1)で記述されるが,字句変換が提供されるため(3.2) ,Unicodeエスケープ(3.3)を使用することによって,ASCII文字だけを使用して任意のUnicode文字を表現できる。
行番号の整合性を維持しながら,既存のホストシステムによって異なる行終端の扱いをサポートするために,行終端子を定義する(3.4)。
字句変換の結果のUnicode文字は,空白類(3.6),注釈(3.7)及びトークンのいずれかとする,入力要素(3.5)の並びへ還元される。
トークンは,構文文法の識別子(3.8),キーワード(3.9),リテラル(3.10),分離子(3.11)
及び演算子(3.12)とする。
3.1 Unicode
プログラムはUnicode文字集合を使用して記述される。
この符号化についての情報は,次のURLを参照のこと。
http://www.unicode.org
Javaプログラム言語の1.1より前の版では,Unicode 1.1.5が使用されていた(The Unicode Standard: Worldwide Character Encoding(1.4)及びその改訂情報を参照)。
それからJDK 1.1.7より前の版では,Unicode 2.0が使用されていた。
JDK 1.1.7からはUnicode 2.1が使用されている。
Javaプラットホームは,Unicode標準が改訂されたなら,それに合わせて改訂する計画である。
特定の版で使用しているUnicodeの正確な版は,クラスCharacterのドキュメンテーション中に規定されている。
注釈(3.7),識別子,文字リテラル及び文字列リテラルの内容
(3.10.4,3.10.5)を除き,プログラム中のすべての入力要素(3.5)は,ASCII文字(又は,結果としてASCII文字へ変換されるUnicodeエスケープ(3.3))だけから構成される。
ASCII(ANSI X3.4)は,the American Standard Code for Information Interchangeの短縮形とする。
Unicode文字符号化の最初の128文字は,ASCII文字となっている。
3.2 字句変換
元のUnicode文字ストリームは,次の三つの字句変換ステップを順に適用して,トークンの並びへ変換される。
- Unicode文字からなる元のストリーム中のUnicodeエスケープ(3.3)を対応するUnicode文字へ変換する。
xxxxを16進数値とする
\uxxxxの形式のUnicodeエスケープは,xxxxという符号化のUnicode文字を表現する。
この変換ステップによって,任意のプログラムはASCII文字だけを使用して記述できる。
- ステップ1の変換結果のUnicode ストリームを,入力文字及び行終端子(3.4)のストリームへ変換する。
- ステップ2の変換結果の入力文字及び行終端子からなるストリームは,空白類(3.6)及び注釈(3.7)が取り除かれた後,構文文法(2.3)の終端記号となるトークン(3.5)を含む入力要素(3.5)の系列へ変換される。
変換結果が最終的に正しいプログラムとならず,他の字句変換を使用すれば正しいプログラムとなることがあっても,各ステップでは,最長となる変換が使用される。
したがって,入力文字a--bは,a,-,-,bへトークン化すると文法的に正しいプログラム部分になるにもかかわらず,文法的に正しいプログラム部分とはならなくても,a,--,bへトークン化する(3.5)。
参考 ISO/IEC 10646における文字"逆スラッシュ"は,日本ではしばしば"円記号"(¥)として表示されることがある点に注意する。
3.3 Unicodeエスケープ
実装は,入力中のUnicodeエスケープ (Unicode escapes)を最初に認識し,ASCII文字\uの後に4個の16進数字が続いた場合,その16進数値によって示されるUnicode文字へ変換し,他のすべての文字は変更せずに渡す。
この変換ステップは,次のようなUnicode入力文字の並びに帰着する。
UnicodeInputCharacter:
UnicodeEscape
RawInputCharacter
UnicodeEscape:
\ UnicodeMarker HexDigit HexDigit HexDigit HexDigit
UnicodeMarker:
u
UnicodeMarker u
RawInputCharacter:
any UnicodeCharacter
HexDigit: one of
0 1 2 3 4 5 6 7 8 9 a b c d e f A B C D E F
\,u及び16進数字はすべてASCII文字とする。
文法によって要求される処理に加えて,入力処理は,元の入力文字が逆スラッシュ\の場合,\文字以外の文字及び入力ストリームの先頭と区別し,\文字の前に連続して何個の\文字が存在するかを数えなければらない。
個数が偶数の場合,\はUnicodeエスケープを開始するのに適格とする。
個数が奇数の場合,\はUnicodeエスケープを開始するのに適格でない。
例えば,元の入力"\\u2297=\u2297"の変換結果は," \ \
u 2 2 9 7
= 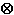
"
の11個の文字となる
(\u2297は文字のUnicode符号化とする)。
適格な\の後にuが続かない場合,それはRawInputCharacterとして扱われ,そしてエスケープされたUnicodeストリームの部分として残る。
適格な\の後に一つ以上のuが続き,最後のuの後に4個の16進数字が伴わない場合は,コンパイル時エラーが発生する。
Unicodeエスケープによって生成された文字が,更にUnicodeエスケープとして使用されることはない。
例えば,元の入力\u005cu005aの変換結果は,005cがUnicode値\を表現するので,六つの文字 \ u 0 0
5 aとなる。
\u005cに含まれる\は,更にUnicodeエスケープの開始として解釈されないので,変換結果は,Unicode文字005a,つまり文字Zにはならない。
Javaプログラム言語は,Unicodeで書かれたプログラムをASCIIに変換する標準的な方法,つまり,ASCIIベースのツールで処理できる形式へプログラムを変換する標準的な方法を規定する。
この変換には,余分のuを追加することで,プログラムのソーステキスト内の任意のUnicodeエスケープからASCIIへの変換が含まれる。
例えば,\uxxxxは\uuxxxxとなる。
一方,この変換と同時に,ソーステキスト中の非ASCII文字は,単一のuを含む\uxxxxエスケープへ変換する。
この変換された版は,Javaプログラム言語のコンパイラ("Javaコンパイラ")に同等に受け付けられ,まったく同じプログラムを表現する。
複数uを含むエスケープシーケンスは,一つだけ少ないuをもつUnicode文字の並びへ変換し,同時に,単一のuをもつ各エスケープシーケンスは対応する単一のUnicode文字へ変換することで,このASCII形式からまったく同じUnicodeソースへ後に戻すことができる。
実装は,適切なフォントが利用できない場合,Unicode文字を表示するために,出力形式として\uxxxx記法を使用することが望ましい。
3.4 行終端子
実装は,次に,行終端子 (line terminators)を認識することによってUnicode入力文字の並びを行に分割する。
この行の定義によって,Javaコンパイラなどのシステム構成要素によって生成される行番号が決定される。
この行の定義によって,//形式の注釈(3.7)の終端も規定される。
LineTerminator:
ASCIIのLF文字 (いわゆる"改行")
ASCIIのCR文字 (いわゆる"復帰")
ASCIIのCR文字に続くASCIIのLF文字
InputCharacter:
UnicodeInputCharacter but not CR or LF
行は,ASCII文字のCR,LF及びCR LFによって終端される。
CRと後続のLFの二つの文字は,2個の行終端子ではなく,1個の行終端子として数える。
結果は行終端子及び入力文字の並びであり,それらはトークン化プロセスの3番目に対する終端記号となる。
3.5 入力要素及びトークン
エスケープ処理(3.3)及びその後の入力行の認識(3.4)の結果となる入力文字及び行終端子は,入力要素 (input elements)の並びへ分解される。
空白類(3.6)又は注釈(3.7)以外の入力要素は,トークン (tokens)とする。
トークンは,構文文法(2.3)の終端記号とする。
このプロセスは,次の生成規則によって規定される。
Input:
InputElementsopt Subopt
InputElements:
InputElement
InputElements InputElement
InputElement:
WhiteSpace
Comment
Token
Token:
Identifier
Keyword
Literal
Separator
Operator
Sub:
ASCIIのSUB文字 (いわゆる"control-Z")
空白類(3.6)及び
注釈(3.7)は,隣接するトークンを結合して別のトークンとする可能性がある場合,トークンを分割する役割を果たすことができる。
例えば,入力中のASCII文字-及び=は,それらの間に空白類又は注釈が存在しない場合だけ,演算子トークン-= (3.12)を形成することができる。
ある種のオペレーティングシステムとの互換性を特に考慮して,ASCIIのSUB 文字(\u001a又はcontrol-Z)がエスケープされた入力ストリームの最後の文字ならば,それは無視される。
結果の入力ストリーム中に二つのトークンx及びyがある場合を考える。
xがyの前にある場合,xはyの左側 (to the left of)にあり,及びyはxの右側 (to the right of)にあるという。
例えば,次の単純なコードの場合を考える。
class Empty {
}
例のように紙の上に二次元的に表現したとき,}トークンが{トークンの左下側にあった場合でも,{の右側にあるという。
左及び右という単語の使用法に関するこの慣例によって,例えば,二項演算子の右辺オペランドとか,代入の左辺とか言う。
3.6 空白類
空白類 (white space)は,ASCIIのスペース,文字タブ及び書式送り文字として定義され,行終端子(3.4)も含まれる。
WhiteSpace:
ASCIIのSP文字 (いわゆる"スペース")
ASCIIのHT文字 (いわゆる"文字タブ")
ASCIIのFF文字 (いわゆる"書式送り")
LineTerminator
3.7 注釈
注釈 (comments)には,次の2種類がある。
/* text */ 従来の注釈: ASCII文字/*からASCII文字*/までの
すべてのテキストが無視される(C及びC++と同じ)。
// text 行末注釈: ASCII文字//から行末までのすべてのテキスト
が無視される(C++と同じ)。
これらの注釈は,次の生成規則によって形式的に規定される。
Comment:
TraditionalComment
EndOfLineComment
TraditionalComment:
/ * NotStar CommentTail
EndOfLineComment:
/ / CharactersInLineopt LineTerminator
CommentTail:
* CommentTailStar
NotStar CommentTail
CommentTailStar:
/
* CommentTailStar
NotStarNotSlash CommentTail
NotStar:
InputCharacter but not *
LineTerminator
NotStarNotSlash:
InputCharacter but not * or /
LineTerminator
CharactersInLine:
InputCharacter
CharactersInLine InputCharacter
これらの生成規則は,次の特性を暗に含んでいる。
- 注釈は入れ子とならない。
//で始まる注釈において,/*及び*/は特別の意味をもたない。
/*又は/**で始まる注釈において,//は特別の意味をもたない。
結果として,次のテキストは単一の完全な注釈となる。
/* this comment /* // /** ends here: */
この字句文法は,文字リテラル(3.10.4)又は文字列リテラル(3.10.5)の中に注釈が書けないことを意味する。
3.8 識別子
識別子 (identifier)は,Java字 (Java letters)及びJava数字 (Java digits)の長さに制限のない並びとする。
ただし,先頭の文字はJava字でなければならない。
識別子は,キーワード(3.9),論理値リテラル(3.10.3),又は空リテラル(3.10.7)と同じスペル(Unicode文字の並び)であってはならない。
Identifier:
IdentifierChars but not a Keyword or BooleanLiteral or NullLiteral
IdentifierChars:
JavaLetter
IdentifierChars JavaLetterOrDigit
JavaLetter:
Java字(後述)の任意のUnicode文字
JavaLetterOrDigit:
Java字又はJava数字(後述)の任意のUnicode文字
字及び数字は,全Unicode文字集合から引用できる。
全Unicode文字集合は,中国語,日本語及び朝鮮語(チョソノ)のための大量の文字集合を含む,現在の世界で使用されているほとんどの表記文字をサポートしている。
これによって,プログラマは,プログラム中の識別子を自国語で記述することができる。
"Java字"とは,メソッドCharacter.isJavaIdentifierStartがtrueを返す文字とする。
"Java字又はJava数字"とは,メソッドCharacter.isJavaIdentifierPartがtrueを返す文字とする。
Java字には,ASCIIラテン文字の大文字・小文字,つまり,A-Z (\u0041-\u005a)及びa-z (\u0061-\u007a),並びに,歴史的な理由によって,ASCIIの下線 (_又は\u005f)及びドル記号($又は\u0024)が含まれる。
$文字は,機械的に生成されたソースコードにおいてだけ,又は,まれには,過去のシステム上の既存の名前にアクセスするためだけに使用することが望ましい。
"Java数字"は,ASCIIの数字0-9
(\u0030-\u0039)を含む。
二つの識別子は,それらが同一な場合,つまり,各文字又は数字に対して同じUnicode文字をもつ場合だけ,同じとする。
識別子の外見が同じであっても,識別子が異なる場合もある。
例えば,LATIN CAPITAL LETTER A (A, \u0041),LATIN SMALL LETTER A (a, \u0061),GREEK CAPITAL LETTER ALPHA (A, \u0391)及びCYRILLIC SMALL LETTER A (a, \u0430)の各1文字から構成される識別子はすべて異なる。
Unicode合成文字は,それを分解した文字とは異なる。
例えば,LATIN CAPITAL LETTER A ACUTE (Á,\u00c1)は,ソーティングにおいて,LATIN CAPITAL LETTER A (A, \u0041)の後にNON-SPACING ACUTE (´, \u0301)を続けたものと同じと見なされるが,識別子としては異なる。
文字分解の詳細については,The Unicode Standard, Volume 1の412ページ以降を,ソーティングの詳細については626~627ページを参照のこと。
次に識別子の例を示す。
String i3 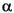
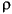
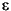
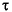
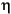 MAX_VALUE isLetterOrDigit
MAX_VALUE isLetterOrDigit
3.9 キーワード
ASCII文字から作られる次の文字の並びは,キーワード (keyword)として使うために予約され,識別子(3.8)として使うことはできない。
Keyword: one of
abstract default if private this
boolean do implements protected throw
break double import public throws
byte else instanceof return transient
case extends int short try
catch final interface static void
char finally long strictfp volatile
class float native super while
const for new switch
continue goto package synchronized
キーワードconst及びgotoは,現在は使用されていないが,予約されている。
これらのC++言語のキーワードがプログラム中に誤って現れた場合,Javaコンパイラが適切なエラーメッセージを出力できる。
true及びfalseはキーワードと考えることができるが,文法的に厳密に考えて論理値リテラル(3.10.3)とする。
同様に,nullもキーワードと考えることができるが,文法的に厳密に考えてnullリテラル(3.10.7)とする。
3.10 リテラル
リテラル (literal)は,プリミティブ型(4.2),String型(4.3.3)及び空型(4.1)の値のソースコード表現とする。
Literal:
IntegerLiteral
FloatingPointLiteral
BooleanLiteral
CharacterLiteral
StringLiteral
NullLiteral
3.10.1 整数リテラル
整数型及びその値の詳細は,4.2.1を参照のこと。
整数リテラル (integer literal)は,10進数(基数 10),16進数(基数 16),又は8進数(基数 8)で表現できる。
IntegerLiteral:
DecimalIntegerLiteral
HexIntegerLiteral
OctalIntegerLiteral
DecimalIntegerLiteral:
DecimalNumeral IntegerTypeSuffixopt
HexIntegerLiteral:
HexNumeral IntegerTypeSuffixopt
OctalIntegerLiteral:
OctalNumeral IntegerTypeSuffixopt
IntegerTypeSuffix: one of
l L
整数リテラルは,ASCII文字L又はl(エル)を
接尾辞としてもつ場合,long型とする。
それ以外の場合は,int型(4.2.1)とする。
文字l(エル)は数字の1と紛らわしいため,接尾辞Lを使用するのが望ましい。
10進数とは,一つのASCII文字0だけからなるか,又は1から9までの一つのASCII数字及びそれに続く0から9までの一つ以上のASCII数字からなる。
前者は,整数0を表し,後者は正整数を表す。
DecimalNumeral:
0
NonZeroDigit Digitsopt
Digits:
Digit
Digits Digit
Digit:
0
NonZeroDigit
NonZeroDigit: one of
1 2 3 4 5 6 7 8 9
16進数値は,先頭のASCII文字0x又は0X,及びその後に続く一つ以上のASCIIの16進数字からなり,正整数,0,又は負整数を表す。
10から15までの値をもつ16進数の数字はそれぞれaからf又はAからFまでのASCII文字によって表される。
16進数字として使用される各文字は,大文字又は小文字でもよい。
HexNumeral:
0 x HexDigits
0 X HexDigits
HexDigits:
HexDigit
HexDigit HexDigits
明確化のために,3.3の生成規則を次に繰り返し示す。
HexDigit: one of
0 1 2 3 4 5 6 7 8 9 a b c d e f A B C D E F
8進数値は,ASCII数字0の後に一つ以上の0から7までのASCII数字を続けたものとし,正整数,0,負整数を表現することができる。
OctalNumeral:
0 OctalDigits
OctalDigits:
OctalDigit
OctalDigit OctalDigits
OctalDigit: one of
0 1 2 3 4 5 6 7
8進数値は,常に二つ以上の数字からなることを注意されたい。
つまり,0は常に10進数の数値と見なされる。
数値の0,00及び0x0はまったく同じ整数値を表現するが,違いが実際に問題となることはない。
int型の10進リテラルで最も大きい値は,2147483648 (231)とする。
0から2147483647までのすべての10進リテラルは,intリテラルが使用できる場所ならどこでも使用できるが,リテラル2147483648は,単項マイナス演算子-のオペランド以外の場所では使用できない。
int型の16進及び8進リテラルで最も大きな正の値はそれぞれ,0x7fffffff及び017777777777とする。
この値は,2147483647 (231-1)に等しい。
int型の16進及び8進リテラルで最も小さな負の値はそれぞれ,0x80000000及び020000000000とする。
この値は,10進数値の-2147483648 (-231)に等しい。
16進及び8進リテラルの0xffffffff及び037777777777は10進数値-1を表現する。
int型の10進リテラルが2147483648 (231)より大きい場合,又は,リテラル2147483648が単項マイナス演算子-のオペランド以外の場所に使用された場合,あるいは,16進又は8進のintリテラルが32ビットで表現できない場合は,コンパイル時エラーが発生する。
次にintリテラルの例を示す。
0 2 0372 0xDadaCafe 1996 0x00FF00FF
long型の10進リテラルで最も大きい値は,9223372036854775808L (263)とする。
0Lから9223372036854775807Lまでのすべての10進リテラルは,longリテラルを使用できる場所ならどこでも使用できるが,リテラル9223372036854775808Lは単項マイナス演算子-のオペランド以外では使用できない。
long型の16進及び8進リテラルで最も大きい正の値はそれぞれ,0x7fffffffffffffffL及び0777777777777777777777Lとする。
この値は,9223372036854775807L (263-1)に等しい。
リテラル0x8000000000000000L及び01000000000000000000000Lはそれぞれ,long型の16進及び8進リテラルの最も小さい負数とする。
この値は,10進数値-9223372036854775808L (-263)に等しい。
16進及び8進リテラル0xffffffffffffffffL及び01777777777777777777777Lは,10進数値-1Lを表す。
long型の10進リテラルが
9223372036854775808L (263)より大きい場合,リテラル9223372036854775808Lが単項マイナス演算子-のオペランド以外の場所で使用された場合,並にlong型の16進又は8進リテラルが64ビットで表現できない場合は,コンパイル時エラーが発生する。
次にlong型のリテラルの例を示す。
0l 0777L 0x100000000L 2147483648L 0xC0B0L
3.10.2 浮動小数点リテラル
浮動小数点型及びその値の詳細は,4.2.3を参照のこと。
浮動小数点リテラル (floating-point literal)は,整数部,小数点(ASCII文字のピリオドによって表現される),小数部,指数部及び型接尾辞から構成される。
指数部が存在する場合は,ASCII文字e又はE及びその後に続く符号付き整数(符号は省略できる)によって示される。
整数部又は小数部に少なくとも数字が一つあり,小数点,指数部,指数部,又はfloat型の接尾辞のいずれかが必要とする。
他のすべての部分は省略可能とする。
浮動小数点リテラルは,ASCII文字F又はfの接尾辞をもつ場合,float型とする。
それ以外の場合は,double型とし,ASCII文字D又はdの接尾辞は省略できる。
FloatingPointLiteral:
Digits . Digitsopt ExponentPartopt FloatTypeSuffixopt
. Digits ExponentPartopt FloatTypeSuffixopt
Digits ExponentPart FloatTypeSuffixopt
Digits ExponentPartopt FloatTypeSuffix
ExponentPart:
ExponentIndicator SignedInteger
ExponentIndicator: one of
e E
SignedInteger:
Signopt Digits
Sign: one of
+ -
FloatTypeSuffix: one of
f F d D
float型及びdouble型の要素はそれぞれ,IEEE 754標準の32ビット単精度及び64ビット倍精度の2進数浮動小数点書式によって表現できる値とする。
浮動小数点数のUnicode文字列表現から
IEEE 754標準の内部2進数浮動小数点表現への適切な入力変換の詳細は,パッケージjava.langのクラスFloat及びクラスDoubleのメソッドvalueOfに記述されている。
floatリテラルで,最も大きい正の有限値は,3.40282347e+38fとする。
float型の非ゼロのリテラルで,最も小さい正の有限値は,1.40239846e-45fとする。
doubleリテラルで,最も大きい正の有限値は,1.79769313486231570e+308とする。
double型の非ゼロのリテラルで,最も小さい正の有限値は,4.94065645841246544e-324とする。
非ゼロの浮動小数点リテラルが非常に大きな値のため,内部表現への丸め変換においてIEEE 754標準の無限大となる場合,コンパイル時エラーが発生する。
プログラムでは,1f/0f又は-1d/0dなどの定数式か,クラスFloat及びDoubleの
定義済み定数POSITIVE_INFINITY及びNEGATIVE_INFINITYを使用することによって,コンパイル時エラーを発生させることなく,無限大を表現できる。
非ゼロの浮動小数点リテラルが非常に小さな値のため,内部表現への丸め変換においてIEEE 754標準のゼロとなる場合,コンパイル時エラーが発生する。
非ゼロの浮動小数点リテラルが小さな値をもつが,内部表現への丸め変換において非ゼロの非正規化数となる場合は,コンパイル時エラーは発生しない。
Not-a-Number値を表現する定義済み定数として,クラスFloat及びDoubleにFloat.NaN及びDouble.NaNが定義されている。
次にfloatリテラルの例を示す。
1e1f 2.f .3f 0f 3.14f 6.022137e+23f
次にdoubleリテラルの例を示す。
1e1 2. .3 0.0 3.14 1e-9d 1e137
浮動小数点リテラルを10進数以外で表現する方法は提供されていない。
しかし,クラスFloatのメソッドintBitsToFloat及びクラス Doubleのメソッド longBitsToDoubleを使用して,16進又は8進整数リテラルによって浮動小数点値を表現する方法が提供される。
例えば,次の値はMath.PIの値に等しい。
Double.longBitsToDouble(0x400921FB54442D18L)
3.10.3 論理値リテラル
boolean型は,ASCII文字から作られるリテラルtrue及びfalseによって表現される二つの値をもつ。
論理値リテラル (boolean literal)は常にboolean型とする。
BooleanLiteral: one of
true false
3.10.4 文字リテラル
文字リテラル (character literal)は,ASCIIの一重引用符によって囲まれた,文字又はエスケープシーケンスとして表現される。
一重引用符(アポストロフィ)を表す文字は\u0027とする。
文字リテラルは常にchar型とする。
CharacterLiteral:
' SingleCharacter '
' EscapeSequence '
SingleCharacter:
InputCharacter but not ' or \
エスケープシーケンスの定義は,3.10.6を参照のこと。
3.4に規定されているように,文字CR及びLFは,InputCharacterではなく,LineTerminatorを構成するものとして認識される。
SingleCharacter又はEscapeSequenceに続く文字が
'以外の場合は,コンパイル時エラーとする。
開始の'から終了の'の間に行終端子がある場合,コンパイル時エラーとする。
次にcharリテラルの例を示す。
'a'
'%'
'\t'
'\\'
'\''
'\u03a9'
'\uFFFF'
'\177'
'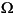 '
''
'
''
Unicodeエスケープは初期のステップで処理されるため,改行(LF)の値を表現する文字リテラルとして'\u000a'と書くことは正しくない。
Unicodeエスケープ\u000aは,変換ステップ1 (3.3)で実際の改行へ変換され,その改行はステップ2 (3.4)でLineTerminatorに変換されるので,この文字リテラルはステップ3で無効となる。
そのため,Unicodeエスケープの代わりに,エスケープシーケンス'\n'
(3.10.6)と書くのがよい。
同様に,復帰(CR)を表現する文字リテラルとして'\u000d'と書くことは正しくない。
代わりに,'\r'を使うのがよい。
C及びC++では,文字リテラルは一つ以上の文字からなる表現を含んでいてもよいが,そのような文字リテラルの値は実装によって異なる。
Javaプログラム言語では,文字リテラルは常に1個の文字だけを表現する。
3.10.5 文字列リテラル
文字列リテラル (string literal)は,二重引用符で囲まれた0個以上の文字から構成される。
各文字は,エスケープシーケンスによって表現されていてもよい。
文字列リテラルは,常にString型(4.3.3)とする。
文字列リテラルは,常にクラスStringの同一インスタンス(4.3.1)を参照する。
StringLiteral:
" StringCharacteropt "
StringCharacter:
StringCharacter
StringCharacter StringCharacter
StringCharacter:
InputCharacter but not " or \
EscapeSequence
エスケープシーケンスの定義は,3.10.6を参照のこと。
3.4に規定されているように,文字CR及びLFは InputCharacterではなく,LineTerminatorを構成するものとして認識される。
開始の"からそれに対応する終了の"との間に行終端子が存在する場合はコンパイル時エラーとする。
長い文字列リテラルは,常により短い固まりに分割でき,文字列連結演算子+(15.18.1)を使用して,式(括弧も使用できる)として記述することができる。
次に文字列リテラルの例を示す。
"" // 空文字列
"\"" // "だけを含む文字列
"This is a string" // 16文字を含む文字列
"This is a " + // 実際は,二つの文字列リテラルから構成される
"two-line string" // 文字列を値とする定数式
Unicodeエスケープは早いステップで処理されるため,一つの改行(LF)を含む文字列リテラルとして"\u000a"と書くのは正しくない。
そのUnicodeエスケープ\u000aは,変換ステップ1(3.3)で実際の改行に変換され,その改行はステップ2(3.4)でLineTerminatorに変換されるので,この文字列リテラルはステップ3で無効となる。
Unicodeエスケープの代わりに,"\n"(3.10.6)と書くのがよい。
同様に,一つの復帰(CR)を含む文字列リテラルとして"\u000d"と書くのは正しくない。
代わりに,"\r"を使う。
各文字列リテラルは,クラスString(4.3.3)のインスタンス(4.3.1,12.5)への参照(4.3)とする。
Stringオブジェクトは,定数値をもつ。
文字列リテラル(より一般的には,定数式(15.28)の値となる文字列)は,メソッドString.internを使用して,一意なインスタンスを共有するために"intern"される。
したがって,testプログラムが,次のコンパイル単位(7.3)
package testPackage;
class Test {
public static void main(String[] args) {
String hello = "Hello", lo = "lo";
System.out.print((hello == "Hello") + " ");
System.out.print((Other.hello == hello) + " ");
System.out.print((other.Other.hello == hello) + " ");
System.out.print((hello == ("Hel"+"lo")) + " ");
System.out.print((hello == ("Hel"+lo)) + " ");
System.out.println(hello == ("Hel"+lo).intern());
}
}
class Other { static String hello = "Hello"; }
及び次のコンパイル単位から構成される場合,
package other;
public class Other { static String hello = "Hello"; }
このプログラムは次の出力を生成する。
true true true true false true
この例は,次の六つの項目を説明している。
- 同一パッケージ(7)中の
同一クラス(8)に存在するリテラル文字列は,同一
Stringオブジェクト(4.3.1)への参照を表現する。
- 同一パッケージ中の異なるクラスに存在するリテラル文字列は,同一
Stringオブジェクトへの参照を表現する。
- 異なるパッケージ中の異なるクラスに存在するリテラル文字列も同様に,同一
Stringオブジェクトへの参照を表現する。
- 定数式(15.28)によって生成される文字列は,コンパイル時に計算され,リテラルのように扱われる。
- 実行時に計算される文字列は新たに生成されるため,異なるものとして扱われる。
- 計算された文字列を明示的にinternした結果は,同じ内容をもつ既存のリテラル文字列と同じ文字列になる。
参考 internは,指定されたStringオブジェクトの正準形式を返すメソッドである。
3.10.6 文字及び文字列リテラルのためのエスケープシーケンス
文字及び文字列のエスケープシーケンス (escape sequences)によって,文字リテラル(3.10.4)
及び文字列リテラル(3.10.5)中の
一重引用符,二重引用符,逆スラッシュ文字,及び非図形文字を表現できる。
EscapeSequence:
\ b /* \u0008: 後退 BS */
\ t /* \u0009: 文字タブ HT */
\ n /* \u000a: 改行 LF */
\ f /* \u000c: 書式送り FF */
\ r /* \u000d: 復帰 CR */
\ " /* \u0022: 二重引用符" */
\ ' /* \u0027: 一重引用符' */
\ \ /* \u005c: 逆スラッシュ\ */
OctalEscape /* \u0000から\u00ffまで。8進表現値。 */
OctalEscape:
\ OctalDigit
\ OctalDigit OctalDigit
\ ZeroToThree OctalDigit OctalDigit
OctalDigit: one of
0 1 2 3 4 5 6 7
ZeroToThree: one of
0 1 2 3
エスケープシーケンス中の逆スラッシュの後の文字が,ASCIIのb,t,n,f,r,",',\,0,1,2,3,4,5,6及び7でない場合は,コンパイル時エラーとする。
Unicodeエスケープ\uは,初期のステップ(3.3)で処理される。
(8進エスケープはC言語との互換性のために提供されるが,\u0000から\u00FFまでのUnicode値しか表現できない。
そのためUnicodeエスケープを使用するのが一般的に望ましい。)
参考 この規定では,Unicodeエスケープが表現する文字の名前を原規定に従って示した。
しかし,次の表に示すとおり,Unicode Standard,ISO/IEC 10646,JIS X 0211,JIS X 0201,及びJIS X 0208では,幾つかの文字に対して異なる名前が用いられているので注意すること。
この規定とUnicode,ISO/IEC及びJISの文字名の対応
| Unicodeエスケープ |
この規定の文字名 |
Unicode,ISO/IEC及びJISの文字名 |
| \u0022 |
二重引用符 (double quote) |
引用符 (QUOTATION MARK) |
| \u0027 |
一重引用符 (single quote) |
アポストロフィー (APOSTROPHE) |
| \u005c |
逆スラッシュ (backslash) |
逆斜線 (REVERSE SOLIDUS) |
3.10.7 空リテラル
空型は,空参照という一つの値をもち,ASCII文字から作られるリテラルnullによって表現される。
空リテラル (null literal)は,常に空型とする。
NullLiteral:
null
3.11 分離子
分離子 (separators)は,次の九つのASCII文字とする。
Separator: one of
( ) { } [ ] ; , .
3.12 演算子
演算子 (operators)は,複数のASCII文字の組み合せによって表現される次の37個のトークンとする。
Operator: one of
= > < ! ~ ? :
== <= >= != && || ++ --
+ - * / & | ^ % << >> >>>
+= -= *= /= &= |= ^= %= <<= >>= >>>=