目次 | 前 | 次
3. 字句構造
3.では,Javaの字句構造を規定する。
Javaプログラムは,Unicode (3.1) で記述するが,字句変換(3.2)を提供することで,ASCII文字だけを用いて任意のUnicode文字を含めるようにし,Unicodeエスケープ(3.3) を使用可能とする。行終端子(3.4)は,一貫性のある行番号を維持するとともに,既存のホストシステムでの異なった慣例を使用できる定義とする。
字句変換によって生じるUnicode文字は,空白類(3.6),注釈(3.7)及びトークンからなる入力要素(3.5)の列に還元される。トークンは,Javaの構文文法の,識別子(3.8),キーワード(3.9),リテラル(3.10),分離子(3.11)及び演算子(3.12)とする。
3.1 Unicode
Javaプログラムは, Unicode文字集合第2版を用いて記述する。Unicodeについての情報は,次のURLで入手可能である。
http://www.unicode.org 及び ftp://unicode.org
第1.1版以前のJavaは,Unicode第1.1.5版を使用した(The Unicode Standard: Worldwide Character Encoding(1.2)及びその改訂版を参照すること)。Unicodeの第1.1.5版及び第2版の違いは,20.5を参照すること。
注釈(3.7),識別子,並びにリテラル文字及びリテラル文字列(3.10.4,3.10.5)の内容以外のJavaプログラムの入力要素(3.5)は,ASCII文字(又はASCII文字を生じるUnicodeエスケープ(3.3))だけから形成される。ASCII (ANSI X3.4)は,American Standard Code for Information Interchangeのこととする。Unicode文字符号化の最初の128文字は, ASCII文字とする。
3.2 字句変換
未変換のUnicode文字ストリームは,次の3段階の字句変換を順次実行して,Javaトークンの列に変換する。
- Unicode文字列の未変換ストリーム内におけるUnicodeエスケープ(3.3)を, 対応するUnicode文字に変換する。
\uxxxxという形式のUnicodeエスケープは,その符号化をxxxxとするUnicode文字を表現する。ここで,xxxxは16進数値とする。字句変換のこの段階によって,任意のJavaプログラムは, ASCII文字だけを使って表現可能となる。
- 第1段階で得られたUnicodeストリームを, 入力文字及び行終端子のストリームに変換する(3.4)。
- 第2段階で得られた入力文字及び行終端子のストリームを,Javaの入力要素の列に変換する(3.5)。この入力要素の列は,空白類(3.6) 及び注釈 (3.7) が取り除かれた後,Javaの構文文法(2.3)で終端記号とするトークン(3.5)から構成される。
Javaは,他の字句変換を行えば文法的に正しいJavaプログラムが生成される場合でも,各段階で(トークンの)最長可能変換を常に使用する。例えば,入力文字a--bは,a,-,-,bとトークン切出し(3.5)すれば,文法的に正しいJavaプログラムの一部となるが,文法的に正しくないa,--,bにトークン化される。
3.3 Unicodeエスケープ
Javaの実装は,最初に,入力内の Unicodeエスケープ(Unicode escapes) を認識し,ASCII文字 \u 及びそれに続く4個の16進数字をその16進数値が示すUnicode文字に変換し,他のすべての文字はそのままとする。変換のこの段階が,Unicode入力文字列を生成する。
UnicodeInputCharacter:
UnicodeEscape
RawInputCharacter
UnicodeEscape:
\ UnicodeMarker HexDigit HexDigit HexDigit HexDigit
UnicodeMarker:
u
UnicodeMarker u
RawInputCharacter:
any Unicode character
HexDigit: one of
0 1 2 3 4 5 6 7 8 9 a b c d e f A B C D E F
ここで,\,u 及び16進数字は, すべてASCII文字とする。
文法によって示される処理に加えて,未変換の入力文字である逆スラッシュ \ に対して,入力処理では,その \ の前に \ がいくつ連続しているかを考慮しなければならない。連続する \ 文字を,\ ではない文字又は入力ストリームの開始からの分離は,次による。つまり,\ の前の \ の数が偶数ならば,Unicodeエスケープの開始を示し,その数が奇数ならばUnicodeエスケープの開始とは見なさない。例えば,未変換の入力 "\\u2297=\u2297"は,"\\u2297=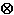 "
"という11文字を生じる(\u2297は, Unicode文字“”の符号化表現である)。
エスケープ開始を表わす \ に続いて u が現われなければ,それは RawInputCharacter として扱われ,エスケープされたUnicodeストリームの一部として残る。二つ以上の u が続き,最後の u の直後に4個の16進数字が続かなければ,コンパイル時エラーが発生する。
Unicodeエスケープによって生成された文字が,さらに別のUnicodeエスケープに使われることはない。例えば,未変換入力 \u005cu005a は,005c が \ に対するUnicode値のため,\ u 0 0 5 a という6文字に変換される。これは, 005a で表わされるUnicode文字 Z にはならない。それは,\u005c から生じた \ が,さらに別のUnicodeエスケープの開始とは解釈されないことに基づく。
Javaは,UnicodeのJavaプログラムをASCIIに変換する標準的な方法を提供する。これによって, JavaプログラムをASCIIベースのツールで処理可能な形式に変換する。この変換は,余分な u を一つ追加することによって,プログラムのソーステキスト内のUnicodeエスケープをASCIIにする。例えば,\uxxxx は \uuxxxx とする。同時に,ソーステキスト内の非ASCII文字を,一つの u を含む \uxxxx エスケープに変換する。この方法で変換されたものは, Javaコンパイラで同様に受理可能で,全く同一のプログラムを表現する。複数の u が存在する各エスケープシーケンスを,u が一つ少ないUnicode文字の列に変換することによって, このASCII形式のソースから全く同一のUnicodeソースを後に復元可能とする。その際,同時に,u が一つのエスケープシーケンスは,対応する一つのUnicode文字に変換する w) #
Javaシステムは,Unicode文字を表示するために,適当なフォントが利用できないときには,出力形式として,\uxxxx という記法をそのまま使用することが望ましい。
3.4 行終端子
Javaの実装は,次に,Unicode入力文字列を 行終端子(line terminators) を認識することによって行に分割する。行のこの定義によって,Javaコンパイラ又は他のJavaシステム構成要素の生成する行番号が決定される。注釈の // 形式の終端も, 行終端子が指定する (3.7) 。
LineTerminator:
the ASCII LF character, also known as "newline"
the ASCII CR character, also known as "return"
the ASCII CR character followed by the ASCII LF character
InputCharacter:
UnicodeInputCharacter but not CR or LF
行は,ASCII文字の CR,LF,又はCR LFによって終端する。2文字の CR及びその直後に続く LFは,2文字であるが,一つの行終端子として数える。その結果得られるのは,行終端子及び入力文字の列であって,トークン切出し過程における第3段階のための終端記号とする。
3.5 入力要素及びトークン
エスケープ処理(3.3)及び入力行認識(3.4)から生じる入力文字及び行終端子は,入力要素(input elements) の列に還元される。空白類(3.6)でも注釈(3.7)でもないこれら入力要素は,トークン(token) とする。トークンは, Javaの構文文法(2.3)における終端記号とする。
この過程は,次の生成規則によって規定する。
Input:
InputElementsopt Subopt
InputElements:
InputElement
InputElements InputElement
InputElement:
WhiteSpace
Comment
Token
Token:
Identifier
Keyword
Literal
Separator
Operator
Sub:
the ASCII SUB character, also known as "control-Z"
空白類(3.6)及び注釈(3.7)は,隣接していれば他の方法でトークン化されるかもしれないトークンを区切るのに使用可能とする。例えば,入力内のASCII文字 - 及び = は,空白類も注釈も介入しない場合だけ,演算子トークン -= (3.12)を形成可能とする。
あるオペレーティングシステムとの互換性を考慮して,ASCII文字SUB(\u001a又はcontrol-Z)は,エスケープされた入力ストリーム内の最終文字ならば,無視される。
得られる入力ストリーム内の二つのトークン x及び y を考える。x が y に先行すれば,x は y の左に存在する,及び y は x の右に存在する,という。
class Empty {
}
この例では,} トークンは,この二次元的な表現では,{ の下及び左に出現するが,{ の右に存在するという。右及び左についてのこの規定は,例えば,二項演算子の右オペランド又は代入式の左辺という言い方を可能にする。
3.6 空白類
空白類(white space) は,行終端子 (3.4)だけではなく,ASCIIのスペース,水平タブ及びフォームフィード文字も含むと定義する。
WhiteSpace:
the ASCII SP character, also known as "space"
the ASCII HT character, also known as "horizontal tab"
the ASCII FF character, also known as "form feed"
LineTerminator
3.7 注釈
Javaは,3種類の 注釈(comments) を定義する。
/* text */ 従来の注釈(traditional comment): ASCII文字 /* からASCII文字 */ までのすべてのテキストを無視する(C及びC++と同じ)。
// text 一行注釈(single-line comment): ASCII文字 // から行末までのすべてのテキストを無視する(C++と同じ)。
/** documentation */
文書化注釈(documentation comment): ASCII文字 /** 及び */ に囲まれたテキストは,他のツールによって処理可能とし,後続のクラス,インタフェース,コンストラクタ又はメンバ(メソッド又はフィールド)の宣言についての自動生成文書を準備する。提供された 文書(docummentation) がどのように処理されるかの完全な記述については18.を参照すること。
これらの三つの注釈は,次の生成規則によって形式的に規定される。
Comment:
TraditionalComment
EndOfLineComment
DocumentationComment
TraditionalComment:
/ * NotStar CommentTail
EndOfLineComment:
/ / CharactersInLineopt LineTerminator
DocumentationComment:
/ * * CommentTailStar
CommentTail:
* CommentTailStar
NotStar CommentTail
CommentTailStar:
/
* CommentTailStar
NotStarNotSlash CommentTail
NotStar:
InputCharacter but not*
LineTerminator
NotStarNotSlash:
InputCharacter but not * or /
LineTerminator
CharactersInLine:
InputCharacter
CharactersInLine InputCharacter>
これらの生成規則は,次の特性のすべてを示す。
- 注釈は, 入れ子にならない。
/*及び */ は,// で始まる注釈内では特別の意味をもたない。// は,/* 又は /** で始まる注釈内では特別の意味をもたない。
結果として,次のテキストは,単一の完結した注釈となる。
/* this comment /* // /** ends here: */
字句文法は,注釈が,文字リテラル(3.10.4)又は文字列リテラル(3.10.5)内で出現しないことを示す。
/**/ は文書化注釈と見すが,/* */ (アスタリスクの間にスペースが入る)は従来の注釈と見なす。
3.8 識別子
識別子(identifier) は,Java文字(Java letters) 及び Java数字(Java digits) の長さ制限のない列であって,先頭の文字はJava文字でなければならない。識別子は,キーワード(3.9),論理型リテラル(3.10.3)又は空リテラル(3.10.7)と同じ文字の並び(Unicode文字列)にすることはできない。
Identifier:
IdentifierChars but not a Keyword or BooleanLiteral or NullLiteral
IdentifierChars:
JavaLetter
IdentifierChars JavaLetterOrDigit
JavaLetter:
any Unicode character that is a Java letter (see below)
JavaLetterOrDigit:
any Unicode character that is a Java letter-or-digit (see below)
文字及び数字は,Unicode文字集合のどの文字であってもよい。Unicode文字集合は,中国語,日本語及び朝鮮語(チョソノ)に対する大きな集合を含み,今日世界で使用しているほとんどの筆記スクリプトを扱っている。これによって,Javaプログラマは,プログラム中に,自分の母国語で書いた識別子を使うことができる。
Java文字は, メソッドACharacter.isJavaLetter(20.5.17)が true を返す文字とする。Java文字又は数字は,メソッドACharacter.isJavaLetterOrDigit(20.5.18)が true を返す文字とする。
Java文字は,ASCIIラテン文字の大文字A から Z まで(\u0041-\u005a)及び小文字 a から z まで(\u0061-\u007a),並びに歴史的な事情によって,ASCIIの下線(_,又は\u005f)及びドル記号($,又は\u0024)を含む。$ 記号は,機械的に生成されたJavaコードでだけで使用されるか,又はまれにだが,過去の遺産としてのシステムにおける既存の名前にアクセスする場合に使用される。
Java数字は,ASCII数字の 0-9(\u0030-\u0039)を含む。
二つの識別子が同一,つまり各々の文字又は数字に対して同一のUnicode文字をもつ場合に限り,二つの識別子は同じとする。
外見的には同じに見える識別子でも,異なっているかもしれない。例えば,LATIN CAPITAL LETTER A (A,\u0041),LATIN SMALL LETTER A (a,\u0061),GREEK CAPITAL LETTER ALPHA (A,\u0391)及びCYRILLIC SMALL LETTER A (a,\u0430)の1文字だけで構成される識別子は,それぞれ別の識別子とする。
Unicodeの複合文字は,それらを分解した文字とは異なる。例えば,LATIN CAPITAL LETTER A ACUTE (Á, \u0301)は,ソートの際には,NON-SPACING ACUTE (´, \u0301)を直後に伴った LATIN CAPITAL LETTER A (A,\u0041) と同じ文字と見なされるが,Java識別子では異なるとする。複合文字の分解についての詳細は,The Unicode Standard の第1巻の412ページ以降を,ソートについての詳細は同じ著書の626-627ページを参照すること。
識別子の例を次に挙げる。
String i3 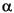
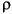
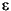
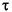
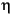 MAX_VALUE isLetterOrDigit
MAX_VALUE isLetterOrDigit
3.9 キーワード
ASCII文字列から形成される次の文字列は,キーワード(keywords) として予約されており,識別子(3.8)として使用不可能とする。
Keyword: one of
abstract default if private throw
boolean do implements protected throws
break double import public transient
byte else instanceof return try
case extends int short void
catch final interface static volatile
char finally long super while
class float native switch
const for new synchronized
continue goto package this
キーワード const 及び goto は, 現在Javaでは使用されていないが,予約語とする。これによって,これらのC++キーワードがJavaプログラム内で誤って使用されたならば,Javaコンパイラは的確なエラーメッセージを表示できる。
true 及び false は, キーワードのように思えるが,技術的には論値型リテラル (3.10.3) とする。同様に,null もキーワードのように思えるが,技術的には空リテラル(3.10.7)とする。
3.10 リテラル
リテラル(literal) は,プリミティブ型(4.2),String型(4.3.3,20.12)又は空型(4.1)の値のソースコード表現とする。
Literal:
IntegerLiteral
FloatingPointLiteral
BooleanLiteral
CharacterLiteral
StringLiteral
NullLiteral
3.10.1 整数リテラル
整数型及び値の一般的な規定は,4.2.1を参照すること。
整数リテラル(integer literal) は,10進数(基数10),16進数(基数16),又は8進数(基数8)で表現可能とする。
IntegerLiteral:
DecimalIntegerLiteral
HexIntegerLiteral
OctalIntegerLiteral
DecimalIntegerLiteral:
DecimalNumeral IntegerTypeSuffixopt
IntegerTypeSuffix: one of
l L
整数リテラルは,接尾語がASCII文字の L 又は l(エル)ならば,型 long とする。それ以外は,型 int(4.2.1)とする。文字 l(エル)は, 数字の 1(イチ)と区別が難しいことが多いので,接尾語は,L が望ましい。
10進数は,整数 0 を表す一つのASCII文字 0,又は正の整数を表す 1 から 9 までの一つのASCII数字及びオプションとしてその後に続く 0 から 9 までの一つ以上のASCII数字の並びから構成される。
DecimalNumeral:
0
NonZeroDigit Digitsopt
Digits:
Digit
Digits Digit
Digit:
0
NonZeroDigit
NonZeroDigit: one of
1 2 3 4 5 6 7 8 9
16進数は,先頭のASCII文字 0x 又は 0X 及びその後に続く一つ以上のASCIIの16進数字とから構成され,正の整数,ゼロ又は負の整数を表現可能とする。値10から15までの16進数字は,ASCII文字の a から f まで又は A から F までを使って,それぞれ表現する。16進数字として使用される各文字は,大文字又は小文字であってよい。
HexNumeral:
0 x HexDigit
0 X HexDigit
HexNumeral HexDigit
3.3で示した次の生成規則を,明確化のためにここに再び示す。
HexDigit: one of
0 1 2 3 4 5 6 7 8 9 a b c d e f A B C D E F
8進数は,ASCII数字 0及びその後に続く一つ以上の 0 から 7 までのASCII数字から構成され,正の整数,ゼロ又は負の整数を表現可能とする。
OctalNumeral:
0 OctalDigit
OctalNumeral OctalDigit
OctalDigit: one of
0 1 2 3 4 5 6 7
8進数は常に二つ以上の数字から構成される。0は常に10進数と見なされるが,数値の 0, 00 及び 0x0 はどれも同じ整数値を表現するので,実際上は,問題にはならない。
型 int の最大の10進数リテラルは,2147483648(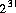 )とする。
)とする。0 から 2147483647 までのすべての10進数リテラルは,int リテラルが出現してよいところにはどこにでも出現してよい。しかし, リテラル 2147483648 だけは,単項マイナス演算子 - のオペランドとしてだけ出現可能とする。
型 int の最大の正の16進数リテラル及び8進数リテラルは,それぞれ,0x7fffffff 及び 017777777777 とする。これらは,10進数の 2147483647(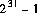 )に等しい。型
)に等しい。型 int の最小の負の16進数リテラル及び8進数リテラルは,それぞれ,0x80000000 及び 020000000000とする。これらは,10進数値の -2147483648(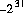 )を表現する。16進数リテラルの
)を表現する。16進数リテラルの 0xffffffff 及び8進数リテラルの 037777777777 は,それぞれ10進数値 -1 を表す。
Integer.MIN_VALUE(20.7.1)及び Integer.MAX_VALUE(20.7.2) も参照のこと。
型 int の10進数リテラルが,2147483648(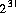 )よりも大きい場合,リテラル
)よりも大きい場合,リテラル 2147483648 が単項マイナス演算子 - のオペランドとして以外で出現する場合,又は16進数若しくは8進数の int リテラルが32ビットに収まらない場合には,コンパイル時エラーが発生する。
int のリテラルの例を次に示す。
0 2 0372 0xDadaCafe 1996 0x00FF00FF
型 long の最大の10進数リテラルは,9223372036854775808L (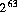 )とする。
)とする。0L から 9223372036854775807L までのすべての10進数リテラルは,long リテラルが出現可能な任意の場所で出現してよい。しかし,9223372036854775808L だけは,単項マイナス演算子 - のオペランドとしてだけ出現してよい。
型 long の最大の正の16進数リテラル及び8進数リテラルは,それぞれ,0x7fffffffffffffffL 及び 0777777777777777777777L とする。これらは,10進数の 9223372036854775807L(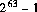 )と等しい。リテラル
)と等しい。リテラル 0x8000000000000000L 及び 01000000000000000000000Lは,それぞれ,最小の負の long の16進数リテラル及び8進数リテラルとする。これらは,10進数値 -9223372036854775808L(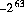 )をもつ。16進数リテラルの
)をもつ。16進数リテラルの 0xffffffffffffffffL及び8進数リテラルの 01777777777777777777777L は,それぞれ10進数値 -1L を表す。
Long.MIN_VALUE(20.8.1)及び Long.MAX_VALUE(20.8.2)も参照すること。
型 long の10進数リテラルが9223372036854775808L(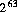 )よりも大きい場合,リテラル
)よりも大きい場合,リテラル 9223372036854775808L が単項マイナス演算子 - のオペランドとして以外の場所に現われる場合,又は型 long の16進数リテラル若しくは8進数リテラルが64ビットに収まらない場合には,コンパイル時エラーが発生する。
型 long のリテラルの例を次に示す。
0l 0777L 0x100000000L 2147483648L 0xC0B0L
3.10.2 浮動小数点リテラル
浮動小数点の型及び値の一般的規程は,4.2.3を参照のこと。
浮動小数点リテラル(floating-point literal) は,整数部,10進小数点(ASCIIのピリオド文字),小数部,指数部及び型接尾語の部分をもつ。指数部は,存在する場合には,ASCII文字 e 又は E 及びそれに続く符号付き又は符号なしの整数によって示す。
整数部又は小数部には少なくとも一つの数字を必要とし,小数点,指数部,float 型の接尾語のいずれかを必要とする。他のすべての部分は,オプションとする。
浮動小数点リテラルは,接尾語にASCII文字の F 又は f が使われている場合は, 型 float とする。そうでないときには,型 double とし,ASCII文字 D 又は d を接尾語として使ってもよいが,オプションとする。
FloatingPointLiteral:
Digits . Digitsopt ExponentPartopt FloatTypeSuffixopt
. Digits ExponentPartopt FloatTypeSuffixopt
Digits ExponentPart FloatTypeSuffixopt
Digits ExponentPartopt FloatTypeSuffix
ExponentPart:
ExponentIndicator SignedInteger
ExponentIndicator: one of
e E
SignedInteger:
Signopt Digits
Sign: one of
+ -
FloatTypeSuffix: one of
f F d D
Javaの型 float及び型 double は,それぞれ IEEE 754 の32ビット単精度及び64ビット倍精度の2進浮動小数点値とする。
浮動小数点数のUnicode文字列表現から,内部的な IEEE 754 の2進浮動小数点表現への適正な入力変換の詳細は,パッケージ java.lang のクラス Float(20.9.17)及びクラス Double(20.10.16)のメソッド valueOf で示す。
最大の正の有限の型 float リテラルは,3.40282347e+38f とする。最小の正の有限非ゼロの型 float リテラルは,1.40239846e-45fとする。最大の正の有限の型 double リテラルは,1.79769313486231570e+308 とする。最小の正の有限非ゼロの型 double リテラルは,4.94065645841246544e-324 とする。
Float.MIN_VALUE(20.9.1)及び Float.MAX_VALUE(20.9.2)を参照すること。Double.MIN_VALUE(20.10.1)及び Double.MAX_VALUE (20.10.2)も参照すること。
ゼロ以外の浮動小数点リテラルが大きすぎる場合は,内部表現への丸め変換時に IEEE 754 無限大となるので,コンパイル時エラーが発生する。Javaプログラムでは,1f/0f,-1d/0d などの定数表現を使うことによって,又はクラス Float(20.9)及びクラス Double(20.10)の定義済み定数 POSITIVE_INFINITY 及び NEGATIVE_INFINITY を使うことによって,コンパイル時エラーを生成せずに無限大を表現できる。
ゼロ以外の浮動小数点リテラルが小さすぎる場合は,内部表現への丸め変換時にゼロとなるので,コンパイル時エラーが発生する。ゼロ以外の浮動小数点リテラルが,内部表現への丸め変換時にゼロ以外の非正規化数となる場合は,コンパイル時エラーは発生しない。
非数値(Not-a-Number)を表現する定義済み定数は,クラス Float 及びクラス Double において,Float.NaN(20.9.5)及び Double.NaN(20.10.5)と定義する。
float リテラルの例を次に示す。
1e1f 2.f .3f 0f 3.14f 6.022137e+23f
double リテラルの例を次に示す。
1e1 2. .3 0.0 3.14 1e9d 1e137
浮動小数点リテラルを10進数以外で表す方法はない。しかし,クラス Float のメソッド intBitsToFloat(20.9.23)及びクラス Double のメソッド longBitsToDouble(20.10.22)は,16進数又は8進数整数リテラルで浮動小数点値を表す方法を提供する。例を次に示す。
Double.longBitsToDouble(0x400921FB54442D18L)
この値は,Math.PI(20.11.2)に等しい。
3.10.3 論理値リテラル
型 boolean は,ASCII文字から形成される true リテラル及び false リテラルによって表現される,二つの値をもつ。
論理リテラル(boolean literal) は,常に型 boolean とする。
BooleanLiteral: one of
true false
3.10.4 文字リテラル
文字リテラル(character literal) は,ASCIIの引用符で囲まれた文字又はエスケープシーケンスとして表現される(一重引用符又はアポストロフィ文字は,\u0027 である。)
文字リテラルは, 常に型 char とする。
CharacterLiteral:
' SingleCharacter '
' EscapeSequence '
SingleCharacter:
InputCharacter but not ' or \
エスケープシーケンスは,3.10.6で示す。
3.4で規定したとおりに,CR文字及び LF文字は,決して InputCharacter にならない。これらの文字は,LineTerminator を構成すると認識される。
SingleCharacter 又は EscapeSequence に続く文字が ' 以外の場合は,コンパイル時エラーとする。
開始引用符 ' の後及び終了引用符 ' の前に行終端子が出現する場合は, コンパイル時エラーとする。
次は,char リテラルの例とする。
'a'
'%'
'\t'
'\\'
'\''
'\u03a9'
'\uFFFF'
'\177'
'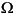 '
''
'
''
Unicodeエスケープは初期の段階で処理されるので,値を改行(LF)とする文字リテラルを '\u000a' と記述するのは正しくない。Unicodeエスケープ \u000a は,変換の第1段階(3.3)で実際の改行に変換され,その改行は,第2段階(3.4)で LineTerminator とする。そのため,第3段階で文字リテラルは有効ではない。代わりに,エスケープシーケンス '\n'(3.10.6)を使用する。同様に,値が復帰(CR)とする文字リテラルを '\u000d' と記述するのも正しくない。代わりに,'\r' を使用する。
C及びC++では,一つの文字リテラルが一つ以上の文字の表現を含んでよいが,それらの文字リテラルの値は, 処理系で定義する。Javaでは,文字リテラルは常にちょうど一つの文字を表現する。
3.10.5 文字列リテラル
文字列リテラル(string literal) は,二重引用符で囲まれたゼロ個以上の文字から構成される。各文字は,エスケープシーケンスによって表現してもよい。
文字列リテラルは, 常に型 Stringとする(4.3.3,20.12)。文字列リテラルは常にクラス String の同じインスタンス(4.3.1)を参照する。
StringLiteral:
" StringCharactersopt "
StringCharacters:
StringCharacter
StringCharacters StringCharacter
StringCharacter:
InputCharacter but not " or \
EscapeSequence
エスケープシーケンスは,3.10.6で示す。
3.4で規定したとおり,文字 CR及び LFのどちらも InputCharacter と見なされることはない。どちらも LineTerminator を構成するとして認識される。
行終端子が開始引用符 " の後,及び終了引用符 " の前に現われると,コンパイル時エラーになる。長い文字列リテラルは, 常に短い断片に分割でき,文字列連結演算子 +(15.17.1)を使用して(恐らくカッコで囲まれた)式として記述できる。
次に,文字列リテラルの例を示す。
"" // the empty string
"\"" // a string containing " alone
"This is a string" // a string containing 16 characters
"This is a " + // actually a string-valued constant expression,
"two-line string" // formed from two string literals
Unicodeエスケープは初期の段階で処理されるので,改行(LF)一つを含む文字列リテラルを "\u000a" と記述するのは正しくない。Unicodeエスケープの \u000a は,変換の第1段階(3.3) で実際の改行に変換され,改行は,第2段階(3.4)で LineTerminator となる。そのため,第3段階で文字列リテラルは有効ではない。代わりに,"\n"(3.10.6)を使用する。同様に,復帰(CR)一つを含む文字列リテラルを "\u000d" と記述するのも正しくない。代わりに,"\r" を使用する。
文字列リテラルは,クラス String(4.3.3,20.12)のインスタンス(4.3.1,12.5)への参照(4.3)とする。オブジェクト String は,一定の値をもつ。文字列リテラル,又はもっと一般的には,定数式の値とする文字列(15.27)は,メソッド String.intern(20.12.47)を使って,一意なインスタンスを共有するために収容される。
次に,二つのコンパイル単位(7.3)から成るテストプログラムを示す。
package testPackage;
class Test {
public static void main(String[] args) {
String hello = "Hello", lo = "lo";
System.out.print((hello == "Hello") + " ");
System.out.print((Other.hello == hello) + " ");
System.out.print((other.Other.hello == hello) + " ");
System.out.print((hello == ("Hel"+"lo")) + " ");
System.out.print((hello == ("Hel"+lo)) + " ");
System.out.println(hello == ("Hel"+lo).intern());
}
}
class Other { static String hello = "Hello"; }
package other;
public class Other { static String hello = "Hello"; }
これらは,次を出力する。
true true true true false true
この例は,次の六つの点を例示する。
- 同じパッケージ(7.)の同じクラス内(8.)のリテラル文字列は,同じオブジェクト
String(4.3.1)への参照を表現する。
- 同じパッケージの異なるクラス内のリテラル文字列は,同じオブジェクト
String への参照を表現する。
- 異なるパッケージの異なるクラス内のリテラル文字列は,同様に,同じオブジェクト
String への参照を表現する。
- 定数式(15.27)によって計算される文字列は,コンパイル時に計算され,それらがリテラルであるかのように扱われる。
- 実行時に計算される文字列は,新しく生成されるものであって,別の文字列とする。
- 計算された文字列を明示的に収容した結果は,同じ内容をもつ既存のリテラル文字列と同じ文字列とする。
3.10.6 文字及び文字列リテラルのためのエスケープシーケンス
文字及び文字列 エスケープシーケンス(escape sequences) によって,文字リテラル(3.10.4)又は文字列リテラル(3.10.5)内の一重引用符,二重引用符及び逆スラッシュの各文字と同様に,図形文字の表現を扱うことができる。
EscapeSequence:
\ b /* \u0008: backspace BS */
\ t /* \u0009: horizontal tab HT */
\ n /* \u000a: linefeed LF */
\ f /* \u000c: form feed FF */
\ r /* \u000d: carriage return CR */
\ " /* \u0022: double quote " */
\ ' /* \u0027: single quote ' */
\ \ /* \u005c: backslash \ */
OctalEscape /* \u0000 to \u00ff: from octal value */
OctalEscape:
\ OctalDigit
\ OctalDigit OctalDigit
\ ZeroToThree OctalDigit OctalDigit
OctalDigit: one of
0 1 2 3 4 5 6 7
ZeroToThree: one of
0 1 2 3
エスケープ内の逆スラッシュの後の文字が,ASCII文字,b,t,n,f,r,",',\,0,1,2,3,4,5,6 及び 7でなければ,コンパイル時エラーとする。Unicodeエスケープ \uは,初期の段階(3.3)で処理される。(8進数によるエスケープは,C言語との互換性を保つために提供されているが,\u0000 から \u00FF までのUnicode値だけしか表現できないので,Unicodeエスケープのほうが, 普通は望ましい。)
3.10.7 空リテラル
空型は,ただ一つの値,空参照をもつ。空参照はASCII文字で構成され,リテラル null によって表現される。空リテラル(null literal) は常に空型とする。
NullLiteral:
null
3.11 分離子
次の9個のASCII文字を, Java 分離子(separators) (句読点)とする。
Separator: one of
( ) { } [ ] ; ,
3.12 演算子
次の37個のトークンを,Java 演算子(operators)とする。演算子は, ASCII 文字によって形成する。
Operator: one of
= > < ! ~ ? :
== <= >= != && || ++ --
+ - * / & | ^ % << >> >>>
+= -= *= /= &= |= ^= %= <<= >>= >>>=
目次 | 前 | 次