Javaプログラムの仕事の多くが式を評価することによって行われる。その結果として,変数への代入などの副作用や,若しくはより大きい式においては引数か演算数として使用され得るような値,若しくは文における実行シーケンスに影響を与える,などいずれか又は両方を得る。
本章は,Javaの式の意味とそれらの評価のための規則を指定する。
Javaプログラムにおける式が評価されるとき,結果は,三つのうち一つを指示する。
式の評価は副作用を発生させることがある。なぜなら,埋め込み代入,インクリメント演算子,デクリメント演算子,そしてメソッド呼出しを式が含むかもしれないからである。
値を返さない,すなわちvoid(8.4)を宣言するメソッドを呼び出すメソッド呼出し(15.11)に限り,式は何も示していない。 そのような式は式文(14.7)としてのみ用いられる。なぜなら式が現れ得る他のあらゆる文脈は何かを指示するためにその式を必要とするからである。 また,メソッド呼出しの式文は結果を生成するメソッドを呼出して良い。 この場合,メソッドによって返される値は捨てられる。
おのおのの式は,何らかの(クラスかインタフェース)型の宣言に現れる。 すなわちフィールド初期子,静的初期子,コンストラクタ宣言,又はメソッドのためのコードに現れる。
式が変数を指示し,そして値がさらなる評価での使用に必要ならば,その変数の値は使用される。 この文脈では,式が変数か値を指示すれば,単に式の値と呼ぶ。
式が変数か値を指示すれば,式はコンパイル時に知らされる型を持つ。 式の型を決定するための規則はそれぞれの種類の式について説明される。
変数に格納された値が変数の型に対して常に互換性があるように,式の値は式の型に対して常に代入互換性(5.2)がある。 言い換えれば,型がTである式の値はいつも型Tの変数への代入に適している。
その型がfinal宣言されたクラス型Fであるような式は,空参照又はそのクラスがF自身であるようなオブジェクトのいずれかである値を持つことが保証される。なぜならfinal型はサブクラスを持たないからである。
もし式の型が単純型ならば,その式の値は同様な単純型である。 しかし式の型が参照型ならば,参照オブジェクトのクラスは,たとえその値がnullではなくオブジェクトの参照であろうと,コンパイル時に必ずしも知られているわけではない。 参照オブジェクトの実在クラスが,式の型から推論することができないような方法でプログラム実行時に影響する以下のようなところがJava言語にはある。
ここで記載した最初の2つのケースでは型エラーを検出して終わらないようにしなければならない。したがって,Java実行時の型エラーは次のような状況でのみ起こりうる。
あらゆる式には,ある計算ステップが実行される評価の正規モードがある。 以下の節はそれぞれの種類の式を評価する正規モードを記述する。 もし例外を投げることなしにすべてのステップが実行されたならば,この式は正常完了したと呼ばれる。
しかしながら,式の評価が例外を投げたならば,その時式は中途完了したと呼ばれる。 中途完了には,与えられた値と共に投げられるような関連する理由が常にある。
実行時の例外は以下のように事前に定義された演算子によって投げられる。
中途完了するメソッド本体の実行を引き起こす例外が発生すれば,メソッド呼出しの式は,投げられる例外と帰する。 また,コンストラクタの中途完了を引き起こす例外が起これば,クラスインスタンス生成式は,投げられる例外と帰する。 また,式の評価の間に様々なリンケージ及び仮想計算機のエラーが発生するかもしれない。 そのようなエラーを予測したり扱ったりするのは難しい。
例外が起こると,評価の通常モードのすべてのステップが完了する前に1つ又はそれ以上の式の評価が止まる。 そのような式は中途完了すると言われる。 そして,“正常完了する”と“中途完了する”という言葉は文(14.1)の実行にも適用される。 文は様々な理由で中途完了する。それは例外が投げられるからだけではない。
もし式の評価が副式の評価を必要とすれば,副式の中途完了は常にその式自身の突然の中途完了を引き起こす。そして同じ理由で評価の通常モード時におけるすべての継続ステップは実行されない。
Javaは,演算子のオペランドが特定の評価順序,すなわち左から右に評価されることを保証する。
Javaコードがこの仕様を絶対的に信用しないことを推奨する。 外側の大部分の演算子がそうであるようにそれぞれの式がせいぜい一つの副作用しか含まない時,又は左から右への式の評価の結果としてどの例外が起こるかということにコードが明確に依存しない時には,コードは通常より明確なものとなる。
二項演算子の左辺オペランドは,右辺オペランドの部分が評価される前に完全に評価される。 例えば,左辺オペランドが変数への代入を含み,右辺オペランドがその同じ変数の参照を含む場合,参照値は代入が最初に起こったという事実を反映する。
class Test {
public static void main(String[] args) {
int i = 2;
int j = (i=3) * i;
System.out.println(j);
}
}
9
を表示する。
もし演算子が複合代入演算子(15.25.2)ならば,左辺オペランドの評価は,左辺オペランドが指示する変数を記憶すること,そして予想される結合操作において使用するためにその変数の値を取り替え保存することの両方を含む。 そして,例えば,次のようなテストプログラムにおいて,
class Test {
public static void main(String[] args) {
int a = 9;
a += (a = 3); // first example
System.out.println(a);
int b = 9;
b = b + (b = 3); // second example
System.out.println(b);
}
}
1212
2個の代入文がともに,加えた右辺オペランドが評価される前に左辺オペランドの値,すなわち9を取り替え保存している。 その結果,変数を3に設定している。 どちらの例も6という結果を生成するのは許可されない。 これらの例の両方とも,ANSI/ISO規格のCでは規定されていない。
二項演算子の左辺オペランドの評価が中途完了すれば,右辺オランドのどの部分も評価されない。
class Test {
public static void main(String[] args) {
int j = 1;
try {
int i = forgetIt() / (j = 2);
} catch (Exception e) {
System.out.println(e);
System.out.println("Now j = " + j);
}
}
static int forgetIt() throws Exception {
throw new Exception("I'm outta here!");
}
}
java.lang.Exception: I'm outta here! Now j = 1
を表示する。
左辺オペランドforgetIt() の演算子/は右辺オペランド及びそこに埋め込まれた2のjへの代入が起こる前に例外を投げる。
Javaでは演算自身の実行前に,演算子のあらゆるオペランド(条件演算子&&, ||,そして? :を除く)が完全に評価されることを保証する。
二項演算子が整数除算/又は 15.16.2整数余%15.16.3ならば,その実行時にArithmeticExceptionが上がるかもしれない。しかし,この例外が投げられるのは二項演算子の両オペランドが評価された後のみ,かつ評価が正常完了した場合のみである。
class Test {
public static void main(String[] args) {
int divisor = 0;
try {
int i = 1 / (divisor * loseBig());
} catch (Exception e) {
System.out.println(e);
}
}
static int loseBig() throws Exception {
throw new Exception("Shuffle off to Buffalo!");
}
}
java.lang.Exception: Shuffle off to Buffalo!
次の結果ではない。
java.lang.ArithmeticException: / by zero
その理由は,ゼロによる除算のシグナルを含む除算演算子のどの部分もloseBigを呼び出す前に起こらないからである。除算演算が確かにゼロによる除算の例外に終わるであろうと検出,又は推測することができたとしても同じ。
Javaの実行は括弧及び演算子優先順位による評価の順番を重視しなければならない。 たとえ,(17におけるスレッドの実行モデルを使用して),複数のスレッドで実行する場合でも,すべての可能な計算値において,値及び観察可能な副作用同等であると証明されない限り,式をより簡便な計算順序に書き直すことは, 結合則のような代数的な場合でも許されない。
浮動小数点計算の場合,無限大及び数字でない(NaN)値においても,この規則は適用される。例えば,!(x<y)はx>=yに書き直されない。その理由は,x又はyがNaNならばこれらの式は異なった値を持つためである。
特に,数学的に結合性を持つ浮動小数点計算も計算論的には結合的でない。 そのような計算を単純に順序を変えてはならない。 例えば,Javaコンパイラが4.0*x*0.5を2.0*xと書き直すのは正しくない。 ここで四捨五入は問題とならないが,最初の式は無限大(オーバフローによる)を生成するが2番目の式は有限の結果を生むといったような大きな値xが存在しうる。
class Test {
public static void main(String[] args) {
double d = 8e+307;
System.out.println(4.0 * d * 0.5);
System.out.println(2.0 * d);
}
}
Infinity 1.6e+308
その理由は,最初の式はオーバーフローするが2番目はそうならないからである。
これとは対照的に,Javaにおいては,整数加算及び乗算は恐らく結合可能である。例えば, a,b,そしてcが局所変数である場合(複合スレッド及びvolatile値を含む問題を避けた),a+b+cは,(a+b)+c若しくはa+(b+c)のどちらとして評価されていようと,いつも同じ答えを生成する。もし,式b+cがそのコードの近くで起こると,賢いコンパイラはこの共通の副式を使用することができる。
メソッド又はコンストラクタ呼出し式,又はクラスインスタンス生成式において,引数式は括弧内にコンマによって区切られて現れる。 それぞれの引数式は,その右にあるどんな引数式よりも前に完全に評価される。
class Test {
public static void main(String[] args) {
String s = "going, ";
print3(s, s, s = "gone");
}
static void print3(String a, String b, String c) {
System.out.println(a + b + c);
}
}
going, going, gone
その理由は,文字列sに"gone"を代入するのはprint3に対する最初の2つの引数が評価された後だからである。
もし引数式の評価が中途完了すれば,それより右の引数式は一切評価されない。
class Test {
static int id;
public static void main(String[] args) {
try {
test(id = 1, oops(), id = 3);
} catch (Exception e) {
System.out.println(e + ", id=" + id);
}
}
static int oops() throws Exception {
throw new Exception("oops");
}
static int test(int a, int b, int c) {
return a + b + c;
}
}
java.lang.Exception: oops, id=1
いくつかの式に対する評価の順番はこれらの一般的規則によって完全にはカバーされていない。その理由は,これらの式が,時には特定しなければならないような例外的な状況を生じさせることがあることによる。 特に以下の種類の式に対する評価順位の詳細な例を参照のこと。
一次式は最も単純な種類の式の大部分を含む。そしてそれ以外のすべてのもの,すなわちリテラル,フィールドアクセス,メソッド呼出し,および配列アクセスなどは一次式によって構成される。 また,括弧で括った式は構文的に一次式として扱われる。
Primary:
PrimaryNoNewArray
ArrayCreationExpression
PrimaryNoNewArray:
Literal
this
( Expression )
ClassInstanceCreationExpression
FieldAccess
MethodInvocation
ArrayAccess
プログラミング言語の文法においては,Java文法のこの部分は2つの点で珍しい。 まず,局所変数及びメソッドパラメタの名前などの単純名が一次式でないこと。 技術的な理由により後置式が導入される時(15.13),名前は一次式と共にひとまとめにされる。
この技術的な理由は,左から右へのJavaプログラムの1字句の先読みだけによる解析を許可することと関係がある。 (z[3])及び(z[])という式を考える。 1番目の式は括弧で括られた配列アクセス(15.12)であり,2番目はキャスト(15.15)の始めである。 先読みのシンボルが[であるという時点で,左から右への解析はzを非終端記号Nameにした。 キャストの文脈においてはNameをPrimaryにする必要がない。しかし,もしNameがPrimaryならば,[に続く二つの字句の先読みなしでPrimaryにするかどうかを決めることはできない。(すなわち,括弧のある配列アクセスか又はキャストであるのかがわからない)。 ここに提示したJava文法は,Name及びPrimaryを分離し,他の構文規則(MethodInvocation,ArrayAccess,PostfixExpressionに対する規則。FieldAccessに対する規則ではない。その理由はNameによってカバーされているため)で扱うことによって,この問題を避けている。 この戦略では,より多く文脈を調べるまでNameがPrimaryとして扱われるべきかどうかという問題を効果的に先送りしている (キャスト式では他の問題が残っている。19.1.5を参照)。
2番目の珍しい特徴として,つぎのような式における文法的な潜在的曖昧さを避けている。
new int[3][3]
これはJavaにおいては,多次元配列の生成を常に意味するが,適切な文法的なだめ押しがないと,これは以下のような式と同じ意味としても解釈される。
(new int[3])[3]
この曖昧さは,Primaryの定義からPrimary及びPrimaryNoNewArrayに分けることによって排除される (“ぶら下がりelse問題”を避けるためにStatementからStatement及びStatementNoShortIf(14.4)を分離したのに相当する)。
リテラル(3.10)は固定された,不変の値を意味する。
以下に示す構文は3.10から簡便のために写されている。
Literal:
IntegerLiteral
FloatingPointLiteral
BooleanLiteral
CharacterLiteral
StringLiteral
NullLiteral
thisというキーワードはインスタンスメソッドかコンストラクタの本体において,又はクラスのインスタンス変数の初期化子においてのみ使用される。もしそれ以外の場所で現れればコンパイル時エラーが起こる。
一次式として使用される時,キーワードthisはインスタンスメソッドが呼び出されたオブジェクト(15.11)への,又は生成されたオブジェクトへの参照値を示す。 thisの型は,内部でキーワードthisが出現するクラスCとする。 実行時において,参照されるオブジェクトのクラスはクラスCかCのサブクラスとなる。
class IntVector {
int[] v;
boolean equals(IntVector other) {
if (this == other)
return true;
if (v.length != other.v.length)
return false;
for (int i = 0; i < v.length; i++)
if (v[i] != other.v[i])
return false;
return true;
}
}
クラスIntVectorは2つのベクターを比較するメソッドequalsを実装する。もしベクターotherがequalsメソッドを呼び出すのと同じベクターオブジェクトであるとすると,大きさと値の比較をスキップすることができる。 equalsメソッドはotherオブジェクトへの参照とthisを比較することによってこの検査を実行する。
キーワードthisはまた,特別に明白なコンストラクタ呼出しの文で使用される。その文はコンストラクタ本体(8.6.5)の始めに現れることができる。
括弧で括った式はその型が内包する式の型であり,実行時の値が内包された式の値であるような一次式である。
クラスインスタンス生成式は,クラスのインスタンスである新しいオブジェクトを作り出すのに使用される。
ClassInstanceCreationExpression:
new ClassType ( ArgumentListopt )
ArgumentList:
Expression
ArgumentList , Expression
クラスインスタンス生成式では,ClassTypeにabstractでないクラスを命名しなければならない。このクラスの型が生成式の型となる。
もし,実引数並びがあれば,それらを用いてメソッド呼出し (15.11) と同じ照合規則で,命名されたクラス型の本体で宣言されるコンストラクタを選ぶ。メソッド呼出しと同様に,与えられた実引数に適用可能で,適用可能な中では最も適切なコンストラクタが一意に決定できないならば,コンパイル時のメソッド照合エラーが生じる。
まず最初に,スペースが新しいクラスインスタンスのために割り当てられる。オブジェクトを割り当てるためのスペースが不十分なら,クラスインスタンス生成式の評価は, OutOfMemoryError (15.8.2) を投げて,中途完了する。
新しいオブジェクトは指定されたクラス型とそのすべてのスーパクラスで宣言されるすべてのフィールドの新しいインスタンスを含む。 新しいフィールドインスタンスが作り出されるときはその標準省略時解釈値(4.5.4)に初期化される。
次に,左から右に実引数並びが評価される。 実引数評価のいずれかが中途完了すると,その右側の実引数式は評価されない。クラスインスタンス生成式も同じ理由で中途完了する。
次に,指定されたクラス型の選択されたコンストラクタが呼び出される。 結果的にクラス型の各スーパクラスあたり少なくとも1つのコンストラクタを呼び出す。この過程は明示的なコンストラクタ呼出し文(8.6)によって指示され, 12.5で詳細に記述される。
クラスインスタンス生成式の値は指定されたクラスの新しく作り出されたオブジェクトへの参照となる。式が評価される毎に,新しいオブジェクトが作り出される。
クラスインスタンス生成式の評価で生成操作の実行にはメモリが不十分ならOutOfMemoryError が投げられる。この検査は実引数式の評価前に起こる。
class List {
int value;
List next;
static List head = new List(0);
List(int n) { value = n; next = head; head = this; }
}
class Test {
public static void main(String[] args) {
int id = 0, oldid = 0;
try {
for (;;) {
++id;
new List(oldid = id);
}
} catch (Error e) {
System.out.println(e + ", " + (oldid==id));
}
}
}
実引数式oldid=id の評価前にメモリ不足条件が検出されたので,印刷結果はつぎのようになる。
java.lang.OutOfMemoryError: List, false
これをメモリ不足状態が寸法式(15.9.3)の評価の後に検出される配列生成式 (15.9)の処理と比べると良い。
配列インスタンス生成式は,新しい配列(10.)を作り出すのに使用される。
ArrayCreationExpression:
new PrimitiveType DimExprs Dimsopt
new TypeName DimExprs Dimsopt
DimExprs:
DimExpr
DimExprs DimExpr
DimExpr:
[ Expression ]
Dims:
[ ]
Dims [ ]
配列生成式は要素がPrimitiveTypeかTypeNameによって指定された型である新しい配列オブジェクトを作り出す。TypeNameはabstractクラス型 (8.1.2.1)やインタフェース型(9.)も含めてどんな参照型でもよい。
生成式の型は配列型となる。生成式のコピーからnew キーワードとDimExpr式を削除したもので示される。例えば,次の生成式,
new double[3][3][]
double[][][]
寸法式DimExprの型は整数型でないとコンパイル時エラーが発生する。各式は単項数値拡張(5.6.1)を受ける。拡張型はintでないと コンパイル時エラーが発生する。寸法式の型はlongであってはならない。
まず最初に,左から右に寸法式が評価される。もし式の評価が中途完了すれば,その右の式は評価されない。
次に寸法式の値が検査される。 DimExpr式の値が負ならNegativeArraySizeExceptionが投げられる。
次にスペースが新しい配列に割り当てられる。スペースが不十分なら配列生成式の評価は,OutOfMemoryErrorを投げて,中途完了する。
単一のDimExprなら,一次元配列が指定された長さ分作り出されて,配列の各部品はその標準省略時解釈値(4.5.4)に初期化される。
配列生成式がN個のDimExpr式を含むならば,それは深さ
![]() の入れ子の実行により入れ子配列を生成する。例えば,宣言:
の入れ子の実行により入れ子配列を生成する。例えば,宣言:
float[][] matrix = new float[3][3];
float[][] matrix = new float[3][];
for (int d = 0; d < matrix.length; d++)
matrix[d] = new float[3];
Age[][][][][] Aquarius = new Age[6][10][8][12][];
Age[][][][][] Aquarius = new Age[6][][][][];
for (int d1 = 0; d1 < Aquarius.length; d1++) {
Aquarius[d1] = new Age[8][][][];
for (int d2 = 0; d2 < Aquarius[d1].length; d2++) {
Aquarius[d1][d2] = new Age[10][][];
for (int d3 = 0; d3 < Aquarius[d1][d2].length; d3++) {
Aquarius[d1][d2][d3] = new Age[12][];
}
}
}
d,
d1,d2およびd3は既に局所的に宣言されていない名前に取り替えられる。単一のnew式は実際に長さ6の1つの配列,長さ10の6つの配列,長さ8の![]() 配列,および長さ12の
配列,および長さ12の
![]() 配列を作り出す。
この例では5番目の次元が残されているが,これが空参照に初期化された実際の配列要素を含む。(Ageオブジェクト参照)後で以下のようなコードで配列要素を代入することができる。
配列を作り出す。
この例では5番目の次元が残されているが,これが空参照に初期化された実際の配列要素を含む。(Ageオブジェクト参照)後で以下のようなコードで配列要素を代入することができる。
Age[] Hair = { new Age("quartz"), new Age("topaz") };
Aquarius[1][9][6][9] = Hair;
多次元配列では,各レベルで同じ長さである必要はない。したがって,三角形マトリクスを以下のように作り出せる。
float triang[][] = new float[100][];
for (int i = 0; i < triang.length; i++)
triang[i] = new float[i+1];
配列生成式(15.9)には,括弧の中に1つ以上の寸法式がある。各寸法式はその右の寸法式の前に完全に評価される。
class Test {
public static void main(String[] args) {
int i = 4;
int ia[][] = new int[i][i=3];
System.out.println(
"[" + ia.length + "," + ia[0].length + "]");
}
}
[4,3]
2番目の寸法式がIを3に割り当てる前に最初の寸法が計算されるので4となる。
寸法式の評価が中途完了すると,その右の寸法式の部分は一切評価されない。次の例
class Test {
public static void main(String[] args) {
int[][] a = { { 00, 01 }, { 10, 11 } };
int i = 99;
try {
a[val()][i = 1]++;
} catch (Exception e) {
System.out.println(e + ", i=" + i);
}
}
static int val() throws Exception {
throw new Exception("unimplemented");
}
}
次を出力する。
java.lang.Exception: unimplemented, i=99
i を1に代入する代入式は決して実行されないからだ。
配列生成式の評価で生成操作にはメモリが不十分ならばOutOfMemoryErrorが投げられる。 この検査は通常すべての寸法式の評価が完了した後に起こる。
class Test {
public static void main(String[] args) {
int len = 0, oldlen = 0;
Object[] a = new Object[0];
try {
for (;;) {
++len;
Object[] temp = new Object[oldlen = len];
temp[0] = a;
a = temp;
}
} catch (Error e) {
System.out.println(e + ", " + (oldlen==len));
}
}
}
次を出力する。
java.lang.OutOfMemoryError, true
実引数式のoldlen= len が評価された後にメモリの状態が検出される。
クラスインスタンス生成式(15.8)では実引数式(15.8.2)を評価する前に,メモリの状態を検出する。
フィールドアクセス式はオブジェクトか配列のフィールドにアクセスする。式か特別なキーワードsuper の値への参照となる。(現在のインスタンス又はクラスのフィールドを参照することも単純名を使用することによって可能となる。15.13.1を参照のこと)
FieldAccess:
Primary . Identifier
super . Identifier
フィールドアクセス式の意味は限定名(6.6)と同じ規則を使用して決定されるが,式がパッケージ,クラス型,又はインタフェース型を指示することができないという制限がある。
Primaryの型は参照型Tでないとコンパイル時エラーが発生する。フィールドアクセス式の意味は以下の通りに決定される。
実行時参照される実際のオブジェクトのクラスでなく,Primary式の型だけがどのフィールドを使用するのかを決定する際に使用されることに注意せよ。
class S { int x = 0; }
class T extends S { int x = 1; }
class Test {
public static void main(String[] args) {
T t = new T();
System.out.println("t.x=" + t.x + when("t", t));
S s = new S();
System.out.println("s.x=" + s.x + when("s", s));
s = t;
System.out.println("s.x=" + s.x + when("s", s));
}
static String when(String name, Object t) {
return " when " + name + " holds a "
+ t.getClass() + " at run time.";
}
}
t.x=1 when t holds a class T at run time. s.x=0 when s holds a class S at run time. s.x=0 when s holds a class T at run time.
最終行は,アクセスされるフィールドが参照オブジェクトの実行時のクラスに依存しないことを示す。s がクラスTのオブジェクトを参照しても,式sの型がSなので式s.x はクラスSのフィールドxを参照する。クラスTのオブジェクトは名前xで指定されたクラスTとそのスーパクラスSの2つのフィールドを含む。
フィールドアクセスのために動的に表検索する必要がないのでJavaは素直な実装でも効率が良い。遅延束縛と上書きはインスタンスメソッドが使用されるときだけJavaで利用可能となる。フィールドにアクセスするインスタンスメソッドを使用する例を示す。
class S { int x = 0; int z() { return x; } }
class T extends S { int x = 1; int z() { return x; } }
class Test {
public static void main(String[] args) {
T t = new T();
System.out.println("t.z()=" + t.z() + when("t", t));
S s = new S();
System.out.println("s.z()=" + s.z() + when("s", s));
s = t;
System.out.println("s.z()=" + s.z() + when("s", s));
}
static String when(String name, Object t) {
return " when " + name + " holds a "
+ t.getClass() + " at run time.";
}
}
t.z()=1 when t holds a class T at run time. s.z()=0 when s holds a class S at run time. s.z()=1 when s holds a class T at run time.
最終行はアクセスされるメソッドが参照オブジェクトの実行時クラスに依存することを示す。sがクラスTのオブジェクトを参照すると 式s. z()は式sの型がSであってもクラスTのメソッドzを参照する。クラスTのメソッドzは クラスSのメソッドzを上書きする。
以下は空参照が例外を引き起こさずクラス(static)変数にアクセスするのに使用される例を示す
class Test {
static String mountain = "Chocorua";
static Test favorite(){
System.out.print("Mount ");
return null;
}
public static void main(String[] args) {
System.out.println(favorite().mountain);
}
}
Mount Chocorua
favorite()の結果がnullでも NullPointerExceptionは投げられない。Mount の印刷は,フィールドMountがstaticなので, その値でなく型だけがどのフィールドにアクセスするかの決定に使われたにもかかわらず,Primary式が実行時に完全に評価されたことを示している。
キーワードsuperを使用する特別な形はインスタンスメソッドか,コンストラクタか,クラスのインスタンス変数の初期化子の中でのみ,有効となる。これはキーワードthisの使用とちょうど同じ状況である(15.7.2)。Objectはスーパクラスを持たないのでsuperを含む形式はクラスObjectでは使用できない。superがクラスObjectに現れると,コンパイル時エラーが生じる。
フィールドアクセス式super.nameが クラスCの中に現れ,Cの直接のスーパクラスがクラスSとする。その時super.nameはまるでちょうどそれが式((S)this) .nameのように扱われる。 したがって,それは現在のオブジェクトのnameというフィールドを参照するが,現在のオブジェクトはスーパクラスのインスタンスとして見られる。したがって,たとえそのフィールドがクラスC のnameというフィールド宣言によって隠されても,クラスSで目に見えるnameというフィールドにアクセスすることができる。
interface I { int x = 0; }
class T1 implements I { int x = 1; }
class T2 extends T1 { int x = 2; }
class T3 extends T2 {
int x = 3;
void test() {
System.out.println("x=\t\t"+x);
System.out.println("super.x=\t\t"+super.x);
System.out.println("((T2)this).x=\t"+((T2)this).x);
System.out.println("((T1)this).x=\t"+((T1)this).x);
System.out.println("((I)this).x=\t"+((I)this).x);
}
}
class Test {
public static void main(String[] args) {
new T3().test();
}
}
x= 3 super.x= 2 ((T2)this).x= 2 ((T1)this).x= 1 ((I)this).x= 0
((T2)this).x
メソッド呼出し式は,クラス又はインスタンスメソッドを呼び出すのに使用される。
MethodInvocation:
MethodName ( ArgumentListopt )
Primary . Identifier ( ArgumentListopt )
super . Identifier ( ArgumentListopt )
便宜上,15.8からのArgumentListの定義を再び示す。
ArgumentList:
Expression
ArgumentList , Expression
コンパイル時のメソッド名の解決は,メソッドオーバロードの可能性のため,フィールド名の解決より複雑である。 実行時のメソッドの呼出しもまた,インスタンスメソッドの上書きの可能性のため,フィールドの参照より複雑である。
あるメソッド呼出し式により呼び出されるメソッドの決定はいくつかの段階を含む。次の三つの章でメソッド呼出しのコンパイル時の処理を説明する。 メソッド呼出し式の型の決定は 15.11.3で説明する。
コンパイル時のメソッド呼出し処理の最初のステップは,呼び出すメソッドの名前と,その名前のメソッドの定義を調べるクラス又はインタフェー スを明らかにすることである。次のとおり,左括弧に先行する形式に応じて, いくつかの考慮すべき場合がある。
2番目のステップは,前のステップにおいて決定されたクラス又はインタフェースから,メソッド宣言を探すことである。このステップではメソッドの名前と引数式の型を,適用可能かつ参照可能なメソッド宣言,即ち,与えられた 引数で正しく呼び出される宣言を特定するために用いる。そのようなメソッド宣言が複数あるかもしれないが,そのときには最も特殊なものが選択される。 最も特殊なメソッド宣言の記述子(シグネチャと返却値の型)が実行時にメソッドディスパッチを行うために使われる。
メソッド宣言は,次の二つが成り立つときかつそのときに限り,メソッド呼出しに対して適用可能であるという。
15.11.1で述べられた過程により決定されたクラス又はインタフェースが, このメソッド呼出しに適用可能なすべてのメソッド宣言について探索される。 スーパクラスおよび上位インタフェースから継承したメソッド定義はこの探索 に含まれる。
メソッド宣言がメソッド呼出しから参照可能かどうかは,メソッド宣言のアクセス修飾子(public,none,protected,又は private)およびメソッド呼出しの あらわれる場所に依存する。
もしクラス又はインタフェースが適用可能かつ参照可能なメソッド宣言を持たないなら,コンパイル時エラーが起こる。
public class Doubler {
static int two() { return two(1); }
private static int two(int i) { return 2*i; }
}
class Test extends Doubler {
public static long two(long j) {return j+j; }
public static void main(String[] args) {
System.out.println(two(3));
System.out.println(Doubler.two(3)); // compile-time error
}
}
Doublerクラス内のtwo(1)というメソッド呼出しに対し,twoと名付けられた二つの参照可能なメソッドがあるが,二番目のみが適用可能,したがって実行時に呼出される。Testクラス内のtwo(3)というメソッド呼出しに対 しては二つの適用可能なメソッドがあるが,Testクラス内のみが参照可 能であり,実行時に呼び出される(引数3はlong型に変換される)。 Doubler.two(3) のメソッド呼出しに対しては,TestクラスではなくDoubler クラスが,twoと名付けられたメソッドのために探される。唯一の適用可能な メソッドが参照可能ではないので,このメソッド呼出しはコンパイル時エラーと なる。
class ColoredPoint {
int x, y;
byte color;
void setColor(byte color) { this.color = color; }
}
class Test {
public static void main(String[] args) {
ColoredPoint cp = new ColoredPoint();
byte color = 37;
cp.setColor(color);
cp.setColor(37); // compile-time error
}
}
ここで,コンパイル時に適用可能なメソッドがないためにsetColorの2番目の呼出しでコンパイル時エラーが起こる。リテラル37の種類は型intであり,メソッド呼出し変換で型intをbyte型に変換することは起こらない。 変数colorの初期化で使用される代入変換はint型からbyte型へ定数の暗黙の変換を実行する。それは,値37はbyte型で表すのに十分小さいから許されているしかし,メソッド呼出し変換ではそのような変換は認められていない。
しかしながら,もしメソッドsetColorがbyteの代わりにintをとるように宣言 されていたならば,メソッド呼出しは両方とも正しい。最初の呼出しは メソッド呼出し変換がbyteからintへ拡張する変換を許すので可能である。 しかしながら,ナロー化キャストがsetColorの本体には必要となる。
void setColor(int color) { this.color = (byte)color; }
もし一つ以上のメソッドがメソッド呼出しに対して参照可能かつ適用可能なとき, 実行時メソッドディスパッチのための記述子にその内の一つを与える必要がある。Javaは最も特殊なメソッドを選ぶという規則を用いている。
直観的には,そのメソッド宣言により処理される いかなる呼出しも他の宣言にコンパイル時型エラーなしに渡されることが可能ならば,より特殊となる。
正確な定義は次のようになる。mを名前とし,n個の パラメータをもつ二つのメソッド宣言があるとする。一つの宣言がクラス又は インタフェースTの中に現れ,パラメータの型はT1, . . . , Tnであるとする。 さらにもう一方はクラス又はインタフェースUの中に現れ,パラメータの型はU1,. . . , Unであるとする。このとき,次が共に成り立つとき,かつそのときに限り,TのメソッドmはUのメソッドmよりも特殊である。
メソッドは,それが適用可能かつ参照可能で,その他には,より特殊で適用可能かつ参照可能なメソッド がないとき,最大限に特殊と言われる。
もしちょうど一個の最大限に特殊なメソッドがあるとき,それは実際に最も特殊なメソッドである。それは必然的に,適用可能で参照可能な他のどのメソッドよりも特殊である。それはしたがって15.11.3で述べらるように,さらにコンパイル時の検査にかけられる。
二つ又はそれ以上の最大限に特殊なメソッド宣言があるために, どのメソッドも最も特殊ではないことがある。この場合,メソッド呼出し はあいまいであると言い,コンパイル時エラーが起こる。
class Point { int x, y; }
class ColoredPoint extends Point { int color; }
class Test {
static void test(ColoredPoint p, Point q) {
System.out.println("(ColoredPoint, Point)");
}
static void test(Point p, ColoredPoint q) {
System.out.println("(Point, ColoredPoint)");
}
public static void main(String[] args) {
ColoredPoint cp = new ColoredPoint();
test(cp, cp); // compile-time error
}
}
この例はコンパイル時にエラーを生じさせる。問題は適用可能かつ参照可能で,どちらも他よりより特殊ではない二つのtestの宣言があることである。 それゆえ,このメソッド呼出しはあいまいである。
static void test(ColoredPoint p, ColoredPoint q) {
System.out.println("(ColoredPoint, ColoredPoint)");
}
これは他の二つより特殊になるので,このメソッド呼出しはもはやあいまいではない。
class Point { int x, y; }
class ColoredPoint extends Point { int color; }
class Test {
static int test(ColoredPoint p) {
return color;
}
static String test(Point p) {
return "Point";
}
public static void main(String[] args) {
ColoredPoint cp = new ColoredPoint();
String s = test(cp); // compile-time error
}
}
ここで,メソッドTestの最も特殊な宣言は,型ColoredPointをパラメータにとるものである。メソッドの結果型はintであり,intは割り当て変換によってString型には変換できないためにコンパイル時エラーが起こる。この例が示すように,Javaにおいて,メソッドの結果型はオーバーロードされたメソッドの解決には関与しない。返却値がStringである二番目のTestメソッドは,このプログラムをエラー無しのコンパイルを可能にする結果型を持つが,選ばれない。
コンパイル時には最も適用可能なメソッドが選ばれる。その記述子は実行時に どのメソッドが実際に実行されるかを決定する。新たなメソッドが クラスに追加されても,古い定義でコンパイルされたJavaコードは, 新たなメソッドを使用しない。再コンパイルすれば新たなメソッドが選ばれるようになる。
例として二つのコンパイル単位,一つはPointクラス,を考える。
package points;
public class Point {
public int x, y;
public Point(int x, int y) { this.x = x; this.y = y; }
public String toString() { return toString(""); }
public String toString(String s) {
return "(" + x + "," + y + s + ")";
}
}
package points;
public class ColoredPoint extends Point {
public static final int
RED = 0, GREEN = 1, BLUE = 2;
public static String[] COLORS = { "red", "green", "blue" };
public byte color;
public ColoredPoint(int x, int y, int color) {
super(x, y); this.color = (byte)color;
}
/** Copy all relevant fields of the argument into
this ColoredPoint object. */
public void adopt(Point p) { x = p.x; y = p.y; }
public String toString() {
String s = "," + COLORS[color];
return super.toString(s);
}
}
ここでColoredPointを用いる三番目のコンパイル単位を考える。
import points.*;
class Test {
public static void main(String[] args) {
ColoredPoint cp =
new ColoredPoint(6, 6, ColoredPoint.RED);
ColoredPoint cp2 =
new ColoredPoint(3, 3, ColoredPoint.GREEN);
cp.adopt(cp2);
System.out.println("cp: " + cp);
}
}
cp: (3,3,red)
Testクラスを書いたアプリケーションプログラマは単語GREENを期待していた。 なぜなら,実際の引数,ColoredPointはcolorフィールドを持ち,colorは "適切なフィールド"のように見えるからである。(もちろん,Pointsパッケージに対するドキュメントはもっと正確であるべきである。
ところで,adoptのメソッド呼出しのために最も特殊なメソッド(実際,唯一の適用可能なメソッド)は一個のパラメータのメソッドを表すシグネチャを持ち,そのパラメータはPoint型であることに注意する。このシグネチャは,コンパイルにより生成されるTestクラスのバイナリ表現の一部となり,実行時にメソッド呼出しに使用される。
プログラマがこのソフトウェアエラーを報告し,pointsパッケージの管理者が,相応の考慮の後,クラスColoredPointに次のメソッドを追加することにより訂正することを決めたとする。
public void adopt(ColoredPoint p) {
adopt((Point)p); color = p.color;
}
アプリケーションプログラマがTestの古いバイナリを,ColoredPointの新しいライブラリとともに実行すると,出力は次のようになる。
cp: (3,3,red)
なぜならTestの古いバイナリファイルが,“パラメータ一個,型はpoint;void”という,メソッド呼出しcp.adopt(cp2)の記述子をまだ持っているからである。Testのソースコードを再コンパイルすると,コンパイラが今度は二つの適用可能なadoptメソッドがあり,シグネチャが“パラメータ一個,型はColoredPoint; void”というものがより特殊であることを 発見する。プログラムを実行すると,今度は望ましい出力を生成する。
cp: (3,3,green)
この問題をよく考えると,Pointsパッケージの管理者はColoredPointクラスを,まだColoredPointの引数で起動される古いコードのために古いadoptメソッドに対する防御コードを追加することにより,新たにコンパイルされたコードと古いコードの両方とも動作するように直すことができる。
public void adopt(Point p) {
if (p instanceof ColoredPoint)
color = ((ColoredPoint)p).color;
x = p.x; y = p.y;
}
同じような考察は,メソッドをスーパクラスに移動するときにあてはまる。 この場合フォワードメソッドが古いコードのためにあとに残されることがある。pointsパッケージの管理者は,すべてのPointオブジェクトはadoptの機能を享受できるようPoint引数をとるadoptメソッドをPointクラスまで移動するかもしれない。古いバイナリコードに関する互換性の問題をさけるため, 管理者はColoredPointクラスの中にフォワードメソッドを残すべきである。
public void adopt(Point p) {
if (p instanceof ColoredPoint)
color = ((ColoredPoint)p).color;
super.adopt(p);
}
理想的には,Javaコードは,それが依存するコードが変更されたときにいつも 再コンパイルされるべきである。しかしながら,異なるJavaクラスが異なる組織で 管理されている環境では,これはいつも実現可能ではない。クラスの変更の問題に対して注意深く考慮する防御的プログラミングは改版されたコードをより頑強にすることができる。バイナリ互換性と型の変更に関する詳細な議論については 13章を参照のこと。
メソッド呼出しのための最も特別なメソッド宣言があれば,それはメソッド呼出しのためのコンパイル時宣言と呼ばれる。 コンパイル時宣言に対してはさらに2つの検査を行う必要がある。
次に,実行時の使用のために以下のコンパイル時情報がメソッド呼出しと関連づけられる:
メソッド呼出しに対するコンパイル時宣言がvoidでないならば, メソッド呼出しの式の型はコンパイル時宣言で指定される返却値の型である。
実行時にメソッド呼出しは5つのステップを必要とする。 まず最初に,必要ならばターゲットへの参照が計算される。 2番目に,引数式が評価される。 3番目に,呼び出されるメソッドのアクセス指定が検査される。 4番目に,メソッドが実行される実際のコードを探す。 5番目に,新しい活性化フレームが作り出され,必要なら同期処理が実行され,制御がメソッドコードに移される。
MethodInvocation(15.11)の3つの生成規則のどれに関係するのかによって,いくつかの考えられるケースがある:
どちらのケースでもPrimary式の評価に失敗して終了すれば,引数式はまったく評価されることはなく,同様の理由でメソッド呼出しは失敗して終了する。
引数は左から右に順に評価される。 もし,1つでも引数式の評価が正常に行われない場合はその右にある引数の評価は行われず,同様の理由でメソッド呼出しも 失敗して終了する。
Cをメソッド呼出しを含むクラス,Tを呼び出されるメソッドを含んだクラス又はインタフェース,mをコンパイル時(15.11.3)に決定されるそのメソッドの名前と仮定する。
Java仮想計算機は,リンケージの一部としてメソッドmが既に型Tに存在していることを保証しなければならない。 これが真でないならばNoSuchMethodError (これはIncompatibleClassChangeErrorのサブクラスである。)が発生する。 呼出しのモードがinterfaceならば 仮想計算機は,ターゲットの参照型が既に指定されたインタフェースを実装しているかを検査しなければならない。 ターゲットの参照型がまだインタフェースを実装していない場合は,IncompatibleClassChangeErrorが発生する。
仮想計算機は,リンケージの間に型Tとメソッドmにアクセスできることも保証しなければならない。 型Tに対して:
T又はmがアクセス不可能な場合,IllegalAccessError (12.3)が発生する。
呼出しのモードがstaticならば, ターゲットの参照は必要なく,上書きも許されない。クラスTのメソッドmが呼び出されるメソッドになる。
そうでない場合,インスタンスメソッドが呼び出され,ターゲットの参照が存在する。 ターゲット参照がvoidならば,この時点で NullPointerException が投げられる。 そうでなければ,ターゲット参照はターゲットオブジェクトを参照すると言い,呼び出されたメソッドでthisキーワードの値として使用される。 次に,呼出しのモードのための他の四つの可能性を判断する。
呼出しのモードがnonvirtualならば, 上書きは許されない。クラスTのメソッドmが呼び出されるべきである。
そうでなければ,呼出しのモードはinterface,
virtual,superのいずれかになり,上書きされている可能性がある。
その場合,動的なメソッド検索が使用される。
動的な検索の過程はクラスSから始められ,以下の通り決定される:
動的なメソッド検索では,次の手順によってクラスSを探す。 次に必要ならばクラスSのスーパクラスを用いてメソッドmを探す。
この探索手順はクラスTに到達したときに適切なメソッドを見つけるはずで,そうでなければ前のセクション15.11.4.3の検査によって IllegalAccessError投げられているはずである。
ここで明示的に記述された動的探索過程がしばしば暗黙的に実装されるということには注意を要する。 例えばクラスごとのメソッドディスパッチテーブルの生成と使用,あるいは 効率的なディスパッチのために使用される他のクラスごとのコンストラクタの生成などの副作用として実装されることが多い。
あるクラスSのメソッドmは,呼び出されるべきものとして確認された。
次に,新しい活性化フレームが作り出される。 これは局所変数用の領域,呼び出されるメソッドが使用するスタック,その他すべての実装に必要な情報一覧 (スタックポインタ,プログラムカウンタ,前の活性化フレーム,および同様のものの参照)のための領域とともに, もしあればターゲットの参照や引数値を含んでいる。 もし,そのような活性化フレームを生成するのに利用可能な十分なメモリがない場合,OutOfMemoryError が投げられる。
新しく作り出された活性化フレームはカレント活性化フレームになる。 これにより,引数値を新たに作り出された対応するメソッドのパラメタ変数に割当てて,もし存在すればthisとして利用可能なターゲット参照を作る。
もし,メソッドmがnativeメソッドであり, 必要なネイティブの実装依存なバイナリコードがロードされていない (20.16.14, 20.16.13), 又はそうでなくても動的にリンクすることができない場合,UnsatisfiedLinkError が投げられる。
メソッドmがsynchronized宣言されていなければ, 制御は,呼び出されるメソッドmの本体に移る。
メソッドmがsynchronized宣言されていれば, 制御の移動の前にオブジェクトがロックされなければならない。 カレントスレッドがロックを獲得するまでは,それ以上処理を進めることはできない。 もし,ターゲット参照があれば,ロックされなければならない。 そうでない場合は,メソッドmが存在するクラスSのためのClassオブジェクトがロックされなければならない。 そして,制御が呼び出されるメソッドmの本体に移される。 オブジェクトは正常終了,異常終了に関わらず,メソッド本体の実行が終了した時点で自動的にアンロックされる。 ロックとアンロックはちょうどメソッドの本体がsynchronized文(14.17) に埋め込まれているかのように振る舞う。
ある種類のコード最適化を許容するために,実装は複数の活性化フレームを結合することが許されている。 クラスCの中のメソッド呼出しがクラスSの中のメソッドmを呼び出すと仮定する。 以下の条件の1つに当てはまる場合には,新しい活性化フレームを生成する代わりに 現在の活性化フレームをSが使用するための領域として提供する可能性がある:
ターゲット参照が計算され,次に呼出しのモードがstaticなのでそれが捨てられる場合, その参照がnullであるかどうかは検査されない。
class Test {
static void mountain() {
System.out.println("Monadnock");
}
static Test favorite(){
System.out.print("Mount ");
return null;
}
public static void main(String[] args) {
favorite().mountain();
}
}
Mount Monadnock
ここでfavoriteはnullを返すが, NullPointerExceptionは投げられない。
インスタンスメソッド呼出し(15.11)の一部として, 呼び出されるオブジェクトを指示する式がある。 この式はメソッド呼出しの引数式のどの部分よりも前に完全に評価される。
class Test {
public static void main(String[] args) {
String s = "one";
if (s.startsWith(s = "two"))
System.out.println("oops");
}
}
.startsWithの前のsは 引数であるs="two"よりも先に最初に評価される。 したがって,ターゲット参照としての文字列"one"への参照は 局所変数sが文字列"two"への参照に変えられる前に記憶される。 その結果startsWithメソッド(20.12.20)は 引数"two"を持ったターゲットオブジェクト"1"に対して呼び出される。 したがって,文字列"one"は"two"で始まらないので,呼出しの結果はfalseとなり,テストプログラムはoopsを印刷しない。
class Point {
final int EDGE = 20;
int x, y;
void move(int dx, int dy) {
x += dx; y += dy;
if (Math.abs(x) >= EDGE || Math.abs(y) >= EDGE)
clear();
}
void clear() {
System.out.println("\tPoint clear");
x = 0; y = 0;
}
}
class ColoredPoint extends Point {
int color;
void clear() {
System.out.println("\tColoredPoint clear");
super.clear();
color = 0;
}
}
サブクラスColoredPointはそのスーパクラスPointで定義された抽象化clearを継承する。これはclearメソッドを自分のメソッドで上書きし,それはsuper.clearの形式を用いてスーパクラスのclearメソッドを呼出している。
clearの呼出しのターゲットオブジェクトがColoredPointであるときには常にこのメソッドが呼び出される。 Pointの中のmoveメソッドがcodeColoredPointのclear メソッドを呼出した場合ですらそうである。 この場合,このテストプログラムの出力が示すようにthisのクラスはColoredPointになる。
class Test {
public static void main(String[] args) {
Point p = new Point();
System.out.println("p.move(20,20):");
p.move(20, 20);
ColoredPoint cp = new ColoredPoint();
System.out.println("cp.move(20,20):");
cp.move(20, 20);
p = new ColoredPoint();
System.out.println("p.move(20,20), p colored:");
p.move(20, 20);
}
}
p.move(20,20):
Point clear
cp.move(20,20):
ColoredPoint clear
Point clear
p.move(20,20), p colored:
ColoredPoint clear
Point clear
上書きは「遅延束縛された自己参照」と呼ばれることがある。 その意味は,たとえばPoint.move(これは本当はthis.clearの構文上の略記である) の中のclearへの参照は,コンパイル時にthisの型に基づいて「早く」選択されたメソッドではなく,実行時にthisで参照されるオブジェクトの実行時クラスに基づいて「遅く」選択されたメソッドを呼び出すということである。 これはJavaプログラマに抽象化を拡張する強力な方法を提供するとともに,オブジェクト指向プログラミングでの重要な考えでもある。
直接のスーパクラスのメンバにアクセスするためにキーワードsuperを使用することによって, スーパクラスの上書きされたインスタンスメソッドにアクセスすることが可能である。 この時そのメソッド呼出しを含むクラス中のどの上書き宣言も無視することになる。
インスタンス変数にアクセスする際はsuper はthis(15.10.2)をキャストしたものに等しいが,この等価性はメソッド呼出しに当てはまらない。 これを例によって示す:
class T1 {
String s() { return "1"; }
}
class T2 extends T1 {
String s() { return "2"; }
}
class T3 extends T2 {
String s() { return "3"; }
void test() {
System.out.println("s()=\t\t"+s());
System.out.println("super.s()=\t"+super.s());
System.out.print("((T2)this).s()=\t");
System.out.println(((T2)this).s());
System.out.print("((T1)this).s()=\t");
System.out.println(((T1)this).s());
}
}
class Test {
public static void main(String[] args) {
T3 t3 = new T3();
t3.test();
}
}
s()= 3 super.s()= 2 ((T2)this).s()= 3 ((T1)this).s()= 3
型T1やT2へのキャストによって 呼び出されるメソッドは変わらない。これは呼び出されるべきインスタンスメソッドは,thisによって参照されるオブジェクトの実行時のクラスによって選択されるからである。 キャストはオブジェクトのクラスを変えない。 クラスが指定された型に当てはまるかどうかを検査するだけである。
ArrayAccess:
ExpressionName [ Expression ]
PrimaryNoNewArray [ Expression ]
配列アクセス式は左角括弧の前の配列参照式および角括弧の中のインデクス式の2つの副式からなる。配列参照式は配列生成式(15.9)でない一次式や名前かもしれないことに注意。
配列参照式の型は配列型でなければならない(それを構成要素の型がTの配列であるT[]とする。),そうでないと,翻訳時エラーが生じる。配列アクセス式の型はTである。
インデクス式は単項数値拡張 (5.6.1)を受けてintでなければならない。
配列参照の結果は型Tの変数,すなわち,インデクス式の値に よって選択される配列中の変数である。配列構成要素であるこの変数は finalとは決して考えられない。たとえ,配列参照が final変数から得られたとしてもである。
配列アクセスでは,括弧の左の式は括弧の中の式のどんな部分よりも前に完全に評価される。例えば,式a[(a=b)[3]]では, 式aが式(a=b)[3]よりも前に完全に評価される; これは,式(a=b)[3]の評価の間,式aの元の値が取って来られ,覚えられているということを意味する。つまり, aの元の値によって参照されたこの配列の,bによって参照された(今はaも参照している)配列の3番目の要素を示す。
class Test {
public static void main(String[] args) {
int[] a = { 11, 12, 13, 14 };
int[] b = { 0, 1, 2, 3 };
System.out.println(a[(a=b)[3]]);
}
}
14
式の値は,a[b[3]],又はa[3],又は 14と同等である。
括弧の左の式の評価が中途完了するとき,括弧の中の式のどんな部分も評価されない。例を示す。
class Test {
public static void main(String[] args) {
int index = 1;
try {
skedaddle()[index=2]++;
} catch (Exception e) {
System.out.println(e + ", index=" + index);
}
}
static int[] skedaddle() throws Exception {
throw new Exception("Ciao");
}
}
java.lang.Exception: Ciao, index=1
配列参照式が配列への参照ではなく,nullを生成する場合, NullPointerExceptionが実行時に投げられる。ただし,配列参照式のすべての部分が評価され,正常完了したあとである。次に例をしめす。
class Test {
public static void main(String[] args) {
int index = 1;
try {
nada()[index=2]++;
} catch (Exception e) {
System.out.println(e + ", index=" + index);
}
}
static int[] nada() { return null; }
}
java.lang.NullPointerException, index=2
2のindexへの代入は空ポインタの検査の前に起こる。関係するプログラム例をあげる。
class Test {
public static void main(String[] args) {
int[] a = null;
try {
int i = a[vamoose()];
System.out.println(i);
} catch (Exception e) {
System.out.println(e);
}
}
static int vamoose() throws Exception {
throw new Exception("Twenty-three skidoo!");
}
}
java.lang.Exception: Twenty-three skidoo!
NullPointerExceptionは決して起きない。 すべてのインデクス操作が起こる前にインデクス式は完全に評価されている。インデクス操作には,左辺値がnullかどうかの検査を含む。
後置式は++や--の後置演算子を含む。 また,15.7で議論するように,名前は一次式とは考えられず,あいまいさを避けるために別に扱われる。 それらは後置式の優先順位のレベルで交換可能になる。
PostfixExpression:
Primary
ExpressionName
PostIncrementExpression
PostDecrementExpression
式で現れる名前は構文上ExpressionNameとなる(6.5)。 ExpressionNameの意味はその形に依存する:
PostIncrementExpression:
PostfixExpression ++
++演算子があとに続いた後置式は後置インクリメント式 である。後置式の結果が数値型の変数でなければ,翻訳時エラーが発生する。後置インクリメント式の型は変数の型である。後置インクリメントの式の結果は変数ではなく,値である。
実行時,オペランド式の評価が中途完了すると,後置インクリメント式も同じ理由で中途完了し,どんなインクリメントも起こらない。そうでなけ れば,値1が変数の値に加えられ,合計は変数に格納される。加算の前に,バイナリ数値拡張(5.6.2)が値 1と変数に実行される。その合計は格納前に必要なら,その変数の型へのナローイングプリミティブ変換(5.1.3)によってナローイングされる。 後置インクリメント式の値は,新しい値が格納される前の変数の値である。
finalと宣言される変数を加算することはできない。 final変数へのアクセスが式として使用されたとき,結果は変数 ではなく,値である。したがって,後置インクリメントの演算子のオペラ ンドとしてそれを使用することはできない。
PostDecrementExpression:
PostfixExpression --
--演算子があとに続いた後置式は後置デクリメント式である。 後置式の結果が数値型の変数でなければ,翻訳時エラーが発生する。 後置デクリメント式の型は変数の型である。後置デクリメント式の結果は変数ではなく,値である。
実行時,オペランド式の評価が中途完了すると,後置デクリメント式も同じ理由で中途完了し,どんなデクリメントも起こらない。そうでなければ,値1が変数の値から引き算され,結果が変数に格納される。引き算の前に,バイナリ数値拡張(5.6.2)が値1と変数に実行される。その計算結果は格納前に必要なら,その変数の型へのナローイングプリミティブ変換(5.1.3)によってナローイングされる。 後置デクリメント式の値は,新しい値が格納される前の変数の値である。
finalと宣言される変数から引き算することはできない。 final変数へのアクセスが式として使用されたとき,結果は変数ではなく,値である。したがって,後置デクリメント演算子のオペランドとして使用することはできない。
単項演算子は,+, -, ++,--, ~, !,そしてキャスト演算子を含む。単項演算子をもった式は右から左へグループ化する。つまり, -~xは,-(~x)と同じ意味である。
UnaryExpression:
PreIncrementExpression
PreDecrementExpression
+ UnaryExpression
- UnaryExpression
UnaryExpressionNotPlusMinus
PreIncrementExpression:
++ UnaryExpression
PreDecrementExpression:
-- UnaryExpression
UnaryExpressionNotPlusMinus:
PostfixExpression
~ UnaryExpression
! UnaryExpression
CastExpression
15.15の以下の表現を,便宜上ここ で繰り返す:
CastExpression:
( PrimitiveType ) UnaryExpression
( ReferenceType ) UnaryExpressionNotPlusMinus
Java文法のこの部分は2個の潜在的構文的あいまいさを避けるいくつかのトリックを含む。
最初の潜在的あいまいさは(p)+qのような式で起きる。CやC++プ ログラマにとっては,qへの単項演算子+を型 pへキャストしたものか,若しくは,2つの量pと qの加算のように見える。CやC++では,限られた量の意味解析をパーサが実行することによってこの問題を扱う。つまり,pが型名か変数名かどちらであるか調べる。 Javaは異なったアプローチを取る。+演算子の結果は数値に違いなく,数値にキャストを引き起こすすべての型名は知られているキーワードである。つまり,もしpがプリミティブ型を示すキーワードならば,(p)+qは単項式へのキャストとしてだけ感知される。しかしながら,pがプリミティブ型の名前では無い場合,(p)+qは二項数値演算としてだけ感知される。 -演算子についても同様である。上で示された文法は CastExpressionをこの区別をする二つのケースへ分ける。非終端記号 UnaryExpressionはすべての単項演算子を含んで,非終端記号 UnaryExpressionNotPlusMinusは,2項演算子かもしれないすべての単項演算子を除く。それは,Javaでは,+と- である。
2番目の潜在的あいまいさは,式(p)++が,CやC++プログラマに とっては,カッコで括られた式の後置インクリメントか,若しくは, (p)++qのようなキャストの開始としてとれることである。 事前に,CやC++のパーサはpが型の名前か変数名か知っている。しかし,1トークンだけを先読みして,パースの間に文法解析を行なわな いパーサは,++が先読み対象トークンの時に, (p)がPrimary式なのか,CastExpressionの一部として後の考慮のために残すものかがわからない。 Javaでは,++演算子の結果は数値に違いなく,数値にキャストを引き起こすすべての型名は知られているキーワードである。つまり, もしpがプリミティブ型を示すキーワードならば, (p)++は前置インクリメント式へのキャストとして,そして, qのようなオペランドが++の後に存在するべき事を感知する。しかしながら,pがプリミティブ型の名前では 無い場合,(p)++はpの後置インクリメント式としてだけ感知される。 --演算子についても同様である。非終端記号 UnaryExpressionNotPlusMinusはそれゆえ,++と --の前置演算子を含まない。
++演算子が先行した単項式は前置インクリメント式である。 単項式の結果が数値型の変数でなければ,翻訳時エラーが起こる。 前置インクリメント式の型は変数の型である。前置インクリメント式の結果は変数ではなく,値である。
実行時,オペランド式の評価が中途完了すると,同じ理由で前置インクリメント式は中途完了し,どんな加算も起こらない。そうでなければ,値 1が変数の値に加えられ,合計は変数に格納される。加算の前に, 2項数値拡張(5.6.2)が値 1と変数の値に実行される。必要なら,その合計は,格納前にその変数の型へのナローイングプリミティブ変換(5.1.3)によってナローイングされる。 前置インクリメント式の値は,新しい値が格納された後の変数の値である。
finalと宣言される変数へ加算することはできない。 final変数へのアクセスが式として使用されたとき,結果は変数 ではなく,値である。したがって,前置インクリメントの演算子のオペラン ドとしてそれを使用することはできない。
--演算子が先行した単項式は前置デクリメントの式ある。 単項式の結果が数値型の変数でなければ,翻訳時エラーが起こる。 前置デクリメント式の型は変数の型である。前置デクリメント式の結果は変数ではなく,値である。
実行時,オペランド式の評価が中途完了すると,同じ理由で前置デクリメント式は中途完了し,どんな引き算も起こらない。そうでなければ,値 1が変数の値から引かれ,差分は変数に格納される。引き算の前に,2項数値表現(5.6.2)が値 1と変数の値に実行される。必要なら,その差分は,格納前にその変数の型へのナローイングプリミティブ変換(5.1.3)によってナローイングされる。 前置デクリメント式の値は,新しい値が格納された後の変数の値である。
finalと宣言される変数から引き算することはできない。 final変数へのアクセスが式として使用されたとき,結果は変数ではなく,値である。したがって,前置インクリメント演算子のオペランドとしてそれを使用することはできない。
単項+演算子の式のオペランドの型がプリミティブ数値型でなければ,翻訳時エラーが起こる。単項数値拡張(5.6.1)がそのオペランドに実行される。 単項加算式の型は拡張されたオペランドの型である。 オペランドの結果が変数でも,単項加算式の結果は変数ではなく,値である。
単項-演算子式のオペランドの型がプリミティブ数値型でなければ,翻訳時エラーが起こる。単項数値拡張(5.6.1)がそのオペランドに実行される。 単項マイナス式の型は拡張されたオペランドの型である。
実行時,単項マイナス式の値はオペランドの拡張値の算術的否定値である。
整数値において,否定はゼロからの引き算と同じである。Javaは2の補数表現を使用する。2の補数の範囲は対称でなく,それで,最大の負の intやlongの否定は最大の負数となる。 この場合オーバフローが起こるが,どんな例外も投げられない。 すべての整数値xのために, -x は (~x)+1に等しい。
浮動小数点値において,算術否定はゼロからの引き算と同じでない。 xが+0.0のとき,0.0-xは +0.0に等しい。しかし,-xは-0.0 に等しい。単項マイナス演算は浮動小数点の符号を単に逆にする。特別な場合を以下に考慮する:
単項~式のオペランドの型が,プリミティブの整数型でなければ,翻訳時エラーが起きる。単項数値拡張(5.6.1)がオペランドに実行される。単項ビット補数式の型はオペランドの拡張された型である。
実行時,単項ビット補数式の値は,オペランドの拡張された値のビット補数となる。注意: すべての場合で~xは,(-x)-1に等しい。
単項!演算子のオペランド式の型がbooleanでなければ,翻訳時エラーが起きる。 単項論理補数式の型はbooleanである。
実行時,単項論理補数式は,もし,オペランドの値が falseなら,trueとなり,オペランドの値が trueなら,falseとなる。
booleanかどうかを確認すること,実行時に参照値が指定した参照型と互換性のあるクラスのオブジェクトを参照していることを検査すること,を行う。
CastExpression:
( PrimitiveType Dimsopt ) UnaryExpression
( ReferenceType ) UnaryExpressionNotPlusMinus
UnaryExpression及びUnaryExpressionNotPlusMinusの違いについては,15.14を参照のこと。キャスト式の型は,括弧内に出現する指定した名前の型とする。(括弧及び括弧が含む型をキャスト演算子(cast operator)と呼ぶことがある。)キャスト式の結果は,そのオぺランドの式の結果が変数であっても,変数ではなく値とする。
実行時に,オぺランドの値をキャスト型変換(5.4) によってキャスト演算子で指定した型に変換する。
Java言語では,すべてのキャストが許されるわけではない。キャストのあるものは,コンパイル時エラーを生じる。例えば,プリミティブ型の値は,参照型にキャストしてはいけない。また,他のキャストは,実行時には常に正しいとコンパイル時に保証できる。 例えば,あるクラス型の値を,そのクラスのスーパサブクラスの型に変換することは常に正しい。このようなキャストは,実行時に特別な動作を要求しないことが望ましい。最後に,常に正しいか常に正しくないかをコンパイル時に特定できないキャストもある。受け入れられないキャストを実行時に検出すると,ClassCastExceptionが投げられる。
*,/ 及び % は,乗除演算子(multiplicative operators)と呼ぶ。これらは同じ優先順位をもち,構文的に左結合とする(左から右にグループ化する)。
MultiplicativeExpression:
UnaryExpression
MultiplicativeExpression * UnaryExpression
MultiplicativeExpression / UnaryExpression
MultiplicativeExpression % UnaryExpression
乗除演算子のオぺランドの各々の型は,プリミティブ数値型でなければならない。 そうでないときには,コンパイル時エラーが発生する。オぺランドに対して2項数値昇格を実行する(5.6.2)。乗除式の型は,そのオぺランドの昇格した型とする。昇格した型がint又はlongならば,整数演算を実行する。昇格した型がfloat又はdoubleまらば,浮動小数点演算を実行する。
** 演算子は乗算を実行し,そのオぺランドの積を生成する。オぺランドの式が副作用をもたなければ,乗算は可換的演算とする。整数の乗算は,オぺランドがすべて同じ型のとき結合的とするが,浮動小数点乗算は結合的としない。
整数の乗算がオーバフローした場合,結果は数学的な積を十分大きな2の補数形式で表現したときの低位ビットとする。その結果として,オーバフローが発生した場合,結果の符号は二つのオぺランド値の数学的積の符号と同じでないかもしれない。
浮動小数点の乗算の結果は,IEEE 754 算術の規則に従う。
* は決して実行時例外を投げない。
// 演算子は除算を実行し,オぺランドの商を生成する。左辺オぺランドは被除数とし,右辺オぺランドは除数とする。
整数の除算は結果を0方向に丸める。つまり,2項数値昇格(5.6.2) 実行後の整数のオぺランド n 及び dに対して生成される商は,整数値q とし,その大きさは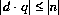 を満足する可能な限り大きい値とする。さらに,
を満足する可能な限り大きい値とする。さらに,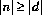 であって n 及び d が同じ符号のとき q は正とする。しかし,
であって n 及び d が同じ符号のとき q は正とする。しかし,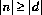 であって n 及び,d が反対の符号をもつとき q は負とする。この規則を満足しない特別な場合が一つだけ存在する。被除数がその型に対して可能な最大の大きさの負の整数であって,除数が
であって n 及び,d が反対の符号をもつとき q は負とする。この規則を満足しない特別な場合が一つだけ存在する。被除数がその型に対して可能な最大の大きさの負の整数であって,除数が-1ならば,整数オーバフローが発生し結果は被除数と同じとする。オーバフローするにもかかわらず,この場合いかなる例外も投げられない。一方,整数の除算における除数の値が0ならば,ArithmeticExceptionが投げられる。
浮動小数点の除算の結果は IEEE 算術の規定によって決定する。
/ の評価は決して実行時例外を投げない。
%% 演算子は暗黙の除算によってオぺランドの剰余を生成する。左辺オぺランドは被除数とし,右辺オぺランドは除数とする。
C 及び C++ では,剰余演算子は整数オぺランドだけを受け入れるが,Javaでは浮動小数点のオペランドも受け入れる。
2項数値昇格(5.6.2) 実行後の整数のオぺランドに対する剰余演算は,(a/b)*b+(a%b) が a に等しいとする結果を生成する。この恒等式は,被除数をその型に対する可能な最大の大きさの負数とするとき,及び除数が -1(剰余は 0)のときの特別な場合においても成立する。この規則から次のことがいえる。剰余演算の結果は,被除数が負のときにだけ負とでき,被除数が正のときにだけ正とできる。さらに,結果の大きさは常に除数の大きさより小さい。整数の剰余演算子に対する除数の値が0ならば,ArithmeticExceptionが投げられる。
5%3 の結果は 2 (5/3 の結果は 1に注意すること) 5%(-3) の結果は 2 (5/(-3) の結果は -1 に注意すること) (-5)%3 の結果は -2 ((-5)/3 の結果は -1 に注意すること) (-5)%(-3) の結果は -2 ((-5)/(-3) の結果は 1 に注意すること)
% 演算子によって計算する浮動小数の剰余演算の結果は,IEEE 754で定義された剰余演算で生成される結果とは異なる。IEEE 754 の剰余演算は,丸め除算によって計算し,切り捨て除算では計算しない。そのため,その振舞いは通常の整数の剰余演算子と類似しない。代わりに,Java言語では,浮動小数点演算に関する % 演算をJavaの整数剰余演算子と類似して振る舞うように定義する。これは,Cライブラリ関数fmodに相当する。 IEEE 754の剰余演算はJavaライブラリルーチンの Math.IEEEremainder (20.11.14)によって計算できる。Javaの浮動小数点演算の結果は,IEEE 算術 の規則によって規定される。
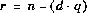 によって定義する。ここで, q は,
によって定義する。ここで, q は,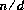 が負のときにだけ負とし,
が負のときにだけ負とし,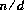 が正のときにだけ正整数とする。その大きさは,n 及び dの真の数学的な商の大きさを超えない可能な限り大きいものとする。
が正のときにだけ正整数とする。その大きさは,n 及び dの真の数学的な商の大きさを超えない可能な限り大きいものとする。
0 となるにもかかわらず,浮動小数点数の剰余演算子 % の評価は決して実行時例外を投げない。
5.0%3.0 の結果は 2.0 5.0%(-3.0) の結果は 2.0 (-5.0)%3.0 の結果は -2.0 (-5.0)%(-3.0) の結果は -2.0
+ 及び - は加減演算子と呼ぶ。これらは同じ優先順位をもち,構文的に左結合とする(左から右にグループ化する)。
AdditiveExpression:
MultiplicativeExpression
AdditiveExpression + MultiplicativeExpression
AdditiveExpression - MultiplicativeExpression
+ 演算子のいずれかのオぺランドの型がStringならば,演算は文字列の連結とする。
そうでないときには,+ 演算子の各オペランドの型は,プリミティブ数値型でなければならない。そうでないときには,コンパイル時エラーが発生する。
すべての場合において,2項 - 演算子の各オペランドは,プリミティブ数値型でなければならない。そうでないときには,コンパイル時エラーが発生する。
+Stringならば,実行時に文字列を生成するために,他方のオペランドに対して文字列変換を実行する。結果は二つのオペランドの文字列を連結して新たに作成したオブジェクト String への参照とする。新たに作成した文字列内では,左辺オぺランドの文字が右辺オぺランドの文字に先行する。
String に変換できる。
最初に,プリミティブ型 T の値 x を,適切なクラスインスタンス生成式への実引数にその値を与えたかのように参照値に変換する。
booleanならば,new Boolean(x) (20.4)を使用する。
charならば,new Character(x) (20.5)を使用する。
byte,short又は intならば,new Integer(x) (20.7)を使用する。
longならば,new Long(x) (20.8)を使用する。
floatならば,new Float(x) (20.9)を使用する。
doubleならば,new Double(x) (20.10)を使用する。
String に変換する。
その後は,参照値だけを考慮する必要がある。参照がnullならば,文字列 "null" (四つのASCII文字 n,u,l,l)に変換する。そうでないときには,参照しているオブジェクトのメソッド toString を実引数なしで呼び出したかのように変換を実行する。しかし,メソッド toString の呼出し結果がnullならば,文字列 "null" を代わりに使用する。メソッド toString(20.1.2) は,標準クラスObjectで定義される。多くのクラスがそれを上書きしている。代表的なものにはBoolean,Character,Integer,Long,Float,Double 及びStringがある。
Stringの作成及び廃棄を避けるために,変換及び連結を一段階で実行してもよい。Javaコンパイラは,繰り返される文字列連結の性能向上を目的として,式の評価によって作成される中間的なオブジェクト String の数を減らすために,クラス StringBuffer(20.13) 又は同様な技術を使用してもよい。
プリミティブ型のオブジェクトに対しては,処理系は,プリミティブ型から直接文字列に変換することによって,ラッパーオブジェクトの作成を最適化してもよい。
"The square root of 2 is " + Math.sqrt(2)これは次の結果を生成する。
"The square root of 2 is 1.4142135623730952"型の解析によって,
+ 演算子が文字列連結を表現するか又は加算を表現するかを,後に決定されるかどうかにかかわらず,+ 演算子は構文的に左結合とする。望む結果を得るためには,注意が要求されることもある。次の式を考える。
a + b + cこれは,常に次の式を意味すると見なす。
(a + b) + cしたがって,次の式
1 + 2 + " fiddlers"の結果は次のようになる。
"3 fiddlers"しかし,次の式
"fiddlers " + 1 + 2の結果は次のようになる。
"fiddlers 12"ここで少し面白い例を示す。
class Bottles {
static void printSong(Object stuff, int n) {
String plural = "s";
loop: while (true) {
System.out.println(n + " bottle" + plural
+ " of " + stuff + " on the wall,");
System.out.println(n + " bottle" + plural
+ " of " + stuff + ";");
System.out.println("You take one down "
+ "and pass it around:");
--n;
plural = (n == 1) ? "" : "s";
if (n == 0)
break loop;
System.out.println(n + " bottle" + plural
+ " of " + stuff + " on the wall!");
System.out.println();
}
System.out.println("No bottles of " +
stuff + " on the wall!");
}
}
メソッド printSong はある童謡の替え歌を印刷する。stuff として人気のある値は "pop"及び "beer" を含む。 nとしても最も人気がある値は100である。次に,Bottles.printSong("slime", 3)の結果出力を示す。
3 bottles of slime on the wall, 3 bottles of slime; You take one down and pass it around: 2 bottles of slime on the wall! 2 bottles of slime on the wall, 2 bottles of slime; You take one down and pass it around: 1 bottle of slime on the wall! 1 bottle of slime on the wall, 1 bottle of slime; You take one down and pass it around: No bottles of slime on the wall!このコード内では,適切なときには複数形の"
bottles"よりも単数形の"bottle" を注意深く条件に従って生成することに注意すること。文字列連結演算子を,長い文字列定数の分割のために使用した方法も注意すること。
"You take one down and pass it around:"ソースコード内で,不便なほどに長くなることを避けるために,この定数を二つに分けている。
+ 及び - )+ 演算子は,二つのオぺランドが数値型のとき加算を実行し,オぺランドの和を生成する。2項 - 演算子は,減算を実行し,二つの数値オぺランドの差を生成する。
2項数値昇格はオペランド上で実行する(5.6.2)。数値オぺランド上の加減式の型は,そのオぺランドの昇格した型とする。この昇格した型が int 又は long ならば,整数算術を実行する。この昇格した型がfloat又はdoubleならば,浮動小数点算術を実行する。
オぺランドの式が副作用をもたなければ,加算は可換的な演算とする。オペランドがすべて同じ型のとき,整数の加算は結合的とする。しかし,浮動小数点の加算は結合的としない。
整数の加算がオーバフローすれば,結果は数学的な和を十分大きな2の補数形式で表現したときの低位ビットとする。オーバフローが発生すれば,結果の符号は,二つのオぺランド値の数学的和の符号と同じではない。
浮動小数点の加算の結果は,IEEE 754 算術の次の規則で決定する。
- 演算子は,二つの数値型のオぺランドに適用したとき減算を実行し,オぺランドの差を生成する。左辺オぺランドは被減数とし,右辺オぺランドは減数とする。 整数及び浮動小数点数の減算の両方について,常に a-b は a+(-b) と同じ結果を生成する。 次の点に注意すること。整数値については,ゼロからの減算は符号反転と同じとする。しかし,浮動小数点数のオぺランドについては,ゼロからの減算は符号反転と同じとはしない。その理由は,x が +0.0 ならば 0.0-x は +0.0 に等しいが,-x は -0.0 に等しい。オーバフロー,アンダフロー又は情報の損失が発生するかもしれない事実にもかかわらず,数値加減演算子の評価は決して実行時例外を投げない。
<<,符号付き右シフト >>,及び 符号無し右シフト >>>を含む。 それらは構文的に左結合とする(左から右にグループ化する)。シフト演算子の左辺オぺランドはシフトされる値とし,右辺オぺランドでシフト幅を指定する。
ShiftExpression:
AdditiveExpression
ShiftExpression << AdditiveExpression
ShiftExpression >> AdditiveExpression
ShiftExpression >>> AdditiveExpression
シフト演算子のオぺランドの型は,プリミティブ整数の型でなければならない。そうでないときにはコンパイル時エラーが発生する。各オペランドに対して2項数値昇格(5.6.2) は実行しないが,単項数値昇格(5.6.1) を各オぺランドに対し別々に実行する。 シフト演算式の型は,左辺オぺランドの昇格した型とする。
左辺オぺランドの昇格した型が int ならば,右辺オぺランドの下位5ビットだけをシフト幅として使用する。それは,右辺オペランドが,マスク値 0x1f を用いたビット単位のAND演算子 & (15.21.1) に従うかのようとする。したがって実際に使用するシフト幅は, 0 から 31 までの範囲とする。
左辺オぺランドを昇格した型が long ならば,右辺オぺランドの下位6ビットだけをシフト幅として使用する。それは,右辺オペランドが,マスク値 0x3fを用いたビット単位のAND演算子 & (15.21.1) に従うかのようとする。したがって実際に使用するシフト幅は, 0 から 63 までの範囲とする。
実行時には,シフト演算は左辺オぺランド値の2の補数表現に対して実行する。
n<<s の値は n のビット位置を s ビット左にシフトしたものとする。 これは,(オーバフローが発生しても)2のs乗の乗算に等しい。
n>>s の値は, n のビット位置を符号拡張を伴って s ビット右にシフトしたものとする。結果の値は 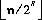 とする。 非負数
とする。 非負数 n に対しては,これは,整数除算演算子 / によって計算される2の s乗の切り捨て整数除算に等しい。
n>>>s の値は n のビット位置をゼロ拡張を伴って s ビット右にシフトしたものとする。n が正ならば,結果は n>>s と同じとする。n が負のとき,左辺オぺランドの型がintならば結果は式 (n>>s)+(2<<~s) と同じとし,左辺オぺランドの型が long ならば結果は式 (n>>s)+(2L<<~s) と同じとする。 追加項 (2<<~s) 又は (2L<<~s) は,伝播された符号ビットを除去する。(シフト演算子の右辺オぺランドに対する暗黙のマスクのために,シフト幅 ~s は,int 値をシフトするときは 31-s に等しく,long 値をシフトするときは 63-s に等しいことに注意すること。)
a<b<c を(a<b)<cと構文解析するが,a<b の型は常にbooleanであって,< は boolean値に対する演算子ではないために,これは常にコンパイル時エラーとなる。
RelationalExpression:
ShiftExpression
RelationalExpression < ShiftExpression
RelationalExpression > ShiftExpression
RelationalExpression <= ShiftExpression
RelationalExpression >= ShiftExpression
RelationalExpression instanceof ReferenceType
関係式の型は,常にbooleanとする。
<, <=, >, 及び >= int 又は longならば,符号付き整数比較を実行する。昇格した型が float 又は doubleならば,浮動小数点比較を実行する。
浮動小数点比較の結果は,IEEE 754 規格の規格によって決定されるように,次のとおりとする。
falseとする。
-0.0<0.0 はfalseとするが,-0.0<=0.0 はtrueとする。(しかしながら,メソッドMath.min (20.11.27, 20.11.28)及びMath.max (20.11.31, 20.11.32) は,負のゼロを正の値よりも厳密に小さいとして扱うことに注意すること。)
< 演算子によって生成する値は,左辺オぺランドの値が右辺オぺランドの値より小さければ,trueとする。そうでないときにはfalseとする。
<= 演算子によって生成する値は,左辺オぺランドの値が右辺オぺランドの値より小さい又は等しければ,trueとする。そうでないときにはfalseとする。
> 演算子によって生成する値は,左辺オぺランドの値が右辺オぺランドの値より大きければ,true とする。そうでないときにはfalseとする。
>= 演算子によって生成する値は,左辺オぺランドの値が右辺オぺランドの値より大きい又は等しければ,trueとする。そうでないときにはfalseとする。
instanceofinstanceof演算子のRelationalExpressionオぺランドの型は,参照型又は空型でなければならない。そうでないときには,コンパイル時エラーが発生する。instanceof演算子の後に記述する ReferenceType は,参照型又は空型でなければならない。そうでないときには,コンパイル時エラーが発生する。
実行時におけるinstanceof演算子の結果は,RelationalExpressionの値がnullでなく,参照が例外ClassCastExceptionを投げずにReferenceTypeへとキャスト(15.15) できれば,trueとする。そうでないときには,結果はfalseとする。
RelationalExpression からReferenceType へのキャストがコンパイル時エラーとして拒否されれば,instanceof 関係式も同じようにコンパイル時エラーを生じる。このような状況では,instanceof式の結果は決してtrueとはならない。
class Point { int x, y; }
class Element { int atomicNumber; }
class Test {
public static void main(String[] args) {
Point p = new Point();
Element e = new Element();
if (e instanceof Point) { // compile-time error
System.out.println("I get your point!");
p = (Point)e; // compile-time error
}
}
}
この例は,二つのコンパイル時エラーを生じる。キャスト(Point)eは正しくない。その理由は,Element自体のインスタンス及び可能なサブクラス(この例では示されていないが)は,Pointのサブクラスのインスタンスになることができないためである。instanceof式も同じ理由で正しくない。一方,PointがElementのサブクラスとする(この例では明らかに奇妙な表記だが)次を考える。
class Point extends Element { int x, y; }
このとき,実行時検査を要求するが,キャストは可能で,instanceof式は意味があり妥当となる。キャスト (Point)e は決して例外を投げない。その理由は,値 e が型Pointに正しくキャストできなければキャストを実行しないためである。
a==b==c は (a==b)==c と構文解析する。a==b の結果の型は常に booleanで,c は型 boolean でなければならない。 そうでないときには,コンパイル時エラーが発生する。つまり,a==b==c は ,a, b 及び c がすべて等しいかどうかを検査しない。
EqualityExpression:
RelationalExpression
EqualityExpression == RelationalExpression
EqualityExpression != RelationalExpression
== (等価) 及び != (不等価) 演算子は,優先順位が低いという点を除いて関係演算子と類似する。したがって,a<b==c<d は,a<b 及び c<d が同じ真値をもつときには,常に trueとする。
等価演算子は,数値型の二つのオぺランド,型 boolean の二つのオぺランド又はそれぞれが参照型若しくは空型の二つのオぺランドを比較するために使用可能とする。その他のすべての場合は,コンパイル時エラーを生じる。等価式の型は常にbooleanとする。
すべての場合において,a!=b は !(a==b)と同じ結果を生成する。オぺランド式が副作用をもたなければ,等価演算子は可換的とする。
== 及び != int 又は long ならば,整数等価試験を実行する。昇格した型が float 又は double ならば,浮動小数点等価試験を実行する。
浮動小数点等価試験は,IEEE 754 規格の規則に従って実行する。
== の結果はfalseとし,!= の結果は trueとする。実際に,試験x!=x の結果は,xの値が NaNのときにだけ真とする。(値が NaNかどうかを試験するために,メソッド Float.isNaN (20.9.19) 及び Double.isNaN (20.10.17) を使用可能とする。)
-0.0==0.0は true とする。
== 演算子によって生成する値は,左辺オぺランドの値が右辺オぺランドの値と等しければ,trueとする。そうでないときには,結果は falseとする。
!= 演算子によって生成する値は,左辺オぺランドの値が右辺オぺランドの値と等くなければ,trueとする。そうでないときには,結果は falseとする。
== 及び != boolean ならば,演算は論理型等価とする。論理型等価演算子は,結合的とする。
== の結果は,オぺランドが両方ともtrue又は両方ともtrueならば,trueとする。そうでないときには,結果はfalseとする。
!= の結果は,オぺランドが両方ともtrue又は両方ともtrueならば,falseとする。そうでないときには,結果はtrueとする。したがって,論理型オぺランドに適用するとき,!= は ^ (15.21.2) と同じように振る舞う。
== 及び !=一方のオぺランドの型を他方のオぺランドの型にキャスト変換(5.4)によって変換不可能ならば,コンパイル時エラーが発生する。二つのオぺランドの実行時の値は,必然的に不等価となる。
実行時には,== の結果は,オぺランドの値が両方とも null 又は両方とも同じオブジェクト若しくは配列を参照していれば,true とする。 そうでないときには,結果はfalseとする。
!= の結果は,オぺランドの値が両方とも null 又は両方とも同じオブジェクト若しくは配列を参照していれば,false とする。そうでないときには,結果はtrueとする。
== は,型 String への参照の比較に使用できるが,そのような等価試験は,二つのオぺランドが同じオブジェクトStringを参照するかどうかを決定する。オぺランドが違うオブジェクトStringならば,それらが同じ文字の並びを含んでいても,結果はfalseとする。二つの文字列s 及び t における内容の等価性は,メソッド呼出しs.equals(t) (20.12.9)によって試験可能とする。3.10.5 及び20.12.47も参照すること。
&,XOR演算子
^ 及びOR演算子 |
を含む。これらの演算子は,異なった優先度をもつ。&
は最大優先度をもち,|
は最小優先度を持つ。これらの演算子は各々構文的に左結合とする(各々左から右へとグループ化する)。オペランド式がどんな副作用ももたなければ,各々の演算子は可換的とする。各々の演算子は結合的とする。
AndExpression:
EqualityExpression
AndExpression & EqualityExpression
ExclusiveOrExpression:
AndExpression
ExclusiveOrExpression ^ AndExpression
InclusiveOrExpression:
ExclusiveOrExpression
InclusiveOrExpression | ExclusiveOrExpression
ビット単位の論理演算子は,数値型の二つのオペランド又は型booleanの二つのオペランドを比較するのに使用してよい。他のすべての場合はコンパイル時エラーとする。&,^ 及び
|&,^又は|の両オペランドがプリミティブ整数型のとき,最初にオペランドに二進数値昇格
(5.6.2)を実行する。ビット単位の演算子式の型をオペランド昇格後の型とする。
&に関しては,結果値をオペランド値のビット単位のANDとする。
^に関しては,結果値をオペランド値のビット単位のXORとする。
|に関しては,結果値をオペランド値のビット単位のORとする。
例えば,式0xff00&0xf0f0の結果は
0xf000とする。
0xff00^0xf0f0の結果は0x0ff0とする。
0xff00|0xf0f0の結果は0xfff0とする。
&,^及び|&,^及び|の両方のオペランドが型booleanのとき,ビットの単位演算子式の型を型booleanとする。
&に関しては,両方のオペランド値がtrueならば,結果値をtrueとする。そうでないときは,結果値をfalseとする。
^に関しては,オペランド値が異なっているならば,結果値をtrueとする。そうでないときは,結果値をfalseとする。
|に関しては,両方のオペランド値がfalseならば,結果値をfalseとする。そうでないときは,結果値をtrueとする。
&&&&は演算子&
(15.21.2)と類似するが,その左辺オペランド値がtrueの場合だけその右辺オペランドを評価する。構文的には左結合とする(左から右へとグループ化する)。副作用及び結果値の両方に関して,完全に結合的とする。つまり,任意の式a,b及びcに対して,式((a)&&(b))&&(c)の評価は,同じ副作用が同じ順序で発生し,(a)&&((b)&&(c))と同じ結果を生じる。
ConditionalAndExpression:
InclusiveOrExpression
ConditionalAndExpression && InclusiveOrExpression
&&の各オペランドは,型booleanでなければならない。そうでないときは,コンパイル時エラーが発生する。条件AND式の型は常にbooleanとする。
実行時には,左辺オペランド式を最初に評価する。その値がfalseならば,条件AND式の値は,
falseとし,右辺オペランド式は評価しない。左辺オペランドの値が
trueならば,右辺オペランド式を評価し,その値を条件AND式の値とする。この方法で,&&は,booleanオペランドに対して&と同じ結果を計算する。右辺オペランド式を常にではなく条件的に評価するという点だけが異なる。
||||は|(15.21.2)と類似するが,その左辺オペランドの値がfalseの場合にだけ,その右辺オペランドを評価する。構文的には左結合とする(左から右へとグループ化する)。副作用及び結果値の両方に関して,完全に結合的とする。つまり,任意の式a,b及びcに対して,((a)||(b))||(c)の評価は,同じ副作用が同じ順序で発生し,(a)||((b)||(c))と同じ結果を生じる。
ConditionalOrExpression:
ConditionalAndExpression
ConditionalOrExpression || ConditionalAndExpression
||の各オペランドは,型booleanでなければならない。そうでないときには,コンパイル時エラーが発生する。条件OR式の型は,常にbooleanとする。
実行時には,左辺オペランド式を最初に評価する。その値がtrueならば,条件ORの値をtrueとし,右辺オペランド式は評価しない。左辺オペランドの値がfalseならば,右辺オペランド式を評価し,その値を条件OR式の値とする。この方法で,||はbooleanオペランド上で|と同じ結果を計算する。右辺オペランド式を常にではなくむしろ条件的に評価するという点だけが異なるものとする。
? :? :は,二つの式のどちらを評価するべきかを決めるために,一つの式の論理値を使用する。
条件演算子は構文的には右結合とする(右から左へとグループ化する)。そこで,a
? b : c ? d : e ? f : gはa ? b : (c ? d : (e ? f : g))
と同じことを意味する。
ConditionalExpression:
ConditionalOrExpression
ConditionalOrExpression ? Expression : ConditionalExpression
条件演算子は,三つのオペランド式をもつ。1番目の式と2番目の式との間に?が現れ,2番目の式と3番目のと式の間に:が現れる。
最初の式は型booleanでなければならない。そうでないときは,コンパイル時エラーが発生する。
条件演算子は,数値型の2番目及び3番目のオペランドの選択,型booleanの2番目及び3番目のオペランドの選択,並びに,各々が参照型か空型のいずれかである2番目及び3番目のオペランドの選択,に使用可能とする。他の全ての場合にはコンパイル時エラーとする。
2番目又は3番目のオペランド式がvoidメソッドの起動の場合は許されないことに注意すること。実際,条件式はvoidメソッドの起動が現れるいかなる文脈にも出現することは許されない(14.7)。
byte及び他方が型shortならば,条件式の型はshortとする。
byte,short又はchar,及び他方のオペランドがその値が型Tで表現可能な型intの定数式ならば,T,条件式の型はTとする。
boolean値を2番目又は3番目のオペランド式のどちらを選択するかに使用する。
選択されたオペランド式を評価し,その結果値が上述した規則によって決定される条件式の型に変換される。選択されないオペランド式は,条件式のこの特定の評価のためには評価しない。
a=b=cはa=(b=c)を意味する。つまり,cの値をbに割り当て,次にbの値をaに割り当てる。
AssignmentExpression:
ConditionalExpression
Assignment
Assignment:
LeftHandSide AssignmentOperator AssignmentExpression
LeftHandSide:
ExpressionName
FieldAccess
ArrayAccess
AssignmentOperator: one of
= *= /= %= += -= <<= >>= >>>= &= ^= |=
代入演算子の最初のオペランドの結果は変数でなければならない。そうでないときには,コンパイル時エラーが発生する。このオペランドは,現在のオブジェクト又はクラスの局所変数又はフィールドの名前付けされた変数であってもよく,フィールドアクセス
(15.10)又は配列アクセス
(15.12)から生じ得るような計算された変数であってもよい。代入式の型はその変数の型とする。
実行時には,代入式の結果は代入が起こった後の変数の値とする。代入式の結果そのものは,変数ではない。
finalと宣言された変数は,その変数へのアクセスを式として使用するときは,結果が値となり,変数とはならないために,代入することが許されない。そこで代入演算子のオペランドとして使用することはできない。
=実行時には,式は次に述べる二つの方法の内の一つの方法で評価する。左辺オペランド式が配列アクセス式でないならば,次の三段階を要求する。
nullならば,いかなる代入も起こらず,NullPointerExceptionが投げられる。
IndexOutOfBoundsExceptionが投げられる。
finalであるかもしれない)。しかし,コンパイラが,コンパイル時に配列の構成要素が型TCになると証明することができないならば,確かにクラスRCが配列の構成要素の実際の型SCと代入互換
(5.2)であるという検査を,実行時に行わなければならない。この検査は,ナローイングキャスト(5.4,
15.15)と類似しているが,検査が失敗すれば
ClassCastExceptionよりもむしろArrayStoreExceptionが投げられる。そこで,
class ArrayReferenceThrow extends RuntimeException { }
class IndexThrow extends RuntimeException { }
class RightHandSideThrow extends RuntimeException { }
class IllustrateSimpleArrayAssignment {
static Object[] objects = { new Object(), new Object() };
static Thread[] threads = { new Thread(), new Thread() };
static Object[] arrayThrow() {
throw new ArrayReferenceThrow();
}
static int indexThrow() { throw new IndexThrow(); {
static Thread rightThrow() {
throw new RightHandSideThrow();
}
static String name(Object q) {
String sq = q.getClass().getName();
int k = sq.lastIndexOf('.');
return (k < 0) ? sq : sq.substring(k+1);
}
static void testFour(Object[] x, int j, Object y) {
String sx = x == null ? "null" : name(x[0]) + "s";
String sy = name(y);
System.out.println();
try {
System.out.print(sx + "[throw]=throw => ");
x[indexThrow()] = rightThrow();
System.out.println("Okay!");
} catch (Throwable e) { System.out.println(name(e)); }
try {
System.out.print(sx + "[throw]=" + sy + " => ");
x[indexThrow()] = y;
System.out.println("Okay!");
} catch (Throwable e) { System.out.println(name(e)); }
try {
System.out.print(sx + "[" + j + "]=throw => ");
x[j] = rightThrow();
System.out.println("Okay!");
} catch (Throwable e) { System.out.println(name(e)); }
try {
System.out.print(sx + "[" + j + "]=" + sy + " => ");
x[j] = y;
System.out.println("Okay!");
} catch (Throwable e) { System.out.println(name(e)); }
}
public static void main(String[] args) {
try {
System.out.print("throw[throw]=throw => ");
arrayThrow()[indexThrow()] = rightThrow();
System.out.println("Okay!");
} catch (Throwable e) { System.out.println(name(e)); }
try {
System.out.print("throw[throw]=Thread => ");
arrayThrow()[indexThrow()] = new Thread();
System.out.println("Okay!");
} catch (Throwable e) { System.out.println(name(e)); }
try {
System.out.print("throw[1]=throw => ");
arrayThrow()[1] = rightThrow();
System.out.println("Okay!");
} catch (Throwable e) { System.out.println(name(e)); }
try {
System.out.print("throw[1]=Thread => ");
arrayThrow()[1] = new Thread();
System.out.println("Okay!");
} catch (Throwable e) { System.out.println(name(e)); }
testFour(null, 1, new StringBuffer());
testFour(null, 1, new StringBuffer());
testFour(null, 9, new Thread());
testFour(null, 9, new Thread());
testFour(objects, 1, new StringBuffer());
testFour(objects, 1, new Thread());
testFour(objects, 9, new StringBuffer());
testFour(objects, 9, new Thread());
testFour(threads, 1, new StringBuffer());
testFour(threads, 1, new Thread());
testFour(threads, 9, new StringBuffer());
testFour(threads, 9, new Thread());
}
}
このプログラムは,次のとおりに出力する。
throw[throw]=throw => ArrayReferenceThrow throw[throw]=Thread => ArrayReferenceThrow throw[1]=throw => ArrayReferenceThrow throw[1]=Thread => ArrayReferenceThrow最も興味深い場合は,最後から13番目である。
null[throw]=throw => IndexThrow null[throw]=StringBuffer => IndexThrow null[1]=throw => RightHandSideThrow null[1]=StringBuffer => NullPointerException
null[throw]=throw => IndexThrow null[throw]=StringBuffer => IndexThrow null[1]=throw => RightHandSideThrow null[1]=StringBuffer => NullPointerException
null[throw]=throw => IndexThrow null[throw]=Thread => IndexThrow null[9]=throw => RightHandSideThrow null[9]=Thread => NullPointerException
null[throw]=throw => IndexThrow null[throw]=Thread => IndexThrow null[9]=throw => RightHandSideThrow null[9]=Thread => NullPointerException
Objects[throw]=throw => IndexThrow Objects[throw]=StringBuffer => IndexThrow Objects[1]=throw => RightHandSideThrow Objects[1]=StringBuffer => Okay!
Objects[throw]=throw => IndexThrow Objects[throw]=Thread => IndexThrow Objects[1]=throw => RightHandSideThrow Objects[1]=Thread => Okay!
Objects[throw]=throw => IndexThrow Objects[throw]=StringBuffer => IndexThrow Objects[9]=throw => RightHandSideThrow Objects[9]=StringBuffer => IndexOutOfBoundsException
Objects[throw]=throw => IndexThrow Objects[throw]=Thread => IndexThrow Objects[9]=throw => RightHandSideThrow Objects[9]=Thread => IndexOutOfBoundsException
Threads[throw]=throw => IndexThrow Threads[throw]=StringBuffer => IndexThrow Threads[1]=throw => RightHandSideThrow Threads[1]=StringBuffer => ArrayStoreException
Threads[throw]=throw => IndexThrow Threads[throw]=Thread => IndexThrow Threads[1]=throw => RightHandSideThrow Threads[1]=Thread => Okay!
Threads[throw]=throw => IndexThrow Threads[throw]=StringBuffer => IndexThrow Threads[9]=throw => RightHandSideThrow Threads[9]=StringBuffer => IndexOutOfBoundsException
Threads[throw]=throw => IndexThrow Threads[throw]=Thread => IndexThrow Threads[9]=throw => RightHandSideThrow Threads[9]=Thread => IndexOutOfBoundsException
Threads[1]=StringBuffer => ArrayStoreExceptionこれは,
StringBufferへの参照を構成要素が型Threadである配列に格納するためにArrayStoreExceptionを投げたことを示している。コードは,コンパイル時には正しい型を示している。代入は,型Object[]の左辺及び型Objectの右辺となっている。実行時には,メソッドtestFourへの最初の実引数が,Thread配列のインスタンスへの参照となり,3番目の実引数は,クラスStringBufferのインスタンスへの参照となる。
+=以外は,両方のオペランドにプリミティブ型を要求する。+=に対しては,左辺オペランドが型Stringであれば,右辺オペランドはいかなる型でも可能とする。
形式E1op=E2の複合代入式は,E1=(T)((E1)op(E2))に等価とする。ここで,TはE1の型とする。ただし,もとの式はE1を一度だけ評価する点が違っている。型Tへのキャストは,等値変換
(5.1.1)又はナローイングプリミティブ変換
(5.1.3)のいずれかかもしれないことに注意すること。例えば,次のコードは正しい。
short x = 3; x += 4.6;結果として,
xは7をもつ。つまり前述の例と次の例とは同等とする。
short x = 3; x = (short)(x + 4.6);実行時に,式を次で述べる二つの方法の内の一つの方法で評価する。左辺オペランド式が配列アクセス式でなければ,四段階を要求する。
nullならば,いかなる代入も起こらず,aNullPointerExceptionが投げられる。
IndexOutOfBoundsExceptionが投げられる。
Stringでなければならない。クラスStringはfinal宣言されたクラスなので,SもまたStringでなければならない。したがって,単純代入演算子では必要となることがある実行時検査は,複合代入演算子に対しては決して必要とされない。
このプログラムは,次のとおりに出力する。
class ArrayReferenceThrow extends RuntimeException { } class IndexThrow extends RuntimeException { } class RightHandSideThrow extends RuntimeException { }
class IllustrateCompoundArrayAssignment { static String[] strings = { "Simon", "Garfunkel" }; static double[] doubles = { Math.E, Math.PI }; static String[] stringsThrow() { throw new ArrayReferenceThrow(); }
static double[] doublesThrow() { throw new ArrayReferenceThrow(); }
static int indexThrow() { throw new IndexThrow(); }
static String stringThrow() { throw new RightHandSideThrow(); }
static double doubleThrow() { throw new RightHandSideThrow(); }
static String name(Object q) { String sq = q.getClass().getName(); int k = sq.lastIndexOf('.'); return (k < 0) ? sq : sq.substring(k+1); }
static void testEight(String[] x, double[] z, int j) { String sx = (x == null) ? "null" : "Strings"; String sz = (z == null) ? "null" : "doubles"; System.out.println(); try { System.out.print(sx + "[throw]+=throw => "); x[indexThrow()] += stringThrow(); System.out.println("Okay!"); } catch (Throwable e) { System.out.println(name(e)); } try { System.out.print(sz + "[throw]+=throw => "); z[indexThrow()] += doubleThrow(); System.out.println("Okay!"); } catch (Throwable e) { System.out.println(name(e)); } try { System.out.print(sx + "[throw]+=\"heh\" => "); x[indexThrow()] += "heh"; System.out.println("Okay!"); } catch (Throwable e) { System.out.println(name(e)); } try { System.out.print(sz + "[throw]+=12345 => "); z[indexThrow()] += 12345; System.out.println("Okay!"); } catch (Throwable e) { System.out.println(name(e)); } try { System.out.print(sx + "[" + j + "]+=throw => "); x[j] += stringThrow(); System.out.println("Okay!"); } catch (Throwable e) { System.out.println(name(e)); } try { System.out.print(sz + "[" + j + "]+=throw => "); z[j] += doubleThrow(); System.out.println("Okay!"); } catch (Throwable e) { System.out.println(name(e)); } try { System.out.print(sx + "[" + j + "]+=\"heh\" => "); x[j] += "heh"; System.out.println("Okay!"); } catch (Throwable e) { System.out.println(name(e)); } try { System.out.print(sz + "[" + j + "]+=12345 => "); z[j] += 12345; System.out.println("Okay!"); } catch (Throwable e) { System.out.println(name(e)); } }
public static void main(String[] args) { try { System.out.print("throw[throw]+=throw => "); stringsThrow()[indexThrow()] += stringThrow(); System.out.println("Okay!"); } catch (Throwable e) { System.out.println(name(e)); } try { System.out.print("throw[throw]+=throw => "); doublesThrow()[indexThrow()] += doubleThrow(); System.out.println("Okay!"); } catch (Throwable e) { System.out.println(name(e)); } try { System.out.print("throw[throw]+=\"heh\" => "); stringsThrow()[indexThrow()] += "heh"; System.out.println("Okay!"); } catch (Throwable e) { System.out.println(name(e)); } try { System.out.print("throw[throw]+=12345 => "); doublesThrow()[indexThrow()] += 12345; System.out.println("Okay!"); } catch (Throwable e) { System.out.println(name(e)); } try { System.out.print("throw[1]+=throw => "); stringsThrow()[1] += stringThrow(); System.out.println("Okay!"); } catch (Throwable e) { System.out.println(name(e)); } try { System.out.print("throw[1]+=throw => "); doublesThrow()[1] += doubleThrow(); System.out.println("Okay!"); } catch (Throwable e) { System.out.println(name(e)); } try { System.out.print("throw[1]+=\"heh\" => "); stringsThrow()[1] += "heh"; System.out.println("Okay!"); } catch (Throwable e) { System.out.println(name(e)); } try { System.out.print("throw[1]+=12345 => "); doublesThrow()[1] += 12345; System.out.println("Okay!"); } catch (Throwable e) { System.out.println(name(e)); } testEight(null, null, 1); testEight(null, null, 9); testEight(strings, doubles, 1); testEight(strings, doubles, 9); }
}
throw[throw]+=throw => ArrayReferenceThrow throw[throw]+=throw => ArrayReferenceThrow throw[throw]+="heh" => ArrayReferenceThrow throw[throw]+=12345 => ArrayReferenceThrow throw[1]+=throw => ArrayReferenceThrow throw[1]+=throw => ArrayReferenceThrow throw[1]+="heh" => ArrayReferenceThrow throw[1]+=12345 => ArrayReferenceThrow最も興味深い場合は,最後から11番目及び12番目である。
null[throw]+=throw => IndexThrow null[throw]+=throw => IndexThrow null[throw]+="heh" => IndexThrow null[throw]+=12345 => IndexThrow null[1]+=throw => NullPointerException null[1]+=throw => NullPointerException null[1]+="heh" => NullPointerException null[1]+=12345 => NullPointerException
null[throw]+=throw => IndexThrow null[throw]+=throw => IndexThrow null[throw]+="heh" => IndexThrow null[throw]+=12345 => IndexThrow null[9]+=throw => NullPointerException null[9]+=throw => NullPointerException null[9]+="heh" => NullPointerException null[9]+=12345 => NullPointerException
Strings[throw]+=throw => IndexThrow doubles[throw]+=throw => IndexThrow Strings[throw]+="heh" => IndexThrow doubles[throw]+=12345 => IndexThrow Strings[1]+=throw => RightHandSideThrow doubles[1]+=throw => RightHandSideThrow Strings[1]+="heh" => Okay! doubles[1]+=12345 => Okay!
Strings[throw]+=throw => IndexThrow doubles[throw]+=throw => IndexThrow Strings[throw]+="heh" => IndexThrow doubles[throw]+=12345 => IndexThrow Strings[9]+=throw => IndexOutOfBoundsException doubles[9]+=throw => IndexOutOfBoundsException Strings[9]+="heh" => IndexOutOfBoundsException doubles[9]+=12345 => IndexOutOfBoundsException
Strings[1]+=throw => RightHandSideThrow doubles[1]+=throw => RightHandSideThrowこれらは,例外を投げることができる右辺が実際に例外を投げた場合で,しかもその唯一の場合である。これは,本当に,空配列参照値及び領域外インデクス値の検査後に,右辺オペランドの評価が起こることを示している。
次のプログラムは,右辺を評価する前に複合代入の左辺の値を保存するいう事実を例示する。
class Test {
public static void main(String[] args) {
int k = 1;
int[] a = { 1 };
k += (k = 4) * (k + 2);
a[0] += (a[0] = 4) * (a[0] + 2);
System.out.println("k==" + k + " and a[0]==" + a[0]);
}
}
このプログラムは,次のとおりに出力する。
k==25 and a[0]==25右辺オペランド
(k=4)*(k+2)を評価する前に,kの値1を複合代入演算子+=により保存する。右辺オペランドの評価は,4をkに割り当て,k+2を値6と計算し,4に6をかけて24を得る。これに保存した値1を加え,25を得る。さらにこの値を演算子+=によってkに格納する。この分析が,a[0]を使用する場合に適用される。結局,文
k += (k = 4) * (k + 2); a[0] += (a[0] = 4) * (a[0] + 2);は,次の文と同じ振舞いをすることになる。
k = k + (k = 4) * (k + 2); a[0] = a[0] + (a[0] = 4) * (a[0] + 2);
Expression:
AssignmentExpression
C及びC++と異なり,Java言語には,コンマ演算子は存在しない。
ConstantExpression:
Expression
コンパイル時の定数式(constant expression)は,プリミティブ型又は次のものだけを使用して構成されるStringを表示する式とする。
Stringのリテラル
Stringへのキャスト
+, -,
~及び!(ただし,++又は--は含まない)
*, /及び%
+及び-
<<,
>>及び>>>
<, <=,
>及び>=(ただし,instanceofは含まない)
==及び!=
&, ^及び|
&&及び条件OR演算子||
? :
final変数を参照する単純名
final変数を参照する形式TypeName.Identifierなる限定名
switch文
(14.9)内のcase内で使用し,代入変換
(5.2)に対して特別な意味をもつ。
true (short)(1*2*3*4*5*6) Integer.MAX_VALUE / 2 2.0 * Math.PI "The integer " + Long.MAX_VALUE + " is mighty big."